
Storing datasets
You can store datasets using a storage data task. The storage data task consumes the data that was landed to the cloud landing area by a landing data task. You can use the tables in an analytics application for example.
-
You can design a storage data task when the status of the landing data task is at least Ready to prepare.
-
You can prepare a storage data task when the status of the landing data task is at least Ready to run.
The storage data task will use the same mode of operation (Full load or Full load & CDC) as the consumed landing data task. Configuration properties are different between the two modes of operation, as well as monitor and control options. If you use a cloud target landing data task with full load only, the storage data task will create views to the landing tables instead of generating physical tables.
In addition to storing tables in the data warehouse, you can also store tables as Iceberg tables that are managed by the data platform. This option is currently only available with Snowflake projects. This is possible by selecting Snowflake-managed Iceberg tables under Table type in the task settings.
Creating a storage data task
You can create a storage data task in three ways:
-
Click ... on a landing data task and select Store data to create a storage data task based on this landing data asset.
-
In a pipeline project, click Create and then Store data. In this case you will need to specify which landing data task to use.
-
When you onboard data, a storage data task is created. It is connected to the landing data task, which is also created when onboarding data.
For more information, see Onboarding data to a data warehouse.
When you have created the storage data task:
-
Open the storage data task by clicking ... and selecting Open.
The storage data task is opened and you can preview the output datasets based on the tables from the landing data asset. -
Make all required changes to the included datasets, such as transformations, filtering data, or adding columns.
For more information, see Managing datasets.
-
When you have added the transformations that you want, you can validate the datasets by clicking Validate datasets. If the validation finds errors, fix the errors before proceeding.
For more information, see Validating and adjusting the datasets.
-
Create a data model
Click Model to set the relationships between the included datasets.
For more information, see Creating a data model.
-
Click Prepare to prepare the data task and all required artifacts. This can take a little while.
You can follow the progress under Preparation progress in the lower part of the screen.
-
When the status displays Ready to run, you can run the data task.
Click Run.
The data task will now start creating datasets to store the data.
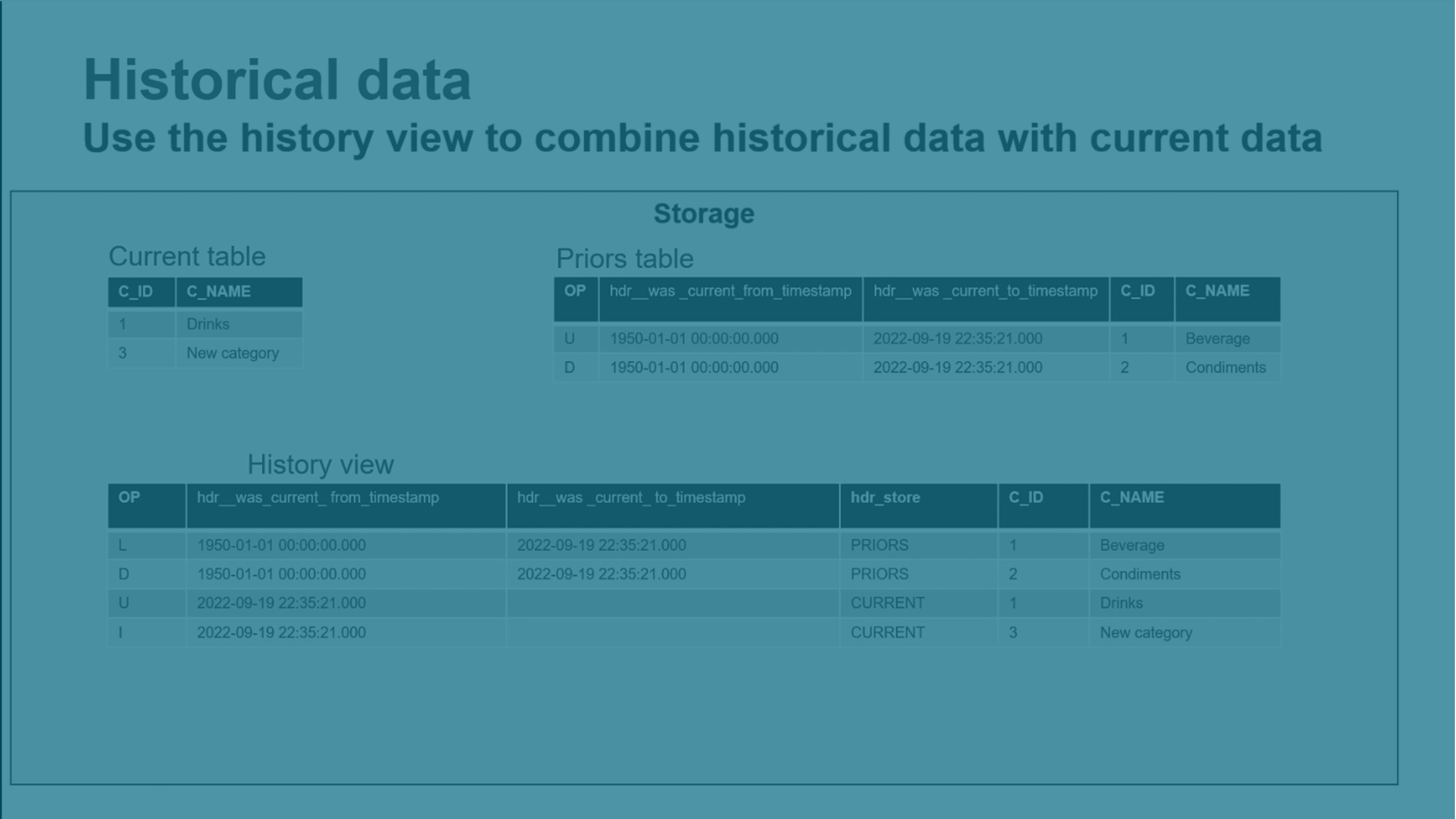
Keeping historical data
You can keep type 2 historical change data to let you easily recreate data as it looked at a specific point in time. This creates a full historical data store (HDS).
-
Type 2 slowly changing dimensions are supported.
-
When a changed record is merged, it creates a new record to store the changed data and leaves the old record intact.
-
New HDS records are automatically time-stamped, to let you create trend analysis and other time-oriented analytic data marts.
You can enable historical data by clicking:
-
Replication with both current data and history of previous data in Settings when you onboard data.
-
Keep historical change records and change record archive in the Settings dialog of a storage task.
HDS data is stored in the Prior table in the internal data schema. You can use the history views and live history views in the external data schema to view historical data.
-
The history view merges data from the Current table and the Prior table. This view includes all changes that are merged.
-
The live history view merges data from the Current table, the Prior table, and the Changes table. This view also includes all changes that are not yet merged.
For more information, see Dataset architecture in a cloud data warehouse.
Storing
Scheduling a storage task
You can schedule a storage task to be updated periodically.
-
If the input landing data task is using Full load and CDC, you can only set a time based schedule.
-
If the input landing data task is using Full load, you can either set a time based schedule, or set the task to run when the input landing data task has completed running.
Information noteWhen you run a time based schedule with an input landing data task using Full load, consider that every completed table in landing is available while the landing task is still running. This allows you to run landing and storage concurrently, which can improve the total load time. -
If the project stores data in Iceberg tables, you can set a time-based schedule, or set the task to run when any change data partition is closed.
Click ... on a data task and select Scheduling to create a schedule. The default scheduling setting is inherited from the settings in the pipeline project. For more information about default settings, see Storage defaults. You always need to set Scheduling to On to enable the schedule.
Time based schedules
You can use a time based schedule to run the storage data task regardless of the type of landing..
-
Select At specific time in Run the data task.
You can set an hourly, daily, weekly or monthly schedule.
Event based schedules
-
Select On successful completion of any input data task in Run the data task.
The storage task will run every time the input landing data task has completed successfully.
Monitoring a storage task
You can monitor the status and progress of a storage task by clicking on Monitor.
For more information, see Monitoring an individual data task.
Troubleshooting a storage data task
When there are issues with one or more tables in a storage data task, you may need to reload or recreate the data. There are a few options available to perform this. Consider which option to use in the following order:
-
You can reload the dataset in landing. Reloading the dataset in landing will trigger the compare process in storage and correct data while retaining type 2 history. This option should also be considered when:
-
The full load was performed a long time ago, and there is a large number of changes.
-
If full load and change table records that have been processed have been deleted as part of maintenance of the landing area.
-
-
You can reload data in the storage data task.
If historical data is enabled, a reload in storage may cause a loss of historical data. If this is an issue, consider reloading the landing from source instead.
-
You can recreate tables. This recreates the datasets from the source.
-
Click ... and then click Recreate tables. When recreating a table, the downstream task will react as if a truncate and reload action occurred on the source datasets.
Information noteIf there are problems with individual tables, it is recommended to first try reloading the tables instead of recreating them. Recreating tables may cause a loss of historical data. If there are breaking changes, you must also prepare downstream data tasks that consume the recreated data tasks to reload the data.
-
Reloading data
You can perform a manual reload of tables. This is useful when there are issues with one or more tables.
-
Open the data task and select the Monitor tab.
-
Select the tables that you want to reload.
-
Click Reload tables.
The reload will happen the next time the task is run, and is performed by:
-
Truncating the tables.
-
Loading the landing data to the tables.
-
Loading the changes accumulated from the reload time.
In general it is best practice to reload the dataset in landing instead. This is especially true in the following cases:
-
If historical data is enabled, a reload in storage may cause a loss of historical data. Reloading the dataset in landing will trigger the compare process in storage and correct data retaining type 2 history.
-
When the full load was performed a long time ago, and there is a large number of changes.
-
If full load and change table records that have been processed have been deleted as part of maintenance of the landing area.
Downstream tasks will be reloaded to apply changes, and to avoid backdating. If a reload is performed by truncating and reloading, all downstream objects will be reloaded by truncating and reloading as well.
Downstream impact after reloading a Landing or Storage data task

The impact downstream depends on the type of reload operation executed, and the type of immediate downstream dataset. Standard processing means that the dataset will react and process data using the configured method for the specific dataset.
-
In downstream Transform tasks:
Dataset transformations are reloaded by truncating and loading.
SQL transformations and transformation flows are reloaded by comparing with full load and applying changes.
-
Data mart tasks immediately following a Storage task are reloaded by truncating and loading.
You can cancel the reload for tables that are pending reload by clicking Cancel reload. This will not affect tables that are already reloaded, and reloads that are currently running will be completed.
Schema evolution
Schema evolution allows you to easily detect structural changes to multiple data sources and then control how those changes will be applied to your task. Schema evolution can be used to detect DDL changes that were made to the source data schema. You can also apply some changes automatically.
For each change type, you can select how to handle the changes in the Schema evolution section of the task settings. You can either apply the change, ignore the change, suspend the table, or stop task processing.
You can set which action to use to handle the DDL change for every change type. Some actions are not available for all change types.
-
Apply to target
Apply changes automatically.
-
Ignore
Ignore changes.
-
Suspend table
Suspend the table. The table will be displayed as in error in Monitor.
-
Stop task
Stop processing of the task. This is useful if you want to handle all schema changes manually. This will also stop scheduling, that is, scheduled runs will not be performed.
The following changes are supported:
-
Add column
-
Create table that matches the selection pattern
If you used a Selection rule to add datasets that match a pattern, new tables that meet the pattern will be detected and added.
For more information about task settings, see Schema evolution
Limitations for schema evolution
The following limitations apply to schema evolution:
-
Schema evolution is only supported when using CDC as update method.
-
When you have changed schema evolution settings, you must prepare the task again.
-
If you rename tables, schema evolution is not supported. In this case you must refresh metadata before preparing the task.
-
If you are designing a task, you must refresh the browser to receive schema evolution changes. You can set notifications to be alerted on changes.
-
In Landing tasks, dropping a column is not supported. Dropping a column and adding it will result in a table error.
-
In Landing tasks, a drop table operation will not drop the table. Dropping a table and then adding a table will only truncate the old table, and a new table will not be added.
-
Changing the length of a column is not possible for all targets depending on support in the target database.
-
If a column name is changed, explicit transformations defined using that column will not take affect as they are based on column name.
-
Limitations to Refresh metadata also apply for schema evolution.
-
If a task contains design changes that have not yet been prepared and source schema evolution changes are detected when the task is run, the task will be stopped to avoid conflicts. Prepare the pending design changes and run the task again.
When capturing DDL changes, the following limitations apply:
-
When a rapid sequence of operations occurs in the source database (for instance, DDL>DML>DDL), Qlik Talend Data Integration might parse the log in the wrong order, resulting in missing data or unpredictable behavior. To minimize the chances of this happening, best practice is to wait for the changes to be applied to the target before performing the next operation.
As an example of this, during change capture, if a source table is renamed multiple times in quick succession (and the second operation renames it back to its original name), an error that the table already exists in the target database might be encountered.
- If you change the name of a table used in a task and then stop the task, Qlik Talend Data Integration will not capture any changes made to that table after the task is resumed.
-
Renaming a source table while a task is stopped is not supported.
- Reallocation of a table's Primary Key columns is not supported (and will therefore not be written to the DDL History Control table).
- When a column's data type is changed and the (same) column is then renamed while the task is stopped, the DDL change will appear in the DDL History Control table as “Drop Column” and then “Add Column” when the task is resumed. Note that the same behavior can also occur as a result of prolonged latency.
- CREATE TABLE operations performed on the source while a task is stopped will be applied to the target when the task is resumed, but will not be recorded as a DDL in the DDL History Control table.
-
Operations associated with metadata changes (such as ALTER TABLE, reorg, rebuilding a clustered index, and so on) may cause unpredictable behavior if they were performed either:
-
During Full Load
-OR-
-
Between the Start processing changes from timestamp and the current time (i.e. the moment the user clicks OK in the Advanced Run Options dialog).
Example:
IF:
The specified Start processing changes from time is 10:00 am.
AND:
A column named Age was added to the Employees table at 10:10 am.
AND:
The user clicks OK in the Advanced Run Options dialog at 10:15 am.
THEN:
Changes that occurred between 10:00 and 10:10 might result in CDC errors.
Information noteIn any of the above cases, the affected table(s) must be reloaded in order for the data to be properly moved to the target.
-
- The DDL statement
ALTER TABLE ADD/MODIFY <column> <data_type> DEFAULT <>does not replicate the default value to the target and the new/modified column is set to NULL. Note that this may happen even if the DDL that added/modified the column was executed in the past. If the new/modified column is nullable, the source endpoint updates all the table rows before logging the DDL itself. As a result, Qlik Talend Data Integration captures the changes but does not update the target. As the new/modified column is set to NULL, if the target table has no Primary Key/Unique Index, subsequent updates will generate a "zero rows affected" message. -
Modifications to TIMESTAMP and DATE precision columns will not be captured.
Viewing task information
Click ![]() on the menu bar to view task information, such as:
on the menu bar to view task information, such as:
-
Owner
-
Space
-
Data platform
-
Project ID
-
Data task runtime ID
Storage settings
You can set properties for the storage data task when the data platform is a cloud data warehouse. If you use Qlik Cloud as data platform, see Storage settings for data projects with Qlik Cloud as the data platform.
-
Click Settings.
General settings
-
Database
Database to use in the data source.
-
Task schema
You can change the name of the storage data task schema. Default name is the name of the storage task.
-
Internal schema
You can change the name of the internal storage data asset schema. Default name is the name of the storage task with _internal appended.
-
Default capitalization of schema name
You can set the default capitalization for all schema names. If your database is configured to force capitalization, this option will not have effect.
- Prefix for all tables and views
You can set a prefix for all tables and views created with this task.
Information noteYou must use a unique prefix when you want to use a database schema in several data tasks. -
History
You can keep historical change data to let you easily recreate data as it looked at a specific point in time. You can use history views and live history views to see historical data. Select Keep historical records and archive of change records to enable historical change data.
-
When comparing storage with landing, you can choose how to manage records that do not exist in the landing.
-
Mark as deleted
This will perform a soft delete of records that do not exist in the landing.
-
Keep
This will keep all records that do not exist in the landing.
Information noteDatasets in Storage data task must have a primary key set. If not, each time landing data is reloaded an initial load will be performed on the Storage data task. -
-
Publish to catalog
Select this option to publish this version of the data to Catalog as a dataset. The Catalog content will be updated the next time you prepare this task.
For more information about Catalog, see Understanding your data with catalog tools.
Views settings
-
Live views
Use live views to read the tables with the least latency.
For more information about live views, see Using live views.
Information noteLive views are less efficient than standard views, and require more resources as the applied data needs to be recalculated.
View type settings
The View type settings are only applicable for Snowflake.
-
Standard views
Use Standard views for most cases.
-
Snowflake secure views
Use Snowflake secure views for views designated for data privacy or sensitive information protection, such as views created to limit access to sensitive data that should not be exposed to all users of the underlying tables.
Information note Snowflake secure views can execute more slowly than Standard views.
Runtime settings
-
Parallel execution
You can set the maximum number of connections for full loads to a number from 1 to 5.
-
Warehouse
The name of the cloud data warehouse. This setting is only applicable for Snowflake.
Table type settings
These settings are only available in projects with Snowflake as data platform.
-
Table type
You can select which table type to use:
-
Snowflake tables
-
Snowflake-managed Iceberg tables
You must set the default name of the external volume in Snowflake external volume.
-
-
Cloud storage folder to use
Select which folder to use when landing data to the staging area.
-
Default folder
This creates a folder with the default name: <project name>/<data task name>.
-
Root folder
Store data in the root folder of the storage.
-
Folder
Specify a folder name to use.
-
-
Sync with Snowflake Open Catalog
Enable this to let Snowflake Open Catalog manage the files in cloud file storage.
Schema evolution
Select how to handle the following types of DDL changes in the schema. When you have changed schema evolution settings, you must prepare the task again. The table below describes which actions are available for the supported DDL changes.
| DDL change | Apply to target | Ignore | Stop task |
|---|---|---|---|
| Add column | Yes | Yes | Yes |
| Create table
If you used a Selection rule to add datasets that match a pattern, new tables that meet the pattern will be detected and added. |
Yes | Yes | Yes |
Storage settings for data projects with Qlik Cloud as the data platform
You can set which folder to use in the storage when the data platform is Qlik Cloud as data platform.
-
Click Settings.
-
Select which folder to use in the storage.
-
Click OK when you are ready.
Operations on the storage data task
You can perform the following operations on a storage data task from the task menu.
-
Open
This opens the storage data task . You can view the table structure and details about the data task and monitor the status for the full load and batches of changes.
-
Edit
You can edit the name and the description of the task, and add tags.
-
Delete
You can delete the data task if it is not running, and there are no dependencies to downstream tasks in the same project.
-
In Pipeline project view of the project, click
 on a task and select Delete.
on a task and select Delete.
Artifacts (tables and views) created by the task will also be deleted, unless you select to keep them.
Information noteKeep in mind that the artifacts you keep will no longer be updated by the task. -
-
Prepare
This prepares a task for execution. This includes:
-
Validating that the design is valid.
-
Creating or altering the physical tables and views to match the design.
-
Generating the SQL code for the data task
-
Creating or altering the catalog entries for the task output datasets.
You can follow the progress under Preparation progress in the lower part of the screen.
-
-
Validate datasets
This validates all datasets that are included in the data task.
Expand Validate and adjust to see all validation errors and design changes.
-
Recreate tables
This recreates the datasets from the source. When recreating a table, the downstream task will react as if a truncate and reload action occurred on the source datasets. For more information, see Troubleshooting a storage data task.
-
Stop
You can stop operation of the data task. The data task will not continue to update the tables.
Information noteThis option is available when the data task is running. -
Resume
You can resume the operation of a data task from the point that it was stopped.
Information noteThis option is available when the data task is stopped. -
Transform data
Create reusable row-level transformations based on rules and custom SQL. This creates a Transform data task.
-
Create data mart
Create a data mart to leverage your data tasks. This creates a Data mart data task.
Limitations
-
If the data task contains datasets and you change any parameters in the connection, for example username, database, or schema, the assumption is that the data exists in the new location. If this is not the case, you can either:
-
Move the data in the source to the new location.
-
Create a new data task with the same settings.
-
-
It is not possible to change primary keys in storage tasks in projects with Qlik Cloud (QVD) as target. Update the primary keys in the landing task, recreate the landing task, and then recreate the storage task.
-
When using Iceberg storage, JSON data columns will be stored as STRING.