
データセットの保管
ストレージ データ タスクを使用してデータセットを保管できます。ストレージ データ タスクは、ランディング データ タスクによって、クラウド ランディング エリアにランディングされたデータを消費します。たとえば、分析アプリケーションでそれらのテーブルを使用できます。
-
ランディング データ タスクのステータスが Ready to prepare 以上の場合、ストレージ データ タスクを設計できます。
-
ランディング データ タスクのステータスが Ready to run 以上の場合、ストレージ データ タスクを準備できます。
ストレージ データ タスクは、消費されたランディング データ タスクと同じ操作モード ([フル ロード] または [フル ロード & CDC]) を使用します。構成プロパティは、2 つの操作モード間、および監視オプションと制御オプションで異なります。フル ロードのみでクラウド ターゲット ランディング データ タスクを使用する場合、ストレージ データ タスクは、物理テーブルを生成する代わりに、ランディング テーブルへのビューを作成します。
データ ウェアハウスにテーブルを保存するだけでなく、データ プラットフォームによって管理される Iceberg テーブルとしてテーブルを保存することもできます。このオプションは現在、Snowflake プロジェクトでのみ使用できます。これは、タスク設定の [テーブル タイプ] で [Snowflake 管理の Iceberg テーブル] を選択することで可能になります。
ストレージ データ タスクの作成
ストレージ データ タスクは、次の 3 つの方法で作成できます。
-
ランディング データ タスクで [...] をクリックし、[データの保存] を選択して、このランディング データ アセットに基づいてストレージ データ タスクを作成します。
-
パイプライン プロジェクトで、 [作成] をクリックし、 [データを保存] をクリックします。この場合、使用するランディング データ タスクを指定する必要があります。
-
データをオンボードすると、ストレージ データ タスクが作成されます。これは、データのオンボーディング時にも作成されるランディング データ タスクに接続されます。
詳細については、「データ ウェアハウスへのデータのオンボーディング」を参照してください。
ストレージ データ タスクを作成したら、次のようにします。
-
[...] をクリックして [開く] を選択し、ストレージ データ タスクを開きます。
ストレージ データ タスクが開かれ、ランディング データ アセットのテーブルに基づいて出力データセットをプレビューできます。 -
変換、データのフィルタリング、列の追加など、含まれるデータセットに必要なすべての変更を加えます。
詳細については、「データセットを管理」を参照してください。
-
必要な変換を追加したら、[データセットの検証] をクリックしてデータセットを検証できます。検証でエラーが見つかった場合は、先に進む前にエラーを修正してください。
詳細については、「データセットの検証と調整」を参照してください。
-
データ モデルを作成
[モデル] をクリックして、含まれるデータセット間の関係を設定します。
詳細については、「データ モデルの作成」を参照してください。
-
[準備] をクリックして、データ タスクと必要なすべてのアーティファクトを準備します。これには少し時間がかかる場合があります。
画面下部の [準備の進捗状況] で進捗状況を確認できます。
-
ステータスが [実行準備完了] と表示されたら、データ タスクを実行できます。
[実行] をクリックします。
データ タスクは、データを格納するためのデータセットの作成を開始します。
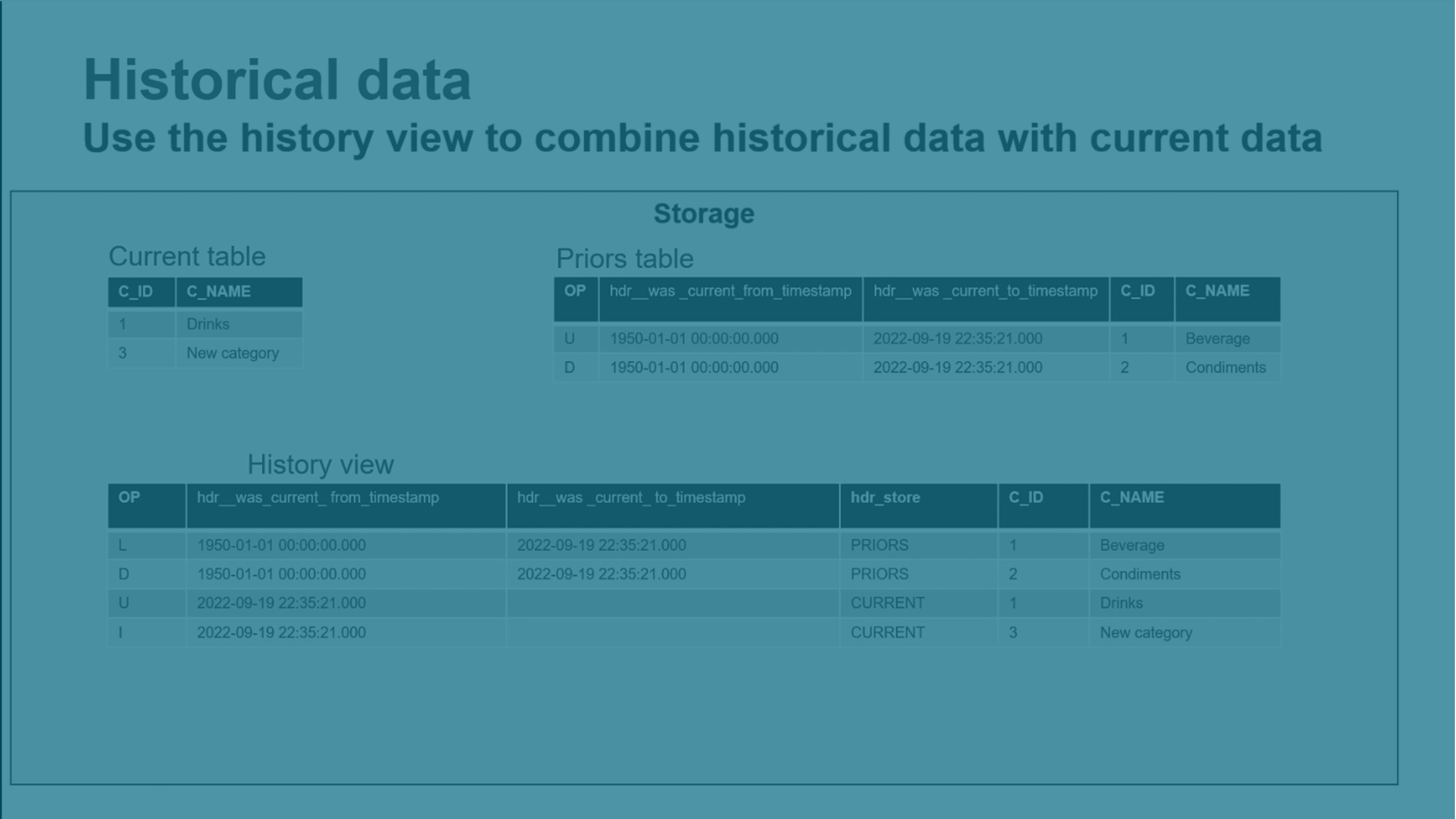
履歴データの保持
タイプ 2 の履歴変更データを保持して、特定の時点でのデータを簡単に再作成できるようにすることができます。これは、完全な履歴データ ストア (HDS) も作成します。
-
タイプ 2 がゆっくりと軸に変化することはサポートされています。
-
変更されたレコードがマージされると、変更されたデータを保存するための新しいレコードが作成され、古いレコードはそのまま残ります。
-
新しい HDS レコードは自動的にタイムスタンプが付けられ、トレンド分析およびその他の時間関連の分析データ マートが作成できるようになります。
クリックして、履歴データを有効にできます。
-
データ搭載時に、 [設定] で、現在のデータと以前のデータの履歴の両方を表示するレプリケーション
-
ストレージ タスクの [設定] ダイアログで、変更履歴および変更記録のアーカイブを保持します。
HDS データは内部データ スキーマの Prior テーブルに保存されます。外部データ スキーマで履歴ビューとライブ履歴ビューを使用して、履歴データを表示できます。
-
履歴ビューは、Current テーブルと Prior テーブルからのデータをマージします。このビューには、マージされたすべての変更が含まれます。
-
ライブ履歴ビューは、Current テーブル、Prior テーブル、および Changes テーブルからのデータをマージします。このビューには、マージされたすべての変更も含まれます。
詳細については、「クラウド データ ウェアハウスのデータセット アーキテクチャ」を参照してください。
保存
ストレージ タスクのスケジュール
ストレージ タスクを定期的に更新するようにスケジュールできます。
-
入力ランディング データ タスクがフル ロードおよび CDC を使用している場合、時間ベースのスケジュールのみを設定できます。
-
入力ランディング データ タスクがフル ロードを使用している場合、時間ベースのスケジュールを設定するか、入力ランディング データ タスクの実行が完了したときに実行するようにタスクを設定できます。
情報メモフル ロードを使用して入力ランディング データ タスクで時間ベースのスケジュールを実行する場合は、ランディング タスクの実行中に、ランディングで完了したすべてのテーブルを使用できることを考慮してください。これにより、ランディングとストレージを同時に実行できるようになり、合計ロード時間を改善できます。 -
プロジェクトが Iceberg テーブルにデータを保存する場合は、時間ベースのスケジュールを設定したり、変更データ パーティションが閉じられたときにタスクを実行するように設定したりできます。
データ タスクの [...] をクリックし、[スケジュール] を選択してスケジュールを作成します。既定のスケジュール設定は、パイプライン プロジェクトの設定から継承されます。設定の詳細については、「ストレージのデフォルト」を参照してください。スケジュールを有効にするには、常に [スケジュール] を [オン] に設定する必要があります。
時間ベースのスケジュール
ランディングの種類に関係なく、時間ベースのスケジュールを使用してストレージ データ タスクを実行できます。
-
[データ タスクを実行] で、[特定の時刻] を選択します。
時間、日、週、または月単位でスケジュールを作成できます。
イベント ベースのスケジュール
-
[データ タスクを実行] で、[入力データ タスクのいずれかが正常に完了した場合] を選択します。
ストレージ タスクは、入力ランディング データ タスクが正常に完了するたびに実行されます。
ストレージ タスクの監視
[監視] をクリックすると、ストレージ タスクのステータスと進行状況を監視できます。
詳細については、「個々のデータ タスクの監視」を参照してください。
ストレージ データ タスクのトラブルシューティング
ストレージ データ タスクの 1 つ以上のテーブルに問題がある場合、データのリロードまたは再作成が必要になる場合があります。これを実行するためには、オプションがいくつかあります。どのオプションを使用するか、次の順序で考慮します。
-
ランディングでデータセットをリロードできます。ランディングでデータセットをリロードすると、ストレージで比較処理がトリガーされ、タイプ 2 の履歴を保持したままデータが修正されます。このオプションは、次のような場合にも考慮する必要があります。
-
フル ロードが実行されてから時間が経過しており、変更点が多い場合。
-
ランディング エリアのメンテナンスの一環として、処理済みのフル ロードと変更テーブルのレコードが削除された場合。
-
-
ストレージ データ タスクでデータをリロードできます。
履歴データが有効になっている場合、ストレージでのリロードによって履歴データが失われることがあります。これが問題となる場合は、代わりにソースからランディングをリロードすることを検討してください。
-
テーブルを再作成できます。これにより、ソースからデータセットが再作成されます。
-
[...]、 [テーブルを再作成] の順にクリックします。テーブルを再作成すると、ダウンストリーム タスクは、ソース データセットで切り捨てとリロードのアクションが実行されたかのように動作します。
情報メモ個々のテーブルに問題がある場合は、最初にテーブルを再作成するのではなく、リロードしてみることをお勧めします。テーブルを再作成すると、過去のデータが失われる可能性があります。重大な変更があった場合は、データをリロードできるよう、再作成されたデータ タスクを使用するダウンストリームのデータ タスクを準備することも必要です。
-
データのリロード
テーブルの手動リロードを実行できます。これは、1 つ以上のテーブルに問題がある場合に便利です。
-
データ タスクを開き、 [監視] タブを選択します。
-
リロードするテーブルを選択します。
-
[テーブルのリロード] をクリックします。
リロードは次にタスクが実行されるときに行われ、次のように実行されます。
-
テーブルを切り捨てます。
-
ランディング データをテーブルにロードします。
-
リロード時間から蓄積された変更をロードします。
一般に、代わりにランディング時にデータセットを再読み込みすることがベスト プラクティスです。これは特に次の場合に当てはまります。
-
履歴データが有効になっている場合、ストレージでのリロードによって履歴データが失われることがあります。ランディングでデータセットをリロードすると、ストレージで比較処理がトリガーされ、タイプ 2 の履歴を保持するデータが修正されます。
-
フル ロードが行われてから時間が経過しており、変更点が多い場合。
-
ランディング エリアのメンテナンスの一環として、処理済みのフル ロードと変更テーブルのレコードが削除された場合。
変更を適用し、バックデートを回避するために、ダウンストリーム タスクがリロードされます。切り捨てとリロードによってリロードが実行される場合、すべてのダウンストリーム オブジェクトも切り捨てとリロードによってリロードされます。
ランディングまたはストレージ データ タスクのリロード後のダウンストリームへの影響

ダウンストリームへの影響は、実行されたリロード操作のタイプと、直接のダウンストリーム データセットのタイプによって異なります。標準処理とは、特定のデータセットに対して構成された方法を使用して、データセットが反応してデータを処理することを意味します。
-
ダウンストリームの変換タスクでは次のようになります。
データセット変換は、切り捨てとリロードによってリロードされます。
SQL 変換と変換フローは、フル ロードと比較し、変更を適用することによってリロードされます。
-
ストレージ タスクの直後にあるデータ マート タスクは、切り捨てとロードによってリロードされます。
[リロードをキャンセル] をクリックすると、リロードがペンディングされているテーブルのリロードをキャンセルできます。すでにリロードされているテーブルに影響することはなく、現在実行中のリロードは完了します。
スキーマの進化
スキーマの進化により、複数のデータ ソースに対する構造的な変更を簡単に検出し、それらの変更がタスクにどのように適用されるかを制御できます。スキーマの進化を使用すると、ソース データ スキーマに対して実行された DDL 変更を検出できます。一部の変更を自動的に適用することもできます。
変更タイプごとに、タスク設定の [スキーマの進化] セクションで変更を処理する方法を選択できます。変更を適用、変更を無視、テーブルを一時停止、またはタスクの処理を停止できます。
変更タイプごとに、DDL 変更を処理するために使用するアクションを設定できます。すべての変更タイプで、一部のアクションは使用できません。
-
ターゲットに適用
変更を自動的に適用します。
-
無視
変更を無視します。
-
テーブルを一時停止
テーブルを一時停止します。[モニター] では、テーブルがエラーとして表示されます。
-
タスクを停止
タスクの処理を停止します。これは、すべてのスキーマ変更を手動で処理する場合に便利です。これにより、スケジュールも停止され、スケジュール済みの実行は行われなくなります。
次の変更がサポートされています。
-
列を追加
-
選択パターンに一致するテーブルを作成する
[選択ルール] を使用してパターンに一致するデータセットを追加した場合、パターンを満たす新しいテーブルが検出され、追加されます。
タスク設定の詳細については、「スキーマの進化」を参照してください。
スキーマの進化に関する制限
スキーマの進化には次の制限が適用されます。
-
スキーマの進化は、更新方法として CDC を使用する場合にのみサポートされます。
-
スキーマの進化の設定を変更した場合は、再度タスクを準備する必要があります。
-
テーブルの名前を変更すると、スキーマの進化はサポートされません。この場合、タスクを準備する前にメタデータを更新する必要があります。
-
タスクを設計している場合は、スキーマの進化の変更を受け取るためにブラウザを更新する必要があります。変更があった場合に通知を受け取るように設定できます。
-
ランディング タスクでは、列のドロップはサポートされていません。列をドロップして追加すると、テーブル エラーが発生します。
-
ランディング タスクでは、テーブルのドロップ操作を実行してもテーブルはドロップされません。テーブルをドロップしてからテーブルを追加しても、古いテーブルが切り捨てられるだけで、新しいテーブルは追加されません。
-
ターゲット データベースのサポートによっては、すべてのターゲットで列の長さを変更できない場合があります。
-
列名が変更されると、その列を使用して定義された明示的な変換は列名に基づいているため反映されません。
-
メタデータの更新に対する制限は、スキーマの進化にも適用されます。
-
タスクにまだ準備されていない設計変更が含まれており、タスクの実行時にソース スキーマの進化変更が検出された場合、競合を回避するためにタスクは停止されます。ペンディングの設計変更を準備し、タスクを再度実行します。
DDL の変更をキャプチャする場合、次の制限が適用されます。
-
ソース データベースで一連の操作が高速に実行されると (例: DDL > DML > DDL)、Qlik Talend Data Integration はログを間違った順序で解析し、データが欠落したり、予期しない動作が発生したりする可能性があります。このような事態が発生する可能性を最小限に抑えるベストプラクティスとして、次の操作を実行する前に、変更がターゲットに適用されるまで待機してください。
たとえば、変更キャプチャ中に、ソース テーブルの名前が立て続けに複数回変更されると (2 回目の操作で元の名前に戻される)、ターゲット データベースにテーブルが既に存在するというエラーが発生する可能性があります。
- タスクで使用されるテーブルの名前を変更してからタスクを停止すると、タスクの再開後に Qlik Talend Data Integration はそのテーブルに加えられた変更をキャプチャしません。
-
タスクが停止している間にソース テーブルの名前を変更することはサポートされていません。
- テーブルのプライマリ キー列の再割り当てはサポートされていません (したがって、DDL 履歴コントロール テーブルには書き込まれません)。
- タスクが停止している間に列のデータ型が変更され、(同じ) 列の名前が変更されると、タスクが再開されたときに DDL の変更が DDL 履歴コントロール テーブルに「列をドロップ」として表示され、その後「列を追加」として表示されます。待機時間が長引いた場合にも、同じ動作が起こる可能性があることに注意してください。
- タスクが停止している間にソースで実行された CREATE TABLE 操作は、タスクが再開されるとターゲットに適用されますが、DDL 履歴コントロール テーブルに DDL として記録されません。
-
メタデータの変更に関連する操作 (ALTER TABLE、再編成、クラスター化インデックスの再構築など) は、次のいずれかの方法で実行された場合、予期しない動作を引き起こす可能性があります。
-
フル ロード時
-または-
-
[プロセスの変更開始] のタイムスタンプと現在の時刻 (つまり、ユーザーが [詳細な実行オプション] ダイアログで [OK] をクリックした時点) の間。
例:
次の場合:
指定された [プロセスの変更開始] 時刻は午前 10:00 です。
および:
午前 10 時 10 分に、 [年齢] という列が [従業員] テーブルに追加されました。
および:
ユーザーは午前 10 時 15 分に [詳細な実行オプション] ダイアログで [OK] をクリックします。
その結果:
10:00 から 10:10 の間に発生した変更により、CDC エラーが発生する可能性があります。
情報メモ上記のいずれの場合でも、データがターゲットに適切に 移動済み されるように、影響を受けるテーブルをリロードする必要があります。
-
- DDL ステートメント
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>は、既定値をターゲットにレプリケートせず、新しい列または変更された列は NULL に設定されます。列を追加または変更した DDL が過去に実行された場合でも、発生する可能性があることに注意してください。新しい列または変更された列が NULL 可能である場合、ソース エンドポイントは DDL 自体をログに記録する前にすべてのテーブル行を更新します。その結果、Qlik Talend Data Integration は変更をキャプチャしますが、ターゲットは更新しません。新しい列または変更された列が NULL に設定されているため、ターゲット テーブルにプライマリ キーまたは一意のインデックスがない場合、後続の更新では「影響を受ける行は 0 行です」というメッセージが生成されます。 -
TIMESTAMP および DATE 精度列への変更はキャプチャされません。
タスク情報の表示
メニュー バーで ![]() をクリックして、次のようなタスク情報を表示します。
をクリックして、次のようなタスク情報を表示します。
-
所有者
-
スペース
-
データ プラットフォーム
-
プロジェクトID
-
データ タスク実行 ID
ストレージの設定
データ プラットフォームがクラウド データ ウェアハウスの場合、ストレージ データタスクのプロパティを設定することができます。Qlik Cloudをデータプラットフォームとして使用する場合、Qlik Cloud をデータ プラットフォームとするデータ プロジェクトにおけるストレージ設定を参照してください。
-
[Settings] (設定)をクリックします。
一般設定
-
[Database] (データベース)
データ ソースで使用するデータベース。
-
タスクのスキーマ
ストレージ データ タスクのスキーマの名前を変更できます。デフォルト名は、ストレージ タスクの名前です。
-
内部スキーマ
内部ストレージ データ アセット スキーマの名前を変更できます。デフォルト名は、ストレージ タスクの名前に _internal を追加したものです。
-
スキーマ名を既定で大文字化
すべてのスキーマ名の既定の大文字と小文字を設定できます。データベースが大文字と小文字を強制するように設定されている場合、このオプションは効果がありません。
- すべてのテーブルとビューのプレフィックス
このタスクで作成したすべてのテーブルとビューにプレフィックスを設定できます。
情報メモ複数のデータ タスクでデータベース スキーマを使用する場合は、一意のプレフィックスを使用する必要があります。 -
履歴
過去の変更データを保持して、特定の時点でのデータを簡単に再作成できるようにすることができます。履歴ビューとライブ履歴ビューを使用して、履歴データを表示できます。履歴の保持および変更記録のアーカイブを選択して、履歴変更データを有効にします。
-
ストレージとランディングを比較すると、ランディングに存在しないレコードをどのように管理するかを選択できます。
-
削除済みとしてマーク
これにより、ランディングに存在しないレコードのソフト削除が実行されます。
-
維持
これにより、ランディングに存在しないすべての記録が保持されます。
情報メモストレージ データ タスク内のデータセットには、主キー セットが必要です。そうでない場合、ランディング データがリロードされるたびに、ストレージ データ タスクに対して初期ロードが実行されます。 -
-
カタログに公開する
このオプションを選択して、データのこのバージョンをデータセットとしてカタログに公開します。カタログのコンテンツは、このタスクを次回準備する際に更新されます。
カタログの詳細については、カタログ ツールの使用によるデータの理解 を参照してください。
ビューの設定
-
ライブ ビュー
ライブ ビューを使用して、待機時間が最小のテーブルを読み取ります。
ライブ ビューの詳細については、「ライブ ビューの使用」を参照してください。
情報メモライブ ビューは標準ビューよりも効率が低く、適用されたデータを再計算する必要があるため、より多くのリソースが必要になります。
ビュー タイプの設定
ビュー タイプの設定は Snowflake にのみ適用されます。
-
標準ビュー
ほとんどのケースでは、標準ビューを使用します。
-
Snowflake セキュア ビュー
基礎となるテーブルのすべてのユーザーに公開すべきではない機密データへのアクセスを制限するために作成されたビューなど、データのプライバシーまたは機密情報の保護のために指定されたビューには、Snowflake のセキュア ビューを使用します。
情報メモ Snowflake セキュアビューは、標準ビューよりも実行速度が遅くなる場合があります。
実行時間の設定
-
並列実行
フル ロードの最大接続数を 1 から 5 の数値に設定できます。
-
ウェアハウス
クラウド データ ウェアハウスの名前です。この設定は Snowflake にのみ適用されます。
テーブル タイプの設定
これらの設定は、データ プラットフォームとして Snowflake を使用するプロジェクトでのみ使用できます。
-
[Table type] (テーブルタイプ)
使用するテーブル タイプを選択できます。
-
Snowflake テーブル
-
Snowflake 管理の Iceberg テーブル
[Snowflake 外部ボリューム] で外部ボリュームのデフォルト名を設定する必要があります。
-
-
使用するクラウド ストレージ フォルダー
ステージング エリアにデータをランディングするときに使用するフォルダーを選択できます。
-
既定のフォルダー
既定の名前 <project name>/<data task name> のフォルダーが作成されます。
-
ルート フォルダー
ストレージのルート フォルダーにデータを保存します。
-
フォルダー
使用するフォルダーの名前を指定します。
-
-
Snowflake Open Catalog と同期
これを有効にすると、Snowflake Open Catalog がクラウド ファイル ストレージ内のファイルを管理できるようになります。
スキーマの進化
スキーマ内の次のタイプの DDL 変更を処理する方法を選択します。スキーマの進化の設定を変更した場合は、再度タスクを準備する必要があります。次の表には、サポートされている DDL 変更に対して使用できるアクションが示されています。
| DDL の変更 | ターゲットに適用 | 無視 | タスクを停止 |
|---|---|---|---|
| 列を追加 | 可 | 可 | 可 |
| テーブルを作成
[選択ルール] を使用してパターンに一致するデータセットを追加した場合、パターンを満たす新しいテーブルが検出され、追加されます。 |
可 | 可 | 可 |
Qlik Cloud をデータ プラットフォームとするデータ プロジェクトにおけるストレージ設定
データ プラットフォームがデータ プラットフォームとしてQlik Cloudである場合に、ストレージのどのフォルダーを使用するかを設定できます。
-
[Settings] (設定)をクリックします。
-
保存する時に使用するフォルダーを選択します。
-
準備ができたら、[OK] をクリックします。
ストレージ データ タスクの操作
タスク メニューからストレージ データ タスクに対して以下の操作を行うことができます。
-
開く
これにより、ストレージ データ タスクが開きます。データ タスクに関するテーブル構造と詳細を表示し、変更の全ロードとバッチのステータスを監視できます。
-
編集
タスクの名前と説明を編集したり、タグを追加したりできます。
-
[Delete] (削除)
データ タスクが実行中でなく、同じプロジェクト内のダウンストリーム タスクへの依存関係がない場合は、データ タスクを削除できます。
-
プロジェクトの [パイプライン プロジェクト] ビューで、タスク上の
 をクリックし、 [削除] を選択します。
をクリックし、 [削除] を選択します。
このタスクによって作成されたアーティファクト (テーブルおよびビュー) は、保持を選択しない限り削除されます。
情報メモ保持するアーティファクトは、タスクによって更新されなくなることに留意してください。 -
-
[準備]
これにより、タスクの実行準備が整います。準備には次が含まれます。
-
設計が有効であることを検証する。
-
設計に合わせて物理的なテーブルとビューを作成または変更する。
-
データ タスクの SQL コードを生成する。
-
タスク出力データセットのカタログ エントリを作成または変更する。
画面下部の [準備の進捗状況] で進捗状況を確認できます。
-
-
データセットを検証する
これにより、データ タスクに含まれるすべてのデータセットが検証されます。
[Validate and adjust (検証と調整)] を展開して、すべての検証エラーと設計変更を確認します。
-
テーブルを再作成
これにより、ソースからデータセットが再作成されます。テーブルを再作成すると、ダウンストリーム タスクは、ソース データセットで切り捨てとリロードのアクションが実行されたかのように動作します。詳細については、「ストレージ データ タスクのトラブルシューティング」を参照してください。
-
停止
データ タスクの操作を停止できます。データ タスクはテーブルを更新し続けることはありません。
情報メモこのオプションは、データ タスクの実行中に使用できます。 -
再開
データ タスクは停止した時点から操作を再開できます。
情報メモこのオプションは、データ タスクが停止している場合に使用できます。 -
データを変換
ルールとカスタム SQL に基づいて、再利用可能な行レベルの変換を作成します。これにより変換データ タスクが作成されます。
-
データ マートを作成
データ マートを作成して、データ タスクを活用します。これによりデータ マート データ タスクが作成されます。
制限事項
-
データ タスクにデータセットが含まれていて、接続のパラメーター (ユーザー名、データベース、スキーマなど) を変更した場合、データは新しい場所に存在すると想定されます。そうでない場合は、次のいずれかを実行できます。
-
ソース内のデータを新しい場所に移動します。
-
同じ設定で新しいデータ タスクを作成します。
-
-
Qlik Cloud (QVD) をターゲットとするプロジェクトのストレージ タスクの主キーを変更することはできません。ランディング タスクの主キーを更新し、ランディング タスクを再作成してから、ストレージ タスクを再作成します。
-
Iceberg ストレージを使用する場合、JSON データ列は STRING として保存されます。