
Lagra datauppsättningar
Du kan lagra datauppsättningar med hjälp av en dataarbetsuppgift för lagring. Dataarbetsuppgiften för lagring använder data som har mellanlagrats i mellanlagringsområdet i molnet av en dataarbetsuppgift för lagring. Du kan till exempel använda tabellerna i en analysapplikation.
-
Du kan utforma en dataarbetsuppgift för lagring när statusen för dataarbetsuppgift för mellanlagring åtminstone är Redo att förbereda.
-
Du kan förbereda en dataarbetsuppgift för lagring när statusen för dataarbetsuppgiften för mellanlagring åtminstone är Klar att köra.
Dataarbetsuppgiften för lagring kommer att använda samma driftläge (Fullständig laddning eller Fullständig laddning och CDC) som den förbrukade dataarbetsuppgiften för mellanlagring. Konfigurationsegenskaperna skiljer sig mellan de två driftlägena, liksom alternativen för övervakning och kontroll. Om du använder en dataarbetsuppgift för mellanlagring i molnet med endast fullständig laddning kommer dataarbetsuppgiften för lagring att skapa vyer av tabeller för mellanlagring istället för att generera fysiska tabeller.
Förutom att lagra tabeller i datalagret kan du också lagra tabeller som Iceberg-tabeller som hanteras av dataplattformen. Detta alternativ är för närvarande endast tillgängligt för Snowflake-projekt. Detta är möjligt genom att välja Snowflake-hanterade Iceberg-tabeller under Tabelltyp i uppgiftsinställningarna.
Skapa en dataarbetsuppgift för lagring
Du kan skapa en dataarbetsuppgift för lagring på tre sätt:
-
Klicka på ... på en dataarbetsuppgift för mellanlagring och välj Lagra data för att skapa en dataarbetsuppgift för lagring basera på denna datatillgången för mellanlagring.
-
I ett pipelineprojekt klickar du på Skapa och sedan på Lagra data. I det här fallet måste du ange vilken dataarbetsuppgift för mellanlagring som ska användas.
-
När du lägger in data skapas en dataarbetsuppgift för lagring. Den är kopplad till mellanlagringsdatauppgiften som också skapas när du lägger in data.
Mer information finns i Introduktion av data till ett datalager.
När du har skapat dataarbetsuppgiften för lagring:
-
Öppna dataarbetsuppgiften för lagring genom att klicka på ... och välja Öppna.
Dataarbetsuppgiften för lagring öppnas och du kan förhandsgranska de utgående datauppsättningar som baseras på tabellerna från datatillgången för mellanlagring. -
Gör alla nödvändiga ändringar i de inkluderade datauppsättningarna, t.ex. omvandlingar, filtrering av data eller tillägg av kolumner.
Mer information finns i Hantera datauppsättningar.
-
När du har lagt till de omvandlingar du vill ha kan du validera datauppsättningarna genom att klicka på Validate datasets. Om fel hittas vid valideringen åtgärdar du felen innan du fortsätter.
Mer information finns i Validera och justera datauppsättningarna.
-
Skapa en datamodell
Klicka på Model för att ställa in relationerna mellan de inkluderade datauppsättningarna.
Mer information finns i Skapa en datamodell.
-
Klicka på Förbered för att förbereda dataarbetsuppgiften och alla nödvändiga artefakter. Detta kan ta lite tid.
Du kan följa förloppet under Förlopp för förberedelse på skärmens nedre del.
-
När statusen visar Klar att köra kan du köra dataarbetsuppgiften.
Klicka på Kör.
Dataarbetsuppgiften börjar nu skapa datauppsättningar för att lagra data.
Bevara historiska data
Du kan bevara historiska ändringsdata av typ 2 så att du enkelt kan återskapa data som de såg ut vid en viss tidpunkt. Detta skapar en fullständig historisk datalagringsplats (HDS).
-
Långsamt förändrade dimensioner av typ 2 stöds.
-
När en ändrad post slås samman, skapar den en ny post för att lagra ändrad data och lämna den gamla posten intakt.
-
Nya HDS-poster tidsmarkeras automatiskt, för att låta dig skapa trendanalyser och andra tidsorienterade datamartsanalyser.
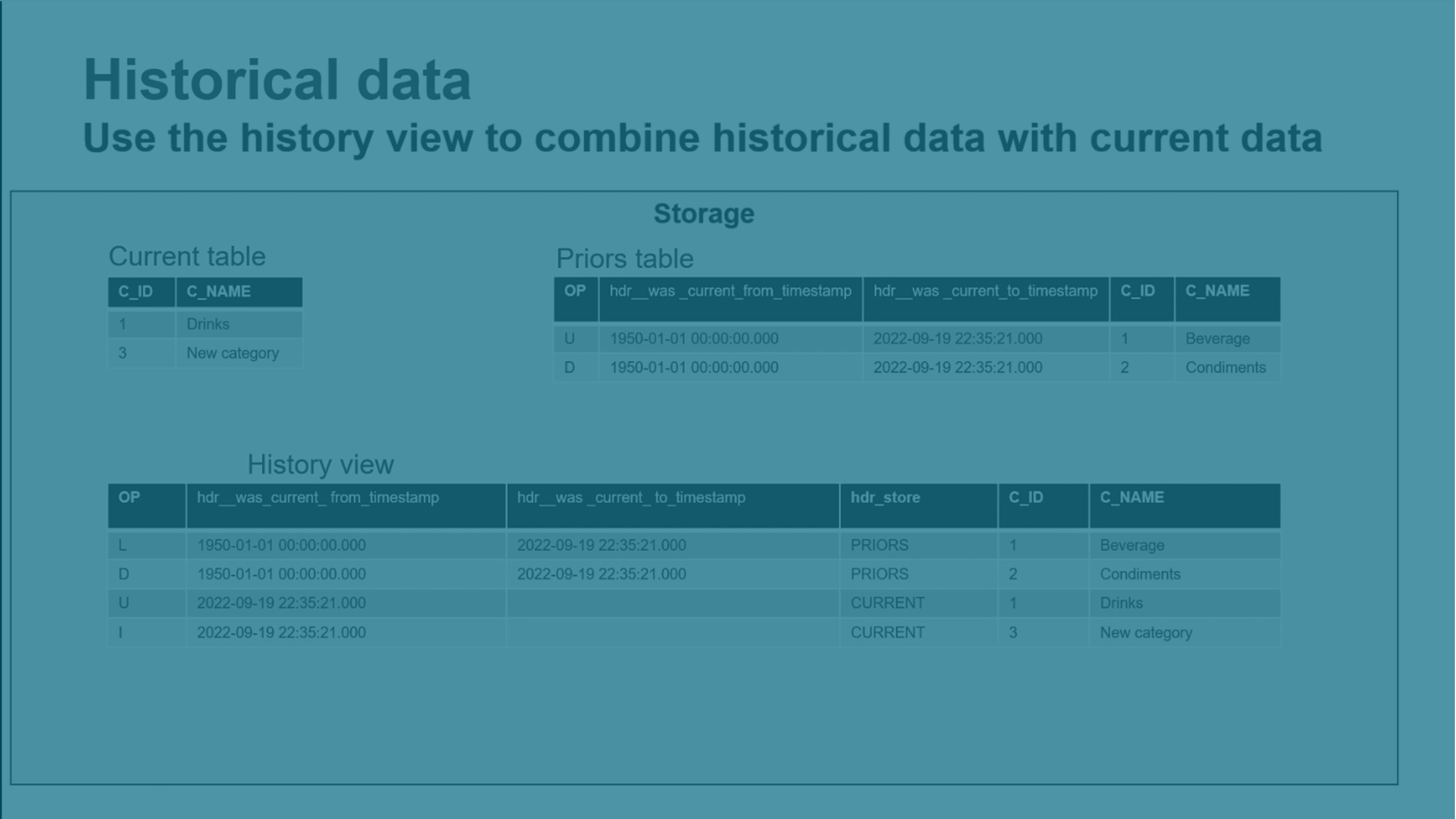
Du kan aktivera historiska data genom att klicka på:
-
Replikering med både aktuella data och historik över tidigare data i Inställningar när du lägger in data.
-
Behåll historiska ändringsposter och ändra arkivet med poster i dialogrutan Inställningar för en lagringsarbetsuppgift.
HDS-data lagras i tabellen Tidigare i det interna dataschemat. Du kan använda historikvyer och livehistorikvyer för att visa historiska data.
-
Historikvyn slår ihop data från tabellen Aktuella och tabellen Tidigare Vyn inkluderar alla ändringar som slagits samman.
-
Historikvyn slår ihop data från tabellerna Aktuella, Tidigare och Ändringar. Vyn inkluderar alla ändringar som ännu inte slagits samman.
Mer information finns i Datamängdsarkitektur i ett molndatalager.
Lagring
Schemalägga en lagringsuppgift
Du kan schemalägga en lagringsuppgift så att den uppdateras regelbundet.
-
Om indatauppgiften för mellanlagring använder Fullständig laddning och CDC kan du bara ställa in ett tidsbaserat schema.
-
Om indatauppgiften för mellanlagring använderFullständig laddning kan du antingen ställa in ett tidsbaserat schema, eller ställa in uppgiften till att köras när indatauppgiften för mellanlagring har slutförts.
Anteckning om informationNär du kör ett tidsbaserat schema med en indatauppgift för mellanlagring med Fullständig laddning bör du ha i åtanke att alla slutförda tabeller i mellanlagringen är tillgängliga när mellanlagringsuppgiften fortfarande körs. Därför kan du köra mellanlagring och lagring samtidigt, vilket kan förkorta den sammanlagda laddningstiden. -
Om projektet lagrar data i Iceberg-tabeller kan du ställa in ett tidsbaserat schema eller ställa in aktiviteten så att den körs när en partition för ändringsdata stängs.
Klicka på … på en datauppgift och välj Schemaläggning för att skapa ett schema. Standardinställningen för schemaläggning ärvs från inställningarna i pipelineprojektet. Mer information om standardinställningar finns i Standardvärden för lagring. Du måste alltid sätta Schemaläggning till På för att aktivera schemat.
Tidsbaserade scheman
Du kan använda ett tidsbaserat schema för att köra lagringsdatauppgiften oavsett typ av mellanlagring.
-
Välj Vid en specifik tidpunkt i Kör datauppgift.
Du kan skapa ett schema med intervall på dagar, veckor eller månader.
Händelsebaserade scheman
-
Välj När en indatauppgift har slutförts i Kör datauppgiften.
Lagringsuppgiften körs varje gång indatauppgiften för mellanlagring har slutförts.
Övervakning av en lagringsuppgift
Du kan övervaka statusen och förloppet för en lagringsuppgift genom att klicka på Monitor.
Mer information finns i Övervaka en enskild datauppgift.
Felsöka en lagringsdatauppgift
När det är problem med en eller flera tabeller i en lagringsdatauppgift kan du behöva ladda eller återskapa data. Det finns ett antal tillgängliga alternativ för att utföra detta. Avgör vilket alternativ som är lämpligast i följande ordning:
-
Du kan ladda datauppsättningen i mellanlagring. När en datauppsättning läses in igen i mellanlagring kommer detta att sätta igång jämförelseprocessen i lagringsutrymmet och korrigera data, samtidigt som typ 2-historiken bevaras. Det här alternativet bör också övervägas när:
-
Den fullständiga laddningen gjordes för länge sedan och det finns ett stort antal ändringar.
-
Om fullständig laddning och ändrade tabellposter som har bearbetats har tagits bort som en del i underhållet av området för mellanlagring.
-
-
Du kan ladda data i lagringsdatauppgiften.
Om historiska data är aktiverade kan en inläsning igen i lagringsutrymmet orsaka att historiska data går förlorade. Om detta är ett problem bör du överväga att ladda mellanlagringen från källan i stället.
-
Du kan återskapa tabeller. Detta återskapar datauppsättningarna från källan.
-
Klicka på … och klicka sedan på Återskapa tabeller. När en tabell återskapas reagerar uppgiften nedströms som om en trunkera- och återskapa-åtgärd utförts på källdatauppsättningarna.
Anteckning om informationOm det uppstår problem med enskilda tabeller rekommenderas du att först försöka läsa in tabellerna igen istället för att återskapa dem. Om du återskapar tabeller kan detta leda till att historiska data förloras. Om det sker stora förändringar måste du också förbereda datauppgifter nedströms som använder de återskapade datauppgifterna för att ladda data på nytt.
-
Ladda data
Du kan utföra en manuell omladdning av data. Detta är användbart när det finns problem med en eller flera tabeller.
-
Öppna datauppgiften och välj fliken Övervaka.
-
Välj tabellerna du vill ladda.
-
Klicka på Ladda tabeller.
Laddningen sker nästa gång uppgiften körs och utförs av:
-
Trunkera tabellerna.
-
Ladda mellanlagringsdata i tabellerna.
-
Ladda ändringarna som ackumulerats från laddningstiden.
I allmänhet är det lämpligast att ladda datauppsättningen i mellanlagringen i stället. Detta gäller i synnerhet i följande fall:
-
Om historiska data är aktiverade kan en inläsning igen i lagringsutrymmet orsaka att historiska data går förlorade. När en datauppsättning läses in igen i mellanlagring kommer detta att sätta igång jämförelseprocessen i lagringsutrymmet och korrigera databevarande typ 2- historik.
-
När fullständig laddning gjordes för länge sedan och det finns ett stort antal ändringar.
-
Om fullständig laddning och ändrade tabellposter som har bearbetats har tagits bort som en del i underhållet av området för mellanlagring.
Uppgifter nedströms laddas för att ändringar ska tillämpas och antedatering undvikas. Om en laddning utförs genom att trunkera och ladda kommer alla objekt nedströms också att laddas genom att trunkera och ladda.
Påverkan nedströms efter laddning av en mellanlagrings- eller lagringsdatauppgift

Påverkan nedströms beror på typen av utförd laddningsåtgärd och typ av datauppsättning omedelbart nedströms. Standardbearbetning innebär att datauppsättningen kommer att reagera och bearbeta data med den konfigurerade metoden för den specifika datauppsättningen.
-
I omvandlingsuppgifter nedströms:
Transformering av datauppsättningar laddas genom trunkering och laddning.
SQL-transformeringar och transformeringsflöden laddas genom att jämföra med fullständig laddning och tillämpa ändringar.
-
Datamartuppgifter omedelbart efter en lagringsuppgift laddas genom att trunkera och ladda.
Du kan avbryta laddningen för tabeller som väntar på laddning genom att klicka på Avbryt laddning. Detta kommer inte att påverka tabeller som redan har laddats och laddningar som körs för tillfället kommer att slutföras.
Utveckling av schema
Med Schemautveckling kan du enkelt kan upptäcka strukturella förändringar i flera datakällor och sedan styra hur dessa förändringar kommer att tillämpas på din uppgift. Schemautveckling kan användas för att upptäcka alla DDL-ändringar som gjorts i källdataschemat. Du kan också tillämpa vissa ändringar automatiskt.
För varje ändringstyp kan du välja hur du vill hantera ändringarna i avsnittet Schemautveckling i uppgiftsinställningarna. Du kan antingen tillämpa ändringen, ignorera ändringen, avbryta tabellen eller stoppa behandlingen av uppgiften.
Du kan ange vilken åtgärd som ska användas för att hantera DDL-ändringen för varje ändringstyp. Vissa åtgärder är inte tillgängliga för alla ändringstyper.
-
Tillämpa på mål
Tillämpa ändringar automatiskt.
-
Ignorera
Ignorera ändringar.
-
Inaktivera tabell
Inaktivera tabellen. Tabellen kommer att visas som fel i Övervakaren.
-
Stoppa uppgift
Stoppa bearbetningen av uppgiften. Detta är användbart om du vill hantera alla schemaförändringar manuellt. Detta stoppar också schemaläggningen, det vill säga att schemalagda körningar inte kommer att utföras.
Följande ändringar stöds:
-
Lägg till kolumn
-
Skapa en tabell som matchar urvalsmönstret
Om du använde en Urvalsregel för att lägga till datauppsättningar som matchar ett mönster kommer nya tabeller som uppfyller mönstret att upptäckas och läggas till.
Se Utveckling av schema för mer information om uppgiftsinställningar
Begränsningar för schemautveckling
Följande begränsningar gäller för schemautveckling:
-
Schemautveckling stöds endast när CDC används som uppdateringsmetod.
-
När du har ändrat inställningarna för schemautveckling måste du förbereda uppgiften på nytt.
-
Om du byter namn på tabeller stöds inte schemautveckling. I så fall måste du uppdatera metadata innan du förbereder uppgiften.
-
Om du håller på att utforma en uppgift måste du uppdatera webbläsaren för att ta emot ändringar i schemautvecklingen. Du kan ställa in aviseringar för att få information om ändringar.
-
Det går inte att ta bort kolumner i mellanlagringsuppgifter. Om du tar bort en kolumn och lägger till den kommer det att resultera i ett tabellfel.
-
I mellanlagringsuppgifter går det inte att ta bort en tabell med åtgärden ta bort tabell. Om du tar bort en tabell och sedan lägger till en tabell kommer den gamla tabellen bara att trunkeras, och en ny tabell kommer inte att läggas till.
-
Det är inte möjligt att ändra längden på en kolumn för alla mål beroende på stödet i måldatabasen.
-
Om ett kolumnnamn ändras kommer explicita transformeringar som definieras med hjälp av den kolumnen inte att påverkas eftersom de baseras på kolumnnamnet.
-
Begränsningarna för uppdatering av metadata gäller även för schemautveckling.
-
Om en uppgift innehåller designändringar som ännu inte har förberetts och källschemats evolutionsändringar upptäcks när uppgiften körs, kommer uppgiften att stoppas för att undvika konflikter. Förbered de väntande designändringarna och kör uppgiften igen.
När DDL-ändringar registreras gäller följande begränsningar:
-
När en snabb sekvens av åtgärder inträffar i källdatabasen (t.ex. DDL>DML>DDL) kan Qlik Talend Data Integration analysera loggen i fel ordning, vilket kan leda till att data saknas eller till ett oförutsägbart beteende. För att minimera risken för att detta ska hända är bästa praxis att vänta på att ändringarna ska tillämpas på målet innan du utför nästa åtgärd.
Ett exempel vid registrering av ändringar är att om en källtabell byter namn flera gånger i snabb följd (och den andra åtgärden byter tillbaka till det ursprungliga namnet), kan det uppstå ett felmeddelande om att tabellen redan finns i måldatabasen.
- Om du ändrar namnet på en tabell som används i en uppgift och sedan stoppar uppgiften, kommer Qlik Talend Data Integration inte att fånga upp några ändringar som görs i den tabellen när uppgiften återupptas.
-
Det går inte att byta namn på en källtabell medan en uppgift stoppas.
- Omallokering av en tabells Primary Key-kolumner stöds inte (och kommer därför inte att skrivas till kontrolltabellen för DDL-historik).
- När en kolumns datatyp ändras och (samma) kolumn sedan byter namn medan aktiviteten stoppas, kommer DDL-ändringen att visas i kontrolltabellen DDL-historik som "Drop Column" och sedan "Add Column" när aktiviteten återupptas. Observera att samma beteende också kan uppstå som ett resultat av förlängd latens.
- CREATE TABLE-åtgärder som utförs på källan medan en uppgift stoppas kommer att tillämpas på målet när uppgiften återupptas, men kommer inte att registreras som en DDL i kontrolltabellen DDL-historik.
-
Åtgärder som är förknippade med metadataändringar (t.ex. ALTER TABLE, reorg, återuppbyggnad av ett klustrat index osv.) kan orsaka oförutsägbart beteende om de utförs antingen
-
Under fullständig laddning
-ELLER-
-
Mellan tidsmarkören för Börja bearbeta ändringar och aktuell tid (dvs. det ögonblick då användaren klickar på OK i dialogrutan Avancerade körningsalternativ ).
Exempel:
OM:
Den angivna tiden för Börja bearbeta ändringar är 10.00.
OCH:
En kolumn med namnet Ålder lades till i tabellen Medarbetare kl. 10.10.
OCH:
Användaren klickar på OK i dialogrutan Avancerade körningsalternativ kl. 10.15.
SEDAN:
Ändringar som inträffade mellan 10.00 och 10.10 kan leda till CDC-fel.
Anteckning om informationI något av ovanstående fall måste den eller de berörda tabellerna laddas om för att data ska kunna skickas korrekt flyttad till målet.
-
- DDL-satsen
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>replikerar inte standardvärdet till målet och den nya/modifierade kolumnen sätts till NULL. Observera att detta kan hända även om den DDL som lade till/ändrade kolumnen kördes tidigare. Om den nya/ändrade kolumnen är nullable, uppdaterar källans slutpunkt alla tabellrader innan DDL:n loggas. Därför fångar Qlik Talend Data Integration upp ändringarna, men uppdaterar inte målet. Eftersom den nya/ändrade kolumnen är inställd på NULL kommer efterföljande uppdateringar att generera ett meddelande om att "noll rader påverkas", om måltabellen inte har något Primary Key/Unique-index. -
Ändringar i precisionskolumnerna TIDSMARKÖR och DATUM kommer inte att registreras.
Visa uppgiftsinformation
Klicka på ![]() i menyraden för att visa uppgiftsinformation, till exempel:
i menyraden för att visa uppgiftsinformation, till exempel:
-
Ägare
-
Utrymme
-
Dataplattform
-
Projekt-id
-
Körnings-ID för datauppgift
Lagringsinställningar
Du kan ställa in egenskaper för dataarbetsuppgiften för lagring när dataplattformen är ett molndatalager. Om du använder Qlik Cloud som dataplattform, se Lagringsinställningar för dataprojekt med Qlik Cloud som dataplattform.
-
Klicka på Inställningar.
Allmänna inställningar
-
Databas
Databas som ska användas i datakällan.
-
Uppgiftsschema
Du kan byta namn på schemat för datalagringsuppgiften. Standardnamnet är namnet på lagringsuppgiften.
-
Internt schema
Du kan ändra namnet på datatillgångsschemat för intern lagring. Standardnamnet är namnet på lagringsuppgiften med _internal som tillägg.
-
Standardversalisering av schemanamn
Du kan ange standardversalisering för alla schemanamn. Om din databas är konfigurerad för att tvinga fram versalisering kommer detta alternativ inte att ha någon effekt.
- Prefix för alla tabeller och vyer
Du kan ange prefix för alla tabeller och vyer som skapas av uppgiften.
Anteckning om informationDu måste använda ett unikt prefix om du vill använda ett databasschema i flera datauppgifter. -
Historik
Du kan behålla historiska ändringsdata så att du enkelt kan återskapa data så som de såg ut vid en viss tidpunkt. Du kan använda historiska vyer och historiska livevyer för att se historiska data. Välj Keep historical records and archive of change records för att aktivera historiska ändringsdata.
-
När du jämför lagring med mellanlagring kan du välja hur du ska hantera poster som inte finns i mellanlagringen.
-
Markera som raderad
Detta kommer att göra en mjuk radering av poster som inte finns i mellanlagringen.
-
Behåll
På så sätt behålls alla poster som inte finns i mellanlagringen.
Anteckning om informationDatauppsättningar i dataarbetsuppgifter för lagring måste ha en primärnyckel inställd. Om så inte är fallet kommer en första inläsning att utföras på dataarbetsuppgiften för lagring varje gång mellanlagringsdata läses in. -
-
Publicera i katalogen
Välj det här alternativet för att publicera den här versionen av data till Katalogen som en datauppsättning. Kataloginnehållet kommer att uppdateras nästa gång du förbereder den här uppgiften.
Mer information om Katalog finns i Förstå data med hjälp av katalogverktyg.
Inställningar för vyer
-
Livevyer
Använd livevyer för läsning av tabeller med minst fördröjning.
Mer information om livevyer finns i Använda livevyer.
Anteckning om informationLivevyer är mindre effektiva än standardvyer och kräver mer resurser, eftersom tillämpade data måste beräknas om.
Inställningar för typ av vy
Inställningen för typ av vy gäller endast för Snowflake.
-
Standardvyer
Använd standardvyer för de flesta fall.
-
Snowflake säkra vyer
Använd säkra vyer i Snowflake för vyer som är avsedda för skydd av dataintegritet eller känslig information, t.ex. vyer som skapats för att begränsa åtkomsten till känsliga data som inte bör exponeras för alla användare av de underliggande datatabellerna.
Anteckning om information Snowflake säkra vyer kan köras långsammare än standardvyer.
Inställningar för körtid
-
Parallell körning
Du kan ställa in det maximala antalet kopplingar för fullständig laddning till ett tal mellan 1 och 5.
-
Lager
Namnet på molndatalagret. Den här inställningen gäller endast för Snowflake.
Tabelltypsinställningar
Dessa inställningar är endast tillgängliga i projekt med Snowflake som dataplattform.
-
Tabelltyp
Du kan välja vilken typ av tabell som ska användas:
-
Snowflake-tabeller
-
Iceberg-tabeller som hanteras av Snowflake
Du måste ange standardnamnet på den externa volymen i Snowflake external volume.
-
-
Mapp att använda i molnet
Välj vilken mapp som ska användas när data mellanlagras i mellanlagringsområdet.
-
Standardmapp
Detta skapar en mapp med standardnamnet: <projektnamn>/<datauppgiftens namn>.
-
Rotmapp
Lagra data i lagringens rotmapp.
-
Mapp
Ange namnet på mappen som ska användas.
-
-
Synka med Snowflake Open Catalog
Aktivera detta för att låta Snowflake Open Catalog hantera filerna i fillagringen i molnet.
Utveckling av schema
Välj hur du ska hantera följande typer av DDL-ändringar i schemat. När du har ändrat inställningarna för schemautveckling måste du förbereda uppgiften på nytt. I tabellen nedan beskrivs vilka åtgärder som är tillgängliga för de DDL-ändringar som stöds.
| Förändring av DDL | Tillämpa på mål | Ignorera | Stoppa uppgift |
|---|---|---|---|
| Lägg till kolumn | Ja | Ja | Ja |
| Skapa tabell
Om du använde en Urvalsregel för att lägga till datauppsättningar som matchar ett mönster kommer nya tabeller som uppfyller mönstret att upptäckas och läggas till. |
Ja | Ja | Ja |
Lagringsinställningar för dataprojekt med Qlik Cloud som dataplattform
Du kan ange vilken mapp som ska användas i lagret när dataplattformen är Qlik Cloud som dataplattform.
-
Klicka på Inställningar.
-
Välj den mapp som ska användas för lagring.
-
Klicka på OK när du är klar.
Åtgärder för datalagringsuppgiften
Du kan utföra följande åtgärder på en datalagringsuppgift från uppgiftsmenyn.
-
Öppna
Detta öppnar datalagringsuppgiften. Du kan visa tabellvyn och information om dataarbetsuppgiften, och övervaka statusen för den fullständiga laddningen och batcher med ändringar.
-
Redigera
Du kan redigera arbetsuppgiftens namn och beskrivning och lägga till taggar.
-
Ta bort
Du kan ta bort datauppgiften om den inte körs och det inte finns några beroenden till efterföljande uppgifter i samma projekt.
-
I projektvyn Pipelineprojekt klickar du på
 på en uppgift och väljer Ta bort.
på en uppgift och väljer Ta bort.
Artefakter (tabeller och vyer) som skapats av uppgiften kommer också att tas bort, om du inte väljer att behålla dem.
Anteckning om informationTänk på att de artefakter du behåller inte längre kommer att uppdateras av uppgiften. -
-
Förbereda
Detta förbereder en uppgift för utförande. Detta inkluderar följande:
-
Validering av att designen är giltig.
-
Skapande eller ändring av de fysiska tabellerna och vyerna så att de stämmer överens med designen.
-
Generering av SQL-koden för datauppgiften
-
Skapande eller ändring av katalogposterna för uppgiftens utgående datauppsättningar.
Du kan följa förloppet under Förlopp för förberedelse på skärmens nedre del.
-
-
Validera datauppsättningar
Detta validerar alla datauppsättningar som ingår i dataarbetsuppgiften.
Expandera Validera och justera för att visa alla valideringsfel och designändringar.
-
Återskapa tabeller
Detta återskapar datauppsättningarna från källan. När en tabell återskapas reagerar uppgiften nedströms som om en trunkera- och återskapa-åtgärd utförts på källdatauppsättningarna. Mer information finns i Felsöka en lagringsdatauppgift.
-
Stoppa
Du kan stoppa åtgärden för dataarbetsuppgiften. Datauppgiften kommer inte att fortsätta att uppdatera tabellerna.
Anteckning om informationDet här alternativet är tillgängligt när dataarbetsuppgiften körs. -
Återuppta
Du kan återuppta åtgärden för en dataarbetsuppgift från den punkt där den stoppades.
Anteckning om informationDet här alternativet är tillgängligt när dataarbetsuppgiften är stoppad. -
Omvandla data
Skapa återanvändbara omvandlingar på radnivå baserat på regler och anpassad SQL. Detta skapar en Transform-dataarbetsuppgift.
-
Skapa datamart
Skapa en datamart för att utnyttja dina dataarbetsuppgifter. Detta skapar en Data mart-dataarbetsuppgift.
Begränsningar
-
Om dataarbetsuppgiften innehåller datauppsättningar och du ändrar parametrar i anslutningen, till exempel användarnamn, databas eller schema, antas det att data finns på den nya platsen. Om så inte är fallet kan du antingen:
-
Flytta data i källan till den nya platsen.
-
Skapa en ny dataarbetsuppgift med samma inställningar.
-
-
Det är inte möjligt att ändra primärnycklar i lagringsuppgifter i projekt med Qlik Cloud (QVD) som mål. Uppdatera primärnycklarna i mellanlagringsuppgiften, återskapa mellanlagringsuppgiften och återskapa sedan lagringsuppgiften.
-
När Iceberg-lagring används, kommer JSON-datakolumner att lagras som STRING.