
Speichern von Datensätzen
Sie können Datensätze mit einer Speicherdatenaufgabe speichern. Die Speicherdatenaufgabe nutzt die Daten, die für den Cloud-Bereitstellungsbereich von einer Bereitstellungsdatenaufgabe bereitgestellt wurden. Sie können die Tabellen z. B. in einer Analyseanwendung verwenden.
-
Sie können eine Speicherdatenaufgabe entwerfen, wenn der Status der Bereitstellungsdatenaufgabe mindestens Zur Vorbereitung bereit ist.
-
Sie können eine Speicherdatenaufgabe vorbereiten, wenn der Status der Bereitstellungsdatenaufgabe mindestens Zur Ausführung bereit ist.
Die Speicherdatenaufgabe verwendet den gleichen Vorgangsmodus (Vollständiges Laden oder Vollständiges Laden und CDC) wie die genutzte Bereitstellungsdatenaufgabe. Die Konfigurationseigenschaften, die Überwachungs- und die Steueroptionen sind für die beiden Vorgangsmodi unterschiedlich. Wenn Sie eine Cloud-Ziel-Bereitstellungsdatenaufgabe mit nur vollständigem Laden verwenden, erstellt die Speicherdatenaufgabe Ansichten für die Bereitstellungstabellen anstelle von physischen Tabellen.
Zusätzlich zum Speichern von Tabellen im Data Warehouse können Sie Tabellen auch als Iceberg-Tabellen speichern, die von der Datenplattform verwaltet werden. Diese Option ist derzeit nur bei Snowflake-Projekten verfügbar. Wählen Sie hierzu in den Aufgabeneinstellungen unter Tabellentyp die Option Von Snowflake verwaltete Iceberg-Tabellen aus.
Erstellen einer Speicherdatenaufgabe
Sie können eine Speicherdatenaufgabe auf drei Weisen erstellen:
-
Klicken Sie für eine Speicherdatenaufgabe auf ... und wählen Sie Daten speichern aus, um eine Speicherdatenaufgabe basierend auf dieser Bereitstellungsdatenaufgabe zu erstellen.
-
Klicken Sie in einem Pipeline-Projekt auf Erstellen und dann auf Daten speichern. In diesem Fall müssen Sie angeben, welche Bereitstellungsdatenaufgabe verwendet werden soll.
-
Wenn Sie Daten eingliedern, wird eine Speicherdatenaufgabe erstellt. Sie wird mit der Bereitstellungsdatenaufgabe verbunden, die ebenfalls erstellt wird, wenn Daten eingegliedert werden.
Weitere Informationen finden Sie unter Eingliedern von Daten in einem Data Warehouse.
Wenn Sie die Speicherdatenaufgabe erstellt haben:
-
Öffnen Sie die Speicherdatenaufgabe, indem Sie auf ... klicken und Öffnen auswählen.
Die Speicherdatenaufgabe wird geöffnet, und Sie können eine Vorschau der Ausgabedatensätze anzeigen, die auf den Tabellen aus dem Bereitstellungsdatenobjekt basieren. -
Nehmen Sie alle notwendigen Änderungen an den inbegriffenen Datasets wie beispielsweise Transformationen, Filtern von Daten oder Hinzufügen von Spalten vor.
Weitere Informationen finden Sie unter Verwalten von Datensätzen.
-
Wenn Sie die gewünschten Transformationen hinzugefügt haben, können Sie die Datasets validieren, indem Sie auf Datensätze validieren klicken. Falls bei der Validierung Fehler gefunden werden, beheben Sie diese, bevor Sie fortfahren.
Weitere Informationen finden Sie unter Validieren und Anpassen der Datensätze.
-
Datenmodell erstellen
Klicken Sie auf Modell, um die Beziehungen zwischen den enthaltenen Datasets festzulegen.
Weitere Informationen finden Sie unter Erstellung eines Datenmodells.
-
Klicken Sie auf Vorbereiten, um die Datenaufgabe und alle erforderlichen Artefakte vorzubereiten. Dies kann eine Weile dauern.
Sie können den Fortschritt unter Vorbereitungsfortschritt unten im Bildschirm verfolgen.
-
Wenn der Status Zur Ausführung bereit anzeigt, können Sie die Datenaufgabe ausführen.
Klicken Sie auf Ausführen.
Die Datenaufgabe beginnt nun mit der Erstellung von Datensätzen, um die Daten zu speichern.
Beibehalten von Verlaufsdaten
Sie können Verlaufsänderungsdaten des Typs 2 beibehalten, um Daten leicht neu so erstellen zu können, wie sie zu einem bestimmten Zeitpunkt aussahen. Damit wird auch ein vollständiger Verlaufsdatenspeicher (HDS) generiert.
-
Sich langsam ändernde Dimensionen des Typs 2 werden unterstützt.
-
Wenn ein geänderter Datensatz zusammengeführt wird, erstellt er einen neuen Datensatz zum Speichern der geänderten Daten und lässt den alten Datensatz unverändert.
-
Neue HDS-Datensätze werden automatisch mit Zeitstempel versehen, damit Sie eine Trendanalyse und andere zeitbezogene analytische Data Marts erstellen können.
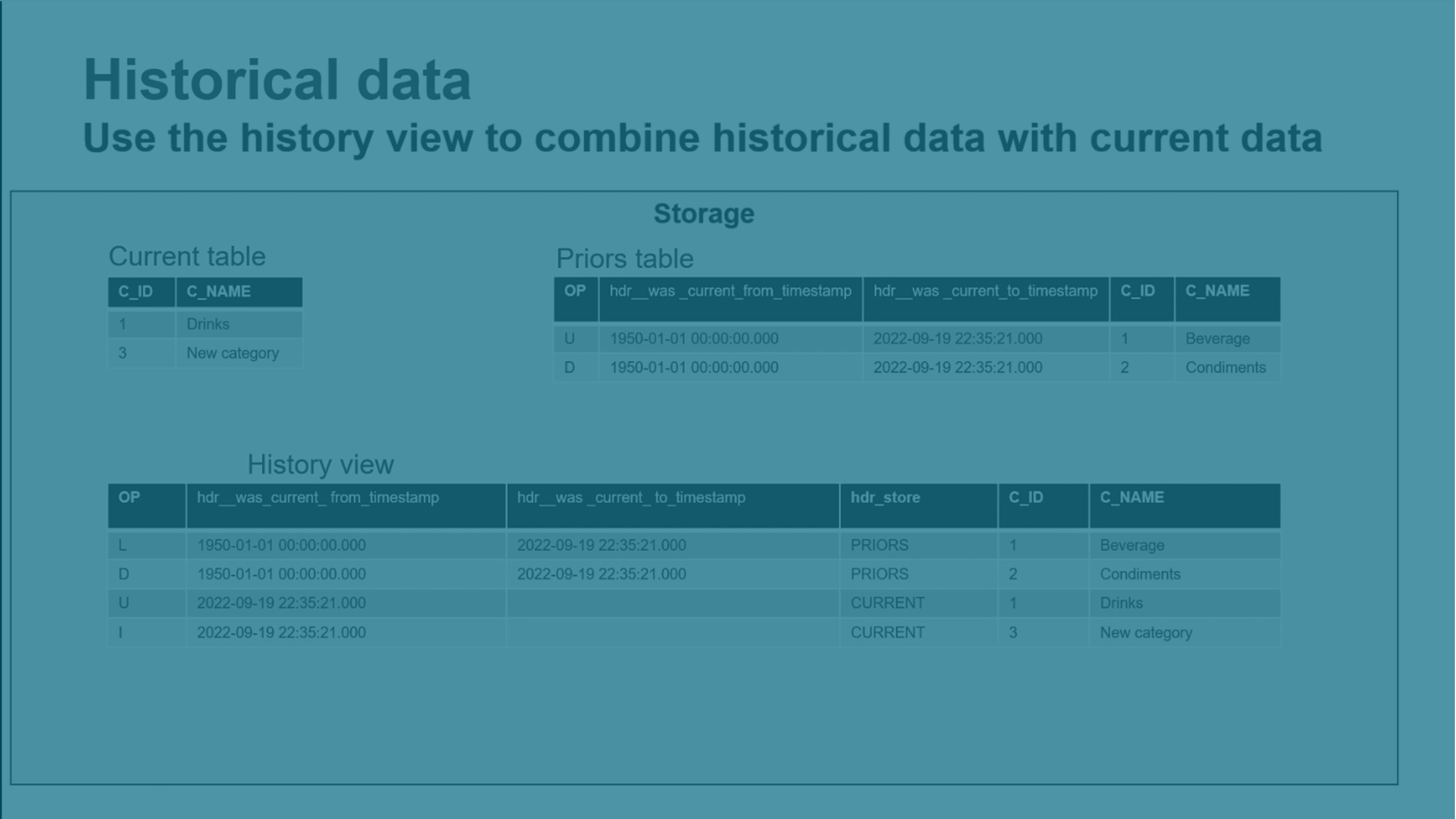
Sie können Verlaufsdaten aktivieren, indem Sie Folgendes anklicken:
-
Replikation sowohl mit aktuellen Daten als auch mit vorherigen Verlaufsdaten in Einstellungen, wenn Sie Daten eingliedern.
-
Verlaufsdatensätze beibehalten und Datensatzarchiv ändern im Dialogfeld Einstellungen einer Speicheraufgabe.
HDS-Daten werden in der Tabelle „Prior“ im internen Datenschema gespeichert. Sie können die Verlaufsansichten und Live-Verlaufsansichten im externen Datenschema verwenden, um die Verlaufsdaten anzuzeigen.
-
In der Verlaufsansicht werden Daten aus der Tabelle „Current“ und der Tabelle „Prior“ zusammengeführt. Diese Ansicht enthält alle zusammengeführten Änderungen.
-
In der Live-Verlaufsansicht werden Daten aus der Tabelle „Current“, der Tabelle „Prior“ und der Tabelle „Changes“ zusammengeführt. Diese Ansicht enthält also auch alle noch nicht zusammengeführten Änderungen.
Weitere Informationen finden Sie unter Dataset-Architektur in einem Cloud Data Warehouse.
Speichern
Planen einer Speicheraufgabe
Sie können eine Speicheraufgabe planen, damit sie regelmäßig aktualisiert wird.
-
Wenn die Eingabe-Bereitstellungsdatenaufgabe Vollständiges Laden und CDC verwendet, können Sie nur einen zeitbasierten Plan festlegen.
-
Wenn die Eingabe-Bereitstellungsdatenaufgabe Vollständiges Laden verwendet, können Sie entweder einen zeitbasierten Plan festlegen oder definieren, dass die Aufgabe nach Abschluss der Eingabe-Bereitstellungsdatenaufgabe ausgeführt wird.
InformationshinweisWenn Sie einen zeitbasierten Plan mit einer Eingabe-Bereitstellungsdatenaufgabe mit Vollständiges Laden ausführen, beachten Sie, dass jede abgeschlossene Tabelle in der Bereitstellung verfügbar ist, während die Bereitstellungsaufgabe noch läuft. Damit können der Bereitstellungs- und der Speichervorgang gleichzeitig ausgeführt werden, was die Gesamtladezeit verkürzen kann. -
Wenn das Projekt Daten in Iceberg-Tabellen speichert, können Sie einen zeitbasierten Plan festlegen oder die Aufgabe so einstellen, dass sie ausgeführt wird, wenn eine Änderungsdatenpartition geschlossen wird.
Klicken Sie in einer Datenaufgabe auf ... und wählen Sie Planung aus, um einen Plan zu erstellen. Die Standardplanungseinstellung wird aus den Einstellungen im Pipeline-Projekt übernommen. Weitere Informationen zu Standardeinstellungen finden Sie unter Speicher-Standardeinstellungen. Sie müssen Planung immer auf Ein festlegen, um den Plan zu aktivieren.
Zeitbasierte Pläne
Sie können einen zeitbasierten Plan verwenden, um die Speicherdatenaufgabe unabhängig vom Bereitstellungstyp auszuführen.
-
Wählen Sie in Datenaufgabe ausführen die Option Zu einer bestimmten Uhrzeit aus.
Sie können einen stündlichen, täglichen, wöchentlichen oder monatlichen Plan erstellen.
Ereignisbasierte Pläne
-
Wählen Sie in Datenaufgabe ausführen die Option Bei erfolgreichem Abschluss einer Eingabedatenaufgabe aus.
Die Speicheraufgabe wird jedes Mal ausgeführt, wenn die Eingabe-Bereitstellungsdatenaufgabe erfolgreich abgeschlossen wurde.
Überwachen einer Speicheraufgabe
Sie können den Status und Fortschritt einer Speicheraufgabe überwachen, indem Sie auf Überwachen klicken.
Weitere Informationen finden Sie unter Überwachen einer einzelnen Datenaufgabe.
Fehlerbehebung für eine Speicherdatenaufgabe
Wenn Probleme mit einer oder mehreren Tabellen in einer Speicherdatenaufgabe vorliegen, müssen Sie möglicherweise die Daten neu laden oder neu erstellen. Dafür sind mehrere Optionen verfügbar. Erwägen Sie die verfügbaren Optionen in der folgenden Reihenfolge:
-
Sie können den Datensatz in der Bereitstellung neu laden. Das Laden des Datensatzes in der Bereitstellung löst den Vergleichsprozess im Speicher aus und korrigiert Daten, während der Typ-2-Verlauf beibehalten wird. Diese Option sollte auch in folgenden Fällen erwogen werden:
-
Wenn das vollständige Laden vor längerer Zeit erfolgte und sehr viele Änderungen vorhanden sind.
-
Wenn Datensätze für vollständiges Laden und Änderungstabellen, die verarbeitet wurden, im Rahmen der Wartung des Bereitstellungsbereichs gelöscht wurden.
-
-
Sie können Daten in der Speicherdatenaufgabe neu laden.
Wenn Verlaufsdaten aktiviert sind, kann ein Ladevorgang im Speicher zum Verlust von Verlaufsdaten führen. Wenn das ein Problem ist, können Sie stattdessen die Bereitstellung aus der Quelle neu laden.
-
Sie können Tabellen neu erstellen. Dadurch werden die Datasets von der Quelle neu erstellt.
-
Klicken Sie auf ... und dann auf Tabellen neu erstellen. Bei der Neuerstellung einer Tabelle reagiert die nachgelagerte Aufgabe so, als ob ein Ladevorgang mit Abschneiden und Neuladen für die Quelldatensätze aufgetreten wäre.
InformationshinweisWenn Probleme mit einzelnen Tabellen bestehen, wird empfohlen, die Tabellen zuerst neu zu laden, statt sie neu zu erstellen. Die Neuerstellung von Tabellen kann zum Verlust von Verlaufsdaten führen. Wenn kritische Änderungen vorliegen, müssen Sie auch nachgelagerte Datenaufgaben vorbereiten, die die neu erstellten Datenaufgaben nutzen, damit die Daten neu geladen werden.
-
Laden von Daten
Sie können einen manuellen Tabellenladevorgang ausführen. Das ist nützlich, wenn Probleme mit einer oder mehreren Tabellen vorliegen.
-
Öffnen Sie die Datenaufgabe und wählen Sie die Registerkarte Überwachen aus.
-
Wählen Sie die Tabellen aus, die Sie laden möchten.
-
Klicken Sie auf Tabellen laden.
Der Ladevorgang findet bei der nächsten Aufgabenausführung statt und wird wie folgt durchgeführt:
-
Die Tabellen werden abgeschnitten.
-
Die Bereitstellungsdaten werden in die Tabellen geladen.
-
Die ab dem Ladezeitpunkt angesammelten Änderungen werden geladen.
Im Allgemeinen sollte als Best Practice stattdessen der Datensatz bei der Bereitstellung neu geladen werden. Dies gilt insbesondere für die folgenden Fälle:
-
Wenn Verlaufsdaten aktiviert sind, kann ein Ladevorgang im Speicher zum Verlust von Verlaufsdaten führen. Das Laden des Datensatzes in der Bereitstellung löst den Vergleichsprozess im Speicher aus und korrigiert Daten, während der Typ-2-Verlauf beibehalten wird.
-
Wenn das vollständige Laden vor längerer Zeit erfolgte und sehr viele Änderungen vorhanden sind.
-
Wenn Datensätze für vollständiges Laden und Änderungstabellen, die verarbeitet wurden, im Rahmen der Wartung des Bereitstellungsbereichs gelöscht wurden.
Nachgelagerte Aufgaben werden neu geladen, um Änderungen anzuwenden und Rückdatierung zu vermeiden. Wenn ein Ladevorgang mit Abschneiden und Neuladen durchgeführt wird, werden alle nachgelagerten Objekte ebenfalls durch Abschneiden und Neuladen geladen.
Auswirkung auf nachgelagerte Objekte nach dem erneuten Laden einer Bereitstellungs- oder Speicherdatenaufgabe

Die Auswirkung auf nachgelagerte Objekte hängt vom Typ des durchgeführten Ladevorgangs und vom Typ des unmittelbar nachgelagerten Datensatzes ab. Standardverarbeitung bedeutet, dass der Datensatz reagieren und die Daten mit der konfigurierten Methode für den angegebenen Datensatz verarbeiten wird.
-
In nachgelagerten Umwandlungsaufgaben:
Datensatzumwandlungen werden durch Abschneiden und Neuladen geladen.
SQL-Umwandlungen und Umwandlungsflüsse werden neu geladen, indem mit dem vollständigen Ladevorgang verglichen und Änderungen angewendet werden.
-
Data Mart-Aufgaben, die einer Speicheraufgabe unmittelbar folgen, werden durch Abschneiden und Neuladen geladen.
Sie können den Ladevorgang für Tabellen mit ausstehendem Laden abbrechen, indem Sie auf Ladevorgang abbrechen klicken. Bereits geladene Tabellen sind davon nicht betroffen, und aktuell laufende Ladevorgänge werden abgeschlossen.
Schemaentwicklung
Mit der Schemaentwicklung können Sie strukturelle Änderungen an mehreren Datenquellen leicht erkennen und dann steuern, wie diese Änderungen auf Ihre Aufgabe angewendet werden. Mit der Schemaentwicklung können DDL-Änderungen am Schema der Datenquelle erkannt werden. Sie können einige Änderungen auch automatisch übernehmen.
Für jeden Änderungstyp können Sie im Abschnitt Schemaentwicklung der Aufgabeneinstellungen auswählen, wie die Änderungen behandelt werden sollen. Sie können die Änderungen übernehmen oder ignorieren, die Tabelle aussetzen oder die Aufgabenverarbeitung anhalten.
Sie können für jeden Änderungstyp festlegen, welche Aktion für die Bearbeitung der DDL-Änderung verwendet werden soll. Einige Aktionen sind nicht für alle Änderungstypen verfügbar.
-
Auf Ziel anwenden
Änderungen werden automatisch angewendet.
-
Ignorieren
Änderungen werden ignoriert.
-
Tabelle aussetzen
Die Tabelle wird ausgesetzt. Die Tabelle wird in Überwachen als fehlerhaft angezeigt.
-
Aufgabe anhalten
Die Bearbeitung der Aufgabe wird angehalten. Dies ist nützlich, wenn Sie alle Schemaänderungen manuell durchführen möchten. Dadurch wird auch die Planung angehalten, d. h. geplante Ausführungen werden nicht durchgeführt.
Die folgenden Änderungen werden unterstützt:
-
Spalte hinzufügen
-
Tabelle erstellen, die dem Auswahlmuster entspricht
Wenn Sie eine Auswahlregel verwendet haben, um Datensätze hinzuzufügen, die einem Muster entsprechen, werden neue Tabellen, die mit dem Muster übereinstimmen, erkannt und hinzugefügt.
Weitere Informationen zu Aufgabeneinstellungen finden Sie unter Schemaentwicklung.
Einschränkungen für die Schemaentwicklung
Die folgenden Einschränkungen gelten für die Schemaentwicklung:
-
Schemaentwicklung wird nur unterstützt, wenn Sie CDC als Aktualisierungsmethode verwenden.
-
Wenn Sie die Einstellungen für die Schemaentwicklung geändert haben, müssen Sie die Aufgabe erneut vorbereiten.
-
Wenn Sie Tabellen umbenennen, wird die Schemaentwicklung nicht unterstützt. In diesem Fall müssen Sie die Metadaten aktualisieren, bevor Sie die Aufgabe vorbereiten.
-
Wenn Sie eine Aufgabe entwerfen, müssen Sie den Browser aktualisieren, um Änderungen an der Schemaentwicklung zu erhalten. Sie können Benachrichtigungen festlegen, um bei Änderungen einen Alarm zu erhalten.
-
Bei Bereitstellungsaufgaben wird das Löschen einer Spalte nicht unterstützt. Das Löschen einer Spalte und das Hinzufügen einer neuen Spalte führt zu einem Tabellenfehler.
-
Bei Bereitstellungsaufgaben wird die Tabelle bei einem Tabellenlöschvorgang nicht gelöscht. Wenn Sie eine Tabelle löschen und dann eine Tabelle hinzufügen, wird nur die alte Tabelle abgeschnitten und es wird keine neue Tabelle hinzugefügt.
-
Das Ändern der Spaltenlänge ist nicht für alle Ziele möglich, je nach Unterstützung in der Zieldatenbank.
-
Wenn ein Spaltenname geändert wird, werden explizite Umwandlungen, die mit dieser Spalte definiert wurden, nicht wirksam, da sie auf dem Spaltennamen basieren.
-
Die Einschränkungen für die Aktualisierung von Metadaten gelten auch für die Schemaentwicklung.
-
Wenn eine Aufgabe Designänderungen enthält, die noch nicht vorbereitet wurden, und Quellschema-Evolutionsänderungen erkannt werden, wenn die Aufgabe ausgeführt wird, wird die Aufgabe gestoppt, um Konflikte zu vermeiden. Bereiten Sie die ausstehenden Designänderungen vor und führen Sie die Aufgabe erneut aus.
Beim Erfassen von DDL-Änderungen gelten die folgenden Einschränkungen:
-
Wenn in der Quelldatenbank eine schnelle Abfolge von Vorgängen stattfindet (z.B. DDL>DML>DDL), kann Qlik Talend Data Integration das Protokoll in der falschen Reihenfolge analysieren, was zu fehlenden Daten oder unvorhersehbarem Verhalten führt. Um dieses Risiko zu minimieren, wird als Best Practice empfohlen, zu warten, bis die Änderungen auf das Ziel angewendet wurden, bevor Sie den nächsten Vorgang durchführen.
Wenn beispielsweise während der Änderungserfassung eine Quelltabelle mehrmals kurz hintereinander umbenannt wird (und der zweite Vorgang sie wieder in ihren ursprünglichen Namen zurückbenennt), kann der Fehler „Tabelle ist in der Zieldatenbank bereits vorhanden“ auftreten.
- Wenn Sie den Namen einer Tabelle ändern, die in einer Aufgabe verwendet wird, und dann die Aufgabe anhalten, erfasst Qlik Talend Data Integration keine Änderungen, die nach dem Fortsetzen der Aufgabe an dieser Tabelle vorgenommen werden.
-
Das Umbenennen einer Quelltabelle, während eine Aufgabe angehalten ist, wird nicht unterstützt.
- Die Neuzuweisung der Primärschlüsselspalten einer Tabelle wird nicht unterstützt (und daher auch nicht in die DDL-Verlauf-Kontrolltabelle geschrieben).
- Wenn der Datentyp einer Spalte geändert wird und die (gleiche) Spalte dann umbenannt wird , während die Aufgabe angehalten ist, wird die DDL-Änderung in der DDL-Verlauf-Kontrolltabelle als „Spalte verwerfen“ und nach Fortsetzen der Aufgabe als „Spalte hinzufügen“ angezeigt. Beachten Sie, dass dasselbe Verhalten auch als Folge einer längeren Latenzzeit auftreten kann.
- CREATE TABLE-Vorgänge, die in der Quelle ausgeführt werden, während eine Aufgabe angehalten ist, werden auf das Ziel angewendet, wenn die Aufgabe fortgesetzt wird, werden jedoch nicht als DDL in der DDL-Verlauf-Kontrolltabelle aufgezeichnet.
-
Vorgänge, die mit Metadatenänderungen verbunden sind (z.B. ALTER TABLE, Reorganisation, Neuerstellung eines geclusterten Index usw.) können zu unvorhersehbarem Verhalten führen, wenn sie zu folgenden Zeitpunkten durchgeführt werden:
-
bei vollständigem Laden
-ODER-
-
zwischen dem Zeitstempel Änderungsverarbeitung beginnen ab und der aktuellen Uhrzeit (d. h. dem Zeitpunkt, zu dem der Benutzer im Dialogfeld Erweiterte Ausführungsoptionen auf OK klickt).
Beispiel:
WENN:
die angegebene Uhrzeit für Änderungsverarbeitung beginnen ab 10:00 Uhr ist
UND:
um 10:10 Uhr der Tabelle Mitarbeiter eine Spalte namens Alter hinzugefügt wurde
UND:
der Benutzer im Dialogfeld Erweiterte Ausführungsoptionen um 10:15 Uhr auf OK klickt
DANN:
können Änderungen, die zwischen 10:00 und 10:10 Uhr vorgenommen wurden, zu CDC-Fehlern führen.
InformationshinweisIn jedem der oben genannten Fälle müssen die betroffenen Tabellen neu geladen werden, damit die Daten ordnungsgemäß an das Ziel verschoben werden können.
-
- Der DDL-Befehl
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>repliziert den Standardwert nicht in das Ziel und die neue/geänderte Spalte wird auf NULL gesetzt. Beachten Sie, dass dies auch dann vorkommen kann, wenn die DDL, von der die Spalte hinzugefügt/geändert wurde, in der Vergangenheit ausgeführt wurde. Wenn die neue/geänderte Spalte nullfähig ist, aktualisiert der Quellendpunkt alle Tabellenzeilen, bevor die DDL selbst protokolliert wird. Infolgedessen erfasst Qlik Talend Data Integration die Änderungen, aktualisiert aber nicht das Ziel. Da die neue/geänderte Spalte auf NULL gesetzt wird, wenn die Zieltabelle keinen Primärschlüssel/eindeutigen Index hat, wird bei nachfolgenden Aktualisierungen die Meldung "null Zeilen betroffen" ausgegeben. -
Änderungen an den Präzisionsspalten TIMESTAMP und DATE werden nicht erfasst.
Anzeigen von Aufgabeninformationen
Klicken Sie in der Menüleiste auf ![]() , um Aufgabeninformationen anzuzeigen, wie zum Beispiel:
, um Aufgabeninformationen anzuzeigen, wie zum Beispiel:
-
Besitzer
-
Bereich
-
Datenplattform
-
Projekt-ID
-
Datenaufgaben-Laufzeit-ID
Speichereinstellungen
Sie können Eigenschaften für die Speicherdatenaufgabe festlegen, wenn die Datenplattform ein Cloud Data Warehouse ist. Wenn Sie Qlik Cloud als Datenplattform verwenden, finden Sie weitere Informationen unter -Speichereinstelllungen für Datenprojekte mit Qlik Cloud als Datenplattform.
-
Klicken Sie auf Einstellungen.
Allgemeine Einstellungen
-
Datenbank
Datenbank, die in der Datenquelle verwendet werden soll.
-
Aufgabenschema
Sie können den Namen des Speicher-Datenaufgabenschemas ändern. Der Standardname ist der Name der Speicheraufgabe.
-
Internes Schema
Sie können den Namen des Datenobjektschemas des internen Speichers ändern. Der Standardname ist der Name der Speicheraufgabe, an den _internal angehängt ist.
-
Standardgroßschreibung von Schemanamen
Sie können die Standardgroßschreibung für alle Schemanamen festlegen. Wenn Ihre Datenbank so konfiguriert ist, dass die Großschreibung erzwungen wird, hat diese Option keine Wirkung.
- Präfix für alle Tabellen und Ansichten
Sie können ein Präfix für alle Tabellen und Ansichten festlegen, die mit dieser Aufgabe erstellt wurden.
InformationshinweisSie müssen ein eindeutiges Präfix verwenden, wenn Sie ein Datenbankschema in mehreren Datenaufgaben nutzen möchten. -
Verlauf
Sie können Verlaufsänderungsdaten beibehalten, um Daten leicht erneut so erstellen zu können, wie sie zu einem bestimmten Zeitpunkt aussahen. Sie können Verlaufsansichten und Live-Verlaufsansichten verwenden, um Verlaufsdaten anzuzeigen. Wählen Sie Verlaufsdatensätze beibehalten und Datensatzarchiv ändern, um historische Änderungsdaten zu aktivieren.
-
Wenn Sie Speicher mit Bereitstellung vergleichen, können Sie wählen, wie Datensätze, die in der Bereitstellung nicht vorhanden sind, verwaltet werden sollen.
-
Als gelöscht markieren
Dadurch wird ein vorläufiges Löschen von Datensätzen durchgeführt, die in der Bereitstellung nicht vorhanden sind.
-
Behalten
Dadurch werden alle Datensätze beibehalten, die in der Bereitstellung nicht vorhanden sind.
InformationshinweisFür Datensätze in Speicherdatenaufgaben muss ein Primärschlüssel festgelegt werden. Andernfalls wird jedes Mal, wenn Bereitstellungsdaten geladen werden, ein anfänglicher Ladevorgang für die Speicherdatenaufgabe durchgeführt. -
-
In Katalog veröffentlichen
Wählen Sie diese Option aus, um diese Version der Daten als Datensatz im Katalog zu veröffentlichen. Der Kataloginhalt wird aktualisiert, wenn Sie diese Aufgabe zum nächsten Mal vorbereiten.
Weitere Informationen zu Katalog finden Sie unter Verstehen Ihrer Daten mit Katalogwerkzeugen.
Einstellungen für Ansichten
-
Live-Ansichten
Verwenden Sie Live-Ansichten, um die Tabellen mit der niedrigsten Latenz zu lesen.
Weitere Informationen zu Live-Ansichten finden Sie unter Verwendung von Live-Ansichten.
InformationshinweisLive-Ansichten sind weniger effizient als Standardansichten und benötigen mehr Ressourcen, da die angewandten Daten neu berechnet werden müssen.
Einstellungen für Ansichtstypen
Die Einstellungen für Ansichtstypen gelten nur für Snowflake.
-
Standardansichten
Verwenden Sie in den meisten Fällen die Standardansichten.
-
Sichere Snowflake-Ansichten
Verwenden Sie sichere Snowflake-Ansichten für Ansichten, die für den Schutz von Daten oder sensiblen Informationen vorgesehen sind, z.B. Ansichten, die erstellt wurden, um den Zugriff auf sensible Daten zu beschränken, die nicht für alle Benutzer der zugrunde liegenden Tabellen zugänglich sein sollen.
Informationshinweis Sichere Snowflake- Ansichten können langsamer ausgeführt werden als Standardansichten.
Laufzeiteinstellungen
-
Parallele Ausführung
Sie können die maximale Anzahl an Verbindungen für vollständige Ladevorgänge auf eine Zahl von 1 bis 5 setzen.
-
Warehouse
Der Name des Cloud Data Warehouse. Diese Einstellung ist nur für Snowflake anwendbar.
Tabellentypeinstellungen
Diese Einstellungen sind nur in Projekten mit Snowflake als Datenplattform verfügbar.
-
Tabellentyp
Sie können auswählen, welchen Tabellentyp Sie verwenden möchten:
-
Snowflake-Tabellen
-
Von Snowflake verwaltete Iceberg-Tabellen
Sie müssen den Standardnamen des externen Volumes in Externes Snowflake-Volume festlegen.
-
-
Zu verwendender Cloud-Speicherordner
Sie können auswählen, welcher Ordner beim Bereitstellen von Daten im Bereitstellungsbereich verwendet werden soll.
-
Standardordner
Dadurch wird ein Ordner mit dem Standardnamen <projektname>/<datenaufgabenname> erstellt.
-
Stammordner
Speichern Sie Daten im Stammordner des Speichers.
-
Ordner
Geben Sie einen Ordnernamen an, der verwendet werden soll.
-
-
Mit Snowflake Open Catalog synchronisieren
Aktivieren Sie diese Option, damit Snowflake Open Catalog die Dateien im Cloud-Dateispeicher verwalten kann.
Schemaentwicklung
Wählen Sie aus, wie die folgenden DDL-Änderungstypen im Schema behandelt werden sollen. Wenn Sie die Einstellungen für die Schemaentwicklung geändert haben, müssen Sie die Aufgabe erneut vorbereiten. In der folgenden Tabelle wird beschrieben, welche Aktionen für die unterstützten DDL-Änderungen verfügbar sind.
| DDL-Änderung | Auf Ziel anwenden | Ignorieren | Aufgabe anhalten |
|---|---|---|---|
| Spalte hinzufügen | Ja | Ja | Ja |
| Tabelle erstellen
Wenn Sie eine Auswahlregel verwendet haben, um Datensätze hinzuzufügen, die einem Muster entsprechen, werden neue Tabellen, die mit dem Muster übereinstimmen, erkannt und hinzugefügt. |
Ja | Ja | Ja |
-Speichereinstelllungen für Datenprojekte mit Qlik Cloud als Datenplattform
Sie können festlegen, welchen Ordner Sie im Speicher verwenden möchten, wenn die Datenplattform Qlik Cloud ist.
-
Klicken Sie auf Einstellungen.
-
Wählen Sie, welcher Ordner im Speicher verwendet werden soll.
-
Klicken Sie auf OK, wenn Sie fertig sind.
Vorgänge für die Speicherdatenaufgabe
Sie können die folgenden Vorgänge für eine Speicherdatenaufgabe über das Aufgabenmenü durchführen.
-
Öffnen
Damit wird die Speicherdatenaufgabe geöffnet. Sie können die Tabellenstruktur und die Details der Datenaufgabe anzeigen und den Status für den vollständigen Ladevorgang und die Änderungssätze überwachen.
-
Bearbeiten
Sie können den Namen und die Beschreibung der Aufgabe bearbeiten und Tags hinzufügen.
-
Löschen
Sie können die Datenaufgabe löschen, wenn sie nicht ausgeführt wird und keine Abhängigkeiten zu nachgelagerten Aufgaben im selben Projekt bestehen.
-
Klicken Sie in der Ansicht Pipeline-Projekt des Projekts in einer Aufgabe auf
 und wählen Sie Löschen aus.
und wählen Sie Löschen aus.
Von der Aufgabe erstellte Artefakte (Tabellen und Ansichten) werden ebenfalls gelöscht, es sei denn, Sie möchten sie beibehalten.
InformationshinweisBeachten Sie, dass die von Ihnen beibehaltenen Artefakte nicht mehr von der Aufgabe aktualisiert werden. -
-
Vorbereiten
Dadurch wird eine Aufgabe für die Ausführung vorbereitet. Der Vorgang umfasst Folgendes:
-
Validierung, dass das Design gültig ist.
-
Erstellen oder Ändern der physischen Tabellen und Ansichten entsprechend dem Design.
-
Generieren des SQL-Codes für die Datenaufgabe
-
Erstellen oder Ändern der Katalogeinträge für die Ausgabendatensätze der Aufgabe.
Sie können den Fortschritt unter Vorbereitungsfortschritt unten im Bildschirm verfolgen.
-
-
Datensätze validieren
Dadurch werden alle in der Datenaufgabe enthaltenen Datensätze validiert.
Erweitern Sie Validieren und anpassen, um alle Validierungsfehler und Designänderungen anzuzeigen.
-
Tabellen neu erstellen
Dadurch werden die Datasets von der Quelle neu erstellt. Bei der Neuerstellung einer Tabelle reagiert die nachgelagerte Aufgabe so, als ob ein Ladevorgang mit Abschneiden und Neuladen für die Quelldatensätze aufgetreten wäre. Weitere Informationen finden Sie unter Fehlerbehebung für eine Speicherdatenaufgabe.
-
Anhalten
Sie können den Vorgang für die Datenaufgabe anhalten. Die Datenaufgabe aktualisiert dann die Tabellen nicht mehr.
InformationshinweisDiese Option ist verfügbar, wenn die Datenaufgabe ausgeführt wird. -
Fortsetzen
Sie können den Vorgang für eine Datenaufgabe an der Stelle wieder aufnehmen, an der er angehalten wurde.
InformationshinweisDiese Option ist verfügbar, wenn die Datenaufgabe angehalten wird. -
Daten umwandeln
Erstellen Sie wiederverwendbare Umwandlungen auf Zeilenebene basierend auf Regeln und benutzerdefinierter SQL. Damit wird eine Umwandlungsdatenaufgabe erstellt.
-
Data Mart erstellen
Erstellen Sie einen Data Mart, um Ihre Datenaufgaben zu nutzen. Damit wird eine Data Mart-Datenaufgabe erstellt.
Beschränkungen
-
Falls die Datenaufgabe Datensätze enthält und Sie beliebige Parameter in der Verbindung ändern, zum Beispiel Benutzername, Datenbank oder Schema, wird davon ausgegangen, dass die Daten im neuen Speicherort vorhanden sind. Ist dies nicht der Fall, können Sie Folgendes tun:
-
Die Daten in der Quelle an den neuen Speicherort verschieben.
-
Eine neue Datenaufgabe mit denselben Einstellungen erstellen.
-
-
Es ist nicht möglich, Primärschlüssel in Speicheraufgaben in Projekten mit Qlik Cloud (QVD) als Ziel zu ändern. Aktualisieren Sie die Primärschlüssel in der Bereitstellungsaufgabe, erstellen Sie die Bereitstellungsaufgabe neu und erstellen Sie dann die Speicheraufgabe neu.
-
Wenn Sie den Iceberg-Speicher verwenden, werden JSON-Datenspalten als STRING gespeichert.