
데이터 집합 저장
저장소 데이터 작업을 사용하여 데이터 집합을 저장할 수 있습니다. 저장소 데이터 작업은 랜딩 데이터 작업에 의해 클라우드 랜딩 영역에 랜딩된 데이터를 소비합니다. 예를 들어, 분석 응용 프로그램에서 테이블을 사용할 수 있습니다.
-
랜딩 데이터 작업의 상태가 최소한 준비됨인 경우 저장소 데이터 작업을 설계할 수 있습니다.
-
랜딩 데이터 작업의 상태가 최소한 즉시 실행 가능인 경우 저장소 데이터 작업을 준비할 수 있습니다.
저장소 데이터 작업은 소비된 랜딩 데이터 작업과 동일한 작동 모드(전체 로드 또는 전체 로드 및 CDC)를 사용합니다. 구성 속성은 두 가지 작동 모드와 모니터 및 제어 옵션 간에 다릅니다. 전체 로드 전용과 함께 클라우드 대상 랜딩 데이터 작업을 사용하는 경우 저장소 데이터 작업은 물리적 테이블을 생성하는 대신 랜딩 테이블에 대한 보기를 만듭니다.
데이터 웨어하우스에 테이블을 저장하는 것 외에도 데이터 플랫폼에서 관리하는 Iceberg 테이블로 테이블을 저장할 수도 있습니다. 이 옵션은 현재 Snowflake 프로젝트에서만 사용할 수 있습니다. 작업 설정의 테이블 유형에서 Snowflake 관리 Iceberg 테이블을 선택하면 됩니다.
저장소 데이터 작업 만들기
세 가지 방법으로 저장소 데이터 작업을 만들 수 있습니다.
-
랜딩 데이터 작업에서 ...을 클릭하고 데이터 저장을 선택하여 이 랜딩 데이터 자산을 기반으로 저장소 데이터 작업을 만듭니다.
-
파이프라인 프로젝트에서 만들기를 클릭한 다음 데이터 저장을 클릭합니다. 이 경우 사용할 랜딩 데이터 작업을 지정해야 합니다.
-
데이터를 온보딩하면 저장소 데이터 작업이 만들어집니다. 이는 데이터 온보딩 시 만들어지는 랜딩 데이터 작업에 연결됩니다.
자세한 내용은 데이터 웨어하우스로 데이터 온보딩을 참조하십시오.
저장소 데이터 작업을 만든 경우:
-
...을 클릭하고 열기를 선택하여 저장소 데이터 작업을 엽니다.
저장소 데이터 작업이 열리고 랜딩 데이터 자산의 테이블을 기반으로 출력 데이터 집합을 미리 볼 수 있습니다. -
포함된 데이터세트에 필요한 모든 변경 사항(예: 변환, 데이터 필터링 또는 열 추가)을 적용합니다.
자세한 내용은 데이터 집합 관리을 참조하십시오.
-
원하는 변환을 추가했으면 데이터 집합 유효성 검사를 클릭하여 데이터 집합의 유효성을 검사할 수 있습니다. 유효성 검사에서 오류가 발견되면 계속하기 전에 오류를 수정합니다.
자세한 내용은 데이터 집합 유효성 검사 및 조정을 참조하십시오.
-
데이터 모델 만들기
모델을 클릭하여 포함된 데이터 집합 간의 관계를 설정합니다.
자세한 내용은 데이터 모델 만들기을 참조하십시오.
-
준비를 클릭하여 데이터 작업 및 모든 필수 아티팩트를 준비합니다. 이 작업은 시간이 다소 걸릴 수 있습니다.
화면 하단의 준비 진행률에서 진행률을 확인할 수 있습니다.
-
상태가 즉시 실행 가능으로 표시되면 데이터 작업을 실행할 수 있습니다.
실행을 클릭합니다.
이제 데이터 작업이 데이터를 저장할 데이터 집합을 만들기 시작합니다.
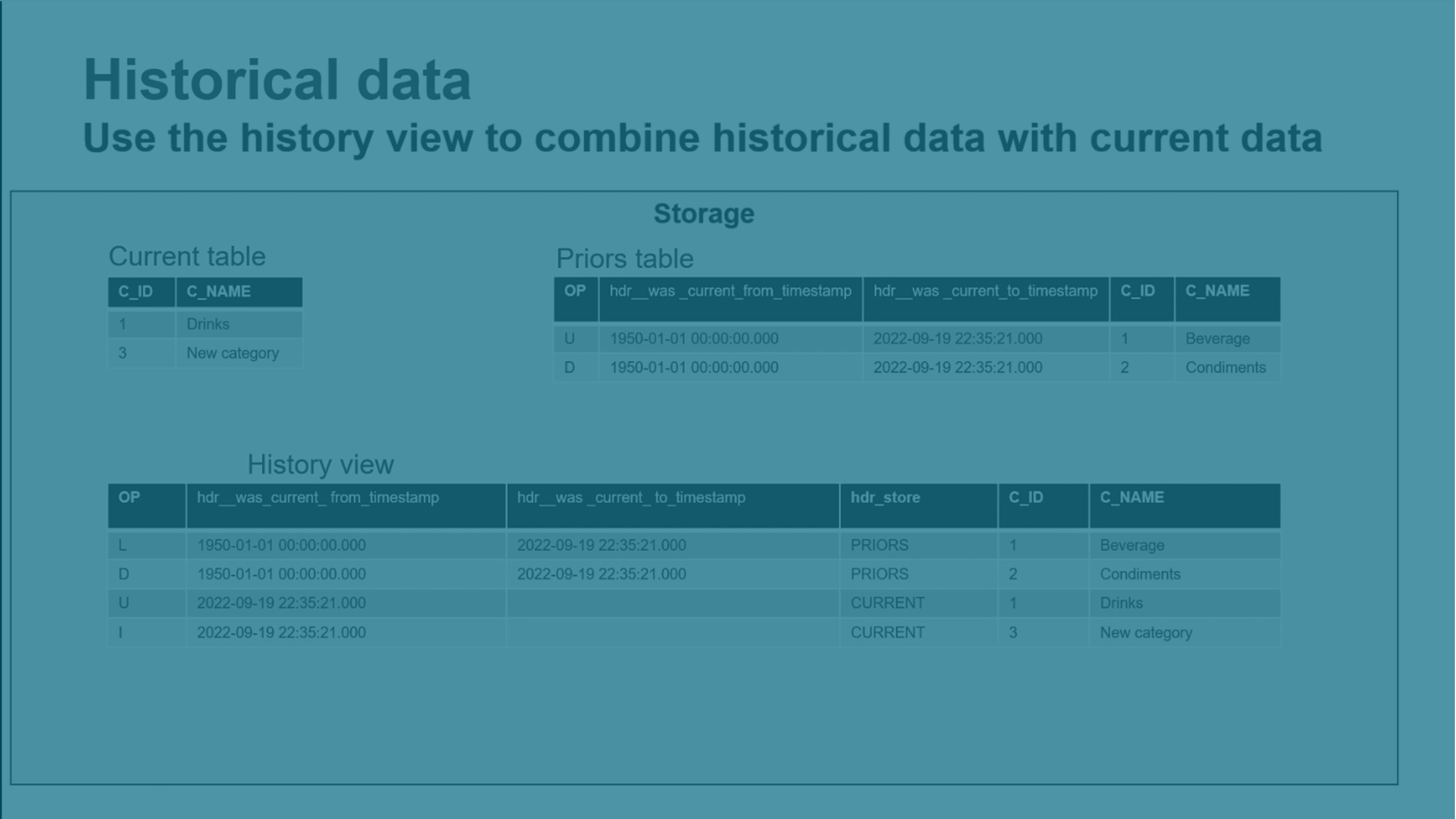
기록 데이터 유지
유형 2의 기록 변경 데이터를 보관하면 특정 시점의 데이터를 쉽게 다시 만들 수 있습니다. 이렇게 하면 전체 HDS(기록 데이터 저장소)가 만들어집니다.
-
유형 2 천천히 변경되는 차원이 지원됩니다.
-
변경된 레코드가 병합되면 변경된 데이터를 저장하기 위해 새 레코드를 만들고 이전 레코드는 그대로 둡니다.
-
새로운 HDS 레코드에는 자동으로 타임스탬프가 지정되어 추세 분석 및 기타 시간 중심 분석 데이터 마트를 만들 수 있습니다.
다음을 클릭하여 기록 데이터를 활성화할 수 있습니다.
-
데이터를 온보딩할 때 설정에서 현재 데이터와 이전 데이터 기록을 모두 사용하여 복제합니다.
-
저장소 작업의 설정 대화 상자에서 기록 변경 레코드를 유지하고 레코드 보관 파일을 변경합니다.
HDS 데이터는 내부 데이터 스키마의 이전 테이블에 저장됩니다. 외부 데이터 스키마의 기록 보기 및 실시간 기록 보기를 사용하여 기록 데이터를 볼 수 있습니다.
-
기록 보기는 현재 테이블과 이전 테이블의 데이터를 병합합니다. 이 보기에는 병합된 모든 변경 내용이 포함됩니다.
-
실시간 기록 보기는 현재 테이블, 이전 테이블 및 변경 테이블의 데이터를 병합합니다. 이 보기에는 아직 병합되지 않은 모든 변경 내용도 포함됩니다.
자세한 내용은 클라우드 데이터 웨어하우스의 데이터 세트 아키텍처을 참조하십시오.
저장
저장소 작업 예약
주기적으로 업데이트되도록 저장소 작업을 예약할 수 있습니다.
-
랜딩 데이터 입력 작업이 전체 로드 및 CDC를 사용하는 경우 시간 기반 일정만 설정할 수 있습니다.
-
랜딩 데이터 입력 작업이 전체 로드를 사용하는 경우 시간 기반 일정을 설정하거나 입력 랜딩 데이터 작업이 실행을 완료할 때 실행되도록 작업을 설정할 수 있습니다.
정보 메모전체 로드를 사용하여 입력 랜딩 데이터 작업으로 시간 기반 일정을 실행할 때 랜딩 작업이 계속 실행되는 동안 랜딩에서 완료된 모든 테이블을 사용할 수 있다는 점을 고려하십시오. 이를 통해 랜딩 및 저장소를 동시에 실행할 수 있으므로 총 로드 시간을 개선할 수 있습니다. -
프로젝트가 Iceberg 테이블에 데이터를 저장하는 경우 시간 기반 일정을 설정하거나 데이터 파티션 변경이 닫힐 때 작업이 실행되도록 설정할 수 있습니다.
데이터 작업에서 ...을 클릭하고 예약을 선택하여 일정을 만듭니다. 기본 일정 설정은 파이프라인 프로젝트의 설정에서 상속됩니다. 기본 설정에 대한 자세한 내용은 스토리지 기본값을 참조하십시오. 일정을 사용하려면 항상 일정을 켜기로 설정해야 합니다.
시간 기반 일정
랜딩 유형에 관계없이 시간 기반 일정을 사용하여 저장소 데이터 작업을 실행할 수 있습니다.
-
데이터 작업 실행에서 특정 시간에를 선택합니다.
시간별, 일별, 주별 또는 월별 일정을 설정할 수 있습니다.
이벤트 기반 일정
-
데이터 작업 실행에서 입력 데이터 작업을 성공적으로 완료한 경우를 선택합니다.
저장소 작업은 랜딩 데이터 입력 작업이 성공적으로 완료될 때마다 실행됩니다.
저장소 작업 모니터링
모니터링을 클릭하여 저장소 작업의 상태와 진행률을 모니터링할 수 있습니다.
자세한 내용은 개별 데이터 작업 모니터링을 참조하십시오.
저장소 데이터 작업 문제 해결
저장소 데이터 작업에서 하나 이상의 테이블에 문제가 있는 경우 데이터를 다시 로드하거나 다시 만들어야 할 수 있습니다. 이를 수행하는 데 사용할 수 있는 몇 가지 옵션이 있습니다. 다음 순서로 사용할 옵션을 고려합니다.
-
랜딩 시 데이터 집합을 다시 로드할 수 있습니다. 랜딩 시 데이터 집합을 다시 로드하면 유형 2 기록을 유지하는 동안 저장소의 비교 프로세스가 시작되고 데이터가 수정됩니다. 이 옵션은 다음과 같은 경우에도 고려해야 합니다.
-
전체 로드가 오래전에 수행되어 변경된 부분이 많습니다.
-
처리된 전체 로드 및 변경 테이블 레코드가 랜딩 영역 유지 관리의 일부이므로 삭제된 경우.
-
-
저장소 데이터 작업에서 데이터를 다시 로드할 수 있습니다.
기록 데이터가 활성화된 경우 저장소를 다시 로드하면 기록 데이터가 손실될 수 있습니다. 이것이 문제인 경우 대신 소스에서 랜딩을 다시 로드하는 것이 좋습니다.
-
테이블을 다시 만들 수 있습니다. 소스에서 데이터 집합을 다시 만듭니다.
-
...을 클릭한 다음 테이블 다시 만들기를 클릭합니다. 테이블을 다시 만들 때 다운스트림 작업은 소스 데이터 집합에서 자르기 및 다시 로드 작업이 발생한 것처럼 반응합니다.
정보 메모개별 테이블에 문제가 있는 경우 테이블을 다시 만드는 대신 먼저 테이블을 다시 로드해 보는 것이 좋습니다. 테이블을 다시 만들면 기록 데이터가 손실될 수 있습니다. 주요 변경 내용이 있는 경우 데이터를 다시 로드하기 위해 다시 만들어진 데이터 작업을 사용하는 다운스트림 데이터 작업도 준비해야 합니다.
-
데이터 다시 로드
테이블을 수동으로 다시 로드할 수 있습니다. 이는 하나 이상의 테이블에 문제가 있는 경우 유용합니다.
-
데이터 작업을 열고 모니터링 탭을 선택합니다.
-
다시 로드할 테이블을 선택합니다.
-
테이블 다시 로드를 클릭합니다.
다시 로드는 다음에 작업이 실행될 때 발생하며 다음을 통해 수행됩니다.
-
테이블을 자릅니다.
-
랜딩 데이터를 테이블에 로드합니다.
-
다시 로드 시간부터 누적된 변경 내용을 로드합니다.
일반적으로 랜딩 시 데이터 집합을 다시 로드하는 것이 가장 좋습니다. 이는 특히 다음과 같은 경우에 해당됩니다.
-
기록 데이터가 활성화된 경우 저장소를 다시 로드하면 기록 데이터가 손실될 수 있습니다. 랜딩 시 데이터 집합을 다시 로드하면 저장소의 비교 프로세스가 트리거되고 유형 2 기록을 유지하는 올바른 데이터가 실행됩니다.
-
오래전에 전체 로드를 수행할 때 수많은 변경 내용이 발생했습니다.
-
처리된 전체 로드 및 변경 테이블 레코드가 랜딩 영역 유지 관리의 일부이므로 삭제된 경우.
변경 내용을 적용하고 소급 적용을 방지하기 위해 다운스트림 작업이 다시 로드됩니다. 자르고 다시 로드하여 다시 로드를 수행하면 모든 다운스트림 개체도 자르고 다시 로드하여 다시 로드됩니다.
랜딩 또는 저장소 데이터 작업을 다시 로드한 후의 다운스트림 영향

다운스트림에 미치는 영향은 실행된 다시 로드 작업 유형과 즉각적인 다운스트림 데이터 집합의 유형에 따라 다릅니다. 표준 처리는 데이터 집합이 특정 데이터 집합에 대해 구성된 방법을 사용하여 데이터에 반응하고 처리한다는 것을 의미합니다.
-
다운스트림 변환 작업에서:
데이터 집합 변환은 자르고 다시 로드하여 다시 로드됩니다.
SQL 변환 및 transformation flow는 전체 로드와 비교하고 변경 내용을 적용하여 다시 로드됩니다.
-
저장소 작업 직후의 데이터 마트 작업은 자르기 및 로드를 통해 다시 로드됩니다.
다시 로드 취소를 클릭하면 다시 로드 대기 중인 테이블의 다시 로드를 취소할 수 있습니다. 이는 이미 다시 로드된 테이블에는 영향을 미치지 않으며 현재 실행 중인 다시 로드가 완료됩니다.
스키마 진화
스키마 진화를 사용하면 여러 데이터 소스의 구조적 변경 내용을 쉽게 감지하고 해당 변경 내용을 작업에 적용하는 방법을 제어할 수 있습니다.스키마 진화는 소스 데이터 스키마에 대한 DDL 변경 내용을 감지하는 데 사용할 수 있습니다.일부 변경 내용을 자동으로 적용할 수도 있습니다.
각 변경 유형에 대해 작업 설정의 스키마 진화 섹션에서 변경 내용을 처리하는 방법을 선택할 수 있습니다.변경 내용을 적용하거나, 변경 내용을 무시하거나, 테이블을 일시 중단하거나, 작업 처리를 중지할 수 있습니다.
각 변경 유형에 대해 DDL 변경을 처리하는 데 사용할 작업을 설정할 수 있습니다.일부 작업은 모든 변경 유형에 사용할 수 없습니다.
-
대상에 적용
변경 내용을 자동으로 적용합니다.
-
무시
변경 내용을 무시합니다.
-
일시 중단 테이블
테이블을 일시 중단합니다.모니터에 표가 오류로 표시됩니다.
-
작업 중지
작업 처리를 중지합니다.이 기능은 모든 스키마 변경 내용을 수동으로 처리하려는 경우에 유용합니다.이렇게 하면 일정 예약도 중지되어 예약된 실행이 수행되지 않습니다.
다음과 같은 변경 내용이 지원됩니다.
-
열 추가
-
선택 패턴과 일치하는 테이블 만들기
선택 규칙을 사용하여 패턴과 일치하는 데이터 집합을 추가한 경우 패턴을 충족하는 새 테이블이 감지되어 추가됩니다.
작업 설정에 대한 자세한 내용은 스키마 진화를 참조하십시오.
스키마 진화에 대한 제한 사항
스키마 진화에는 다음과 같은 제한이 적용됩니다.
-
스키마 진화는 CDC를 업데이트 방법으로 사용하는 경우에만 지원됩니다.
-
스키마 진화 설정을 변경한 경우 작업을 다시 준비해야 합니다.
-
테이블 이름을 바꾸면 스키마 진화가 지원되지 않습니다. 이 경우 작업을 준비하기 전에 메타데이터를 새로 고쳐야 합니다.
-
작업을 디자인하는 경우 스키마 진화 변경 사항을 적용하려면 브라우저를 새로 고쳐야 합니다. 변경 내용에 대해 알림을 받도록 설정할 수 있습니다.
-
랜딩 작업에서는 열을 삭제하는 것이 지원되지 않습니다. 열을 삭제하고 추가하면 테이블 오류가 발생합니다.
-
랜딩 작업에서 테이블 삭제 작업을 수행해도 테이블이 삭제되지 않습니다. 테이블을 삭제한 다음 다시 테이블을 추가하면 기존 테이블만 잘리고, 새 테이블이 추가되지 않습니다.
-
대상 데이터베이스의 지원 여부에 따라, 일부 대상에서는 열 길이를 변경할 수 없습니다.
-
열 이름이 변경되는 경우, 해당 열을 사용하여 정의된 명시적 변환은 열 이름을 기반으로 하므로 적용되지 않습니다.
-
메타데이터 새로 고침에 대한 제한은 스키마 진화에도 적용됩니다.
-
작업에 아직 준비되지 않은 디자인 변경 사항이 포함되어 있고 작업 실행 시 소스 스키마 진화 변경 사항이 감지되면 충돌을 방지하기 위해 작업이 중지됩니다. 보류 중인 디자인 변경 사항을 준비하고 작업을 다시 실행합니다.
DDL 변경 사항을 캡처할 때 다음과 같은 제한이 적용됩니다.
-
소스 데이터베이스에서 빠른 일련의 작업(예: DDL>DML>DDL)이 발생하는 경우 Qlik Talend Data Integration이 잘못된 순서로 로그를 구문 분석하여 데이터가 누락되거나 예측할 수 없는 동작이 발생할 수 있습니다. 이러한 동작이 발생할 가능성을 최소화하려면 다음 작업을 수행하기 전에 대상에 변경 사항이 적용될 때까지 기다리는 것이 가장 좋습니다.
예를 들어, 변경 사항을 캡처하는 동안 원본 테이블 이름이 빠르게 여러 번 연속해서 바뀌고 두 번째 작업에서 원래 이름으로 다시 바뀌는 경우, 해당 테이블이 대상 데이터베이스에 이미 존재한다는 오류가 발생할 수 있습니다.
- 작업에서 사용된 테이블의 이름을 변경한 다음 작업을 중지하면 Qlik Talend Data Integration은 작업이 다시 시작된 후에 해당 테이블에 적용된 변경 사항을 캡처하지 않습니다.
-
작업이 중지된 동안에는 소스 테이블의 이름을 바꾸는 것이 지원되지 않습니다.
- 테이블의 기본 키 열 재할당은 지원되지 않습니다(따라서 DDL 기록 제어 테이블에 기록되지 않음).
- 열의 데이터 유형이 변경되고 작업이 중지된 상태에서 (동일한) 열의 이름이 변경되면, DDL 변경 사항은 DDL 기록 제어 테이블에 "열 삭제"로 표시되고 작업이 다시 시작되면 "열 추가"로 표시됩니다. 장시간 지연으로 인해 동일한 동작이 발생할 수도 있습니다.
- 작업이 중지된 동안 소스에서 수행된 CREATE TABLE 작업은 작업이 다시 시작될 때 대상에 적용되지만 DDL 기록 제어 테이블에 DDL로 기록되지 않습니다.
-
메타데이터 변경 사항과 관련된 작업(ALTER TABLE, reorg, 클러스터링된 인덱스 다시 빌드 등)은 다음 중 하나에서 수행되는 경우 예측할 수 없는 동작이 발생할 수 있습니다.
-
전체 로드 중
-또는-
-
변경 내용 처리 시작 타임스탬프와 현재 시간(즉, 사용자가 고급 실행 옵션 대화 상자에서 확인을 클릭하는 순간) 사이.
예:
IF:
지정된 변경 사항 처리 시작 시간은 오전 10시입니다.
AND:
Age라는 열이 오전 10시 10분에 Employees 테이블에 추가되었습니다.
AND:
사용자가 오전 10시 15분에 고급 실행 옵션 대화 상자에서 확인을 클릭합니다.
THEN:
10:00과 10:10 사이에 발생한 변경 사항으로 인해 CDC 오류가 발생할 수 있습니다.
정보 메모위의 어떤 경우든 영향을 가져오는 테이블을 다시 로드하여 데이터가 대상에 제대로 이동됨되도록 해야 합니다.
-
- DDL 문
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>는 기본값을 대상에 복제하지 않으며 새 열 또는 수정된 열이 NULL로 설정됩니다. 과거에 열을 추가하거나 수정한 DDL이 실행된 경우에도 이런 동작이 발생할 수 있습니다. 새 열 또는 수정된 열이 Null 허용인 경우 소스 엔드포인트는 DDL 자체를 로깅하기 전에 모든 테이블 행을 업데이트합니다. 결과적으로 Qlik Talend Data Integration은 변경 사항을 캡처하지만 대상을 업데이트하지 않습니다. 새 열 또는 수정된 열이 NULL로 설정되어 대상 테이블에 기본 키 또는 고유 인덱스가 없는 경우, 후속 업데이트에서 "영향 받는 행 없음"이라는 메시지가 생성됩니다. -
TIMESTAMP 및 DATE 정밀도 열에 대한 수정 사항은 캡처되지 않습니다.
작업 정보 보기
메뉴 막대에서 ![]() 를 클릭하여 작업 정보를 볼 수 있습니다(예:).
를 클릭하여 작업 정보를 볼 수 있습니다(예:).
-
소유자
-
공간
-
데이터 플랫폼
-
프로젝트 ID
-
데이터 작업 런타임 ID
저장소 설정
데이터 플랫폼이 클라우드 데이터 웨어하우스인 경우 저장소 데이터 작업에 대한 속성을 설정할 수 있습니다. Qlik Cloud를 데이터 플랫폼으로 사용한다면 Qlik Cloud를 데이터 플랫폼으로 사용하는 데이터 프로젝트에 대한 저장소 설정을 참조하십시오.
-
설정을 클릭합니다.
일반 설정
-
데이터베이스
데이터 소스에서 사용할 데이터베이스입니다.
-
작업 스키마
저장소 데이터 작업 스키마의 이름을 변경할 수 있습니다. 기본 이름은 저장소 작업의 이름입니다.
-
내부 스키마
내부 저장소 데이터 자산 스키마의 이름을 변경할 수 있습니다. 기본 이름은 _internal이 추가된 저장소 작업의 이름입니다.
-
스키마 이름의 기본 대문자
모든 스키마 이름에 대한 기본 대문자 사용을 설정할 수 있습니다. 데이터베이스가 대문자를 강제 사용하도록 구성된 경우 이 옵션은 효과가 없습니다.
- 모든 테이블 및 보기에 대한 접두사
이 작업으로 만들어진 모든 테이블 및 뷰에 대한 접두사를 설정할 수 있습니다.
정보 메모여러 데이터 작업에서 데이터베이스 스키마를 사용하려는 경우 고유한 접두사를 사용해야 합니다. -
기록
기록 변경 데이터를 유지하여 특정 시점에서 본 데이터를 쉽게 다시 만들 수 있습니다. 기록 보기 및 라이브 기록 보기를 사용하여 기록 데이터를 볼 수 있습니다. 기록 변경 데이터를 활성화하려면 기록 레코드 및 변경 레코드 보관 파일 유지를 선택합니다.
-
랜딩과 저장소를 비교할 때 랜딩에 존재하지 않는 레코드를 관리하는 방법을 선택할 수 있습니다.
-
삭제된 것으로 표시
이는 랜딩에 존재하지 않는 레코드의 일시 삭제를 수행합니다.
-
유지
이는 랜딩에 존재하지 않는 모든 레코드를 유지합니다.
정보 메모저장소 데이터 작업의 데이터 집합에는 기본 키 집합이 있어야 합니다. 그렇지 않은 경우 랜딩 데이터가 다시 로드될 때마다 저장소 데이터 작업에서 초기 로드가 수행됩니다. -
-
카탈로그에 게시
이 버전의 데이터를 카탈로그에 데이터 집합으로 게시하려면 이 옵션을 선택합니다. 다음에 이 작업을 준비하면 카탈로그 콘텐츠가 업데이트됩니다.
카탈로그에 대한 자세한 내용은 카탈로그 도구를 사용하여 데이터 이해를 참조하십시오.
보기 설정
-
라이브 보기
라이브 보기를 사용하여 대기 시간이 가장 짧은 테이블을 읽습니다.
실시간 보기에 대한 자세한 내용은 라이브 뷰 사용을 참조하십시오.
정보 메모라이브 보기는 표준 보기보다 효율성이 떨어지고 적용된 데이터를 다시 계산해야 하므로 더 많은 리소스가 필요합니다.
보기 유형 설정
보기 유형 설정은 Snowflake에만 적용됩니다.
-
표준 보기
대부분의 경우 표준 보기를 사용합니다.
-
Snowflake 보안 보기
기본 테이블의 모든 사용자에게 노출되어서는 안 되는 중요한 데이터에 대한 액세스를 제한하기 위해 만든 보기 등, 데이터 개인정보 보호 또는 중요한 정보 보호를 위해 지정된 보기에는 Snowflake 보안 보기를 사용합니다.
정보 메모 Snowflake 보안 보기는 표준 보기보다 실행 속도가 느릴 수 있습니다.
런타임 설정
-
병렬 실행
전체 로드에 대한 최대 연결 수를 1에서 5까지 설정할 수 있습니다.
-
웨어하우스
클라우드 데이터 웨어하우스의 이름입니다. 이 설정은 Snowflake에만 적용됩니다.
테이블 유형 설정
이러한 설정은 Snowflake를 데이터 플랫폼으로 사용하는 프로젝트에서만 사용할 수 있습니다.
-
테이블 유형
사용할 테이블 유형을 선택할 수 있습니다.
-
Snowflake 테이블
-
Snowflake 관리 Iceberg 테이블
Snowflake 외부 볼륨에서 외부 볼륨의 기본 이름을 설정해야 합니다.
-
-
사용할 클라우드 저장소 폴더
스테이징 영역에 데이터를 랜딩할 때 사용할 폴더를 선택합니다.
-
기본 폴더
그러면 기본 이름이 <프로젝트 이름>/<데이터 작업 이름>인 폴더가 만들어집니다.
-
루트 폴더
저장소의 루트 폴더에 데이터를 저장합니다.
-
폴더
사용할 폴더 이름을 지정합니다.
-
-
Snowflake Open Catalog와 동기화
이 기능을 활성화하면 Snowflake Open 카탈로그가 클라우드 파일 저장소에 있는 파일을 관리할 수 있습니다.
스키마 진화
스키마에서 다음 유형의 DDL 변경을 처리하는 방법을 선택합니다. 스키마 진화 설정을 변경한 경우 작업을 다시 준비해야 합니다. 아래 표에서는 지원되는 DDL 변경에 대해 사용할 수 있는 작업을 설명합니다.
| DDL 변경 | 대상에 적용 | 무시 | 작업 중지 |
|---|---|---|---|
| 열 추가 | 예 | 예 | 예 |
| 테이블 만들기
선택 규칙을 사용하여 패턴과 일치하는 데이터 집합을 추가한 경우 패턴을 충족하는 새 테이블이 감지되어 추가됩니다. |
예 | 예 | 예 |
Qlik Cloud를 데이터 플랫폼으로 사용하는 데이터 프로젝트에 대한 저장소 설정
데이터 플랫폼이 Qlik Cloud인 경우 저장소에서 사용할 폴더를 데이터 플랫폼으로 설정할 수 있습니다.
-
설정을 클릭합니다.
-
저장소에서 사용할 폴더를 선택합니다.
-
준비가 되면 확인을 클릭합니다.
저장소 데이터 작업에 대한 작업
작업 메뉴에서 저장소 데이터 작업에 대해 다음 작업을 수행할 수 있습니다.
-
열기
이렇게 하면 저장소 데이터 작업이 열립니다. 데이터 작업에 대한 테이블 구조 및 세부 정보를 보고 전체 로드 및 일괄 변경에 대한 상태를 모니터링할 수 있습니다.
-
편집
작업의 이름과 설명을 편집하고 태그를 추가할 수 있습니다.
-
삭제
데이터 작업이 실행 중이 아니고 동일한 프로젝트의 다운스트림 작업에 종속성이 없는 경우 데이터 작업을 삭제할 수 있습니다.
-
프로젝트의 파이프라인 프로젝트 보기에서 작업에서
 을 클릭하고 삭제를 선택합니다.
을 클릭하고 삭제를 선택합니다.
이 작업으로 생성된 아티팩트(테이블 및 뷰)도 유지하도록 선택하지 않는 한 삭제됩니다.
정보 메모유지하는 아티팩트는 더 이상 작업에 의해 업데이트되지 않습니다. -
-
준비
이는 실행을 위한 작업을 준비합니다. 여기에는 다음이 포함됩니다.
-
설계가 유효한지 유효성을 검사합니다.
-
설계와 일치하도록 물리적 테이블과 뷰를 만들거나 변경합니다.
-
데이터 작업을 위한 SQL 코드 생성
-
작업 출력 데이터 집합에 대한 카탈로그 항목 만들기 또는 변경.
화면 하단의 준비 진행률에서 진행률을 확인할 수 있습니다.
-
-
데이터 집합 유효성 검사
이렇게 하면 데이터 작업에 포함된 모든 데이터 집합의 유효성을 검사합니다.
유효성 검사 및 조정을 확장하여 모든 유효성 검사 오류 및 디자인 변경 사항을 확인합니다.
-
테이블 다시 만들기
이것은 소스에서 데이터 집합을 다시 만듭니다. 테이블을 다시 만들 때 다운스트림 작업은 소스 데이터 집합에서 자르기 및 다시 로드 작업이 발생한 것처럼 반응합니다. 자세한 내용은 저장소 데이터 작업 문제 해결을 참조하십시오.
-
중지
데이터 작업의 작동을 중지할 수 있습니다. 데이터 작업은 테이블 업데이트를 계속하지 않습니다.
정보 메모이 옵션은 데이터 작업이 실행 중일 때 사용할 수 있습니다. -
재개
중지된 지점에서 데이터 작업의 작업을 재개할 수 있습니다.
정보 메모이 옵션은 데이터 작업이 중지되었을 때 사용할 수 있습니다. -
데이터 변환
규칙 및 사용자 지정 SQL을 기반으로 재사용 가능한 행 수준 변환을 만듭니다. 이렇게 하면 데이터 변환 작업이 만들어집니다.
-
데이터 마트 만들기
데이터 작업을 활용하기 위해 데이터 마트를 만듭니다. 이렇게 하면 데이터 마트 데이터 작업이 만들어집니다.
제한 사항
-
데이터 작업에 데이터 집합이 포함되어 있고 연결의 매개 변수(예: 사용자 이름, 데이터베이스 또는 스키마)를 변경하는 경우 데이터가 새 위치에 있다고 가정합니다. 이 경우가 아닌 경우 다음 중 하나를 수행할 수 있습니다.
-
소스에 있는 데이터를 새 위치로 이동합니다.
-
동일한 설정으로 새 데이터 작업을 만듭니다.
-
-
Qlik Cloud(QVD)를 대상으로 하는 프로젝트의 저장소 작업에서 기본 키를 변경할 수 없습니다. 랜딩 작업에서 기본 키를 업데이트하고 랜딩 작업을 다시 만든 다음 저장소 작업을 다시 만듭니다.
-
Iceberg 저장소를 사용하는 경우 JSON 데이터 열은 STRING으로 저장됩니다.