
Exécuter le modèle d'arbre de décision à l'aide des données de test
Cette section présente comment tester votre modèle d'arbre de décision et examiner la manière dont il prédit la variable cible.
Procédure
-
Dans les paramètres du tFileInputDelimited, modifiez la valeur du champ Folder/File pour pointer vers les données de test.
Les données de test ont le même schéma que les données d'apprentissage. Les seules différences sont les détails de contenu et le nombre de lignes.

-
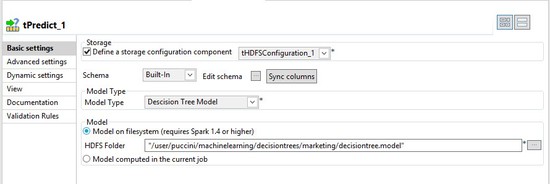
Ajoutez le chemin au modèle créé dans la section précédente.
-
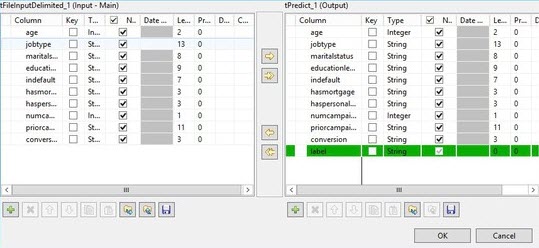
Cliquez sur le bouton Sync columns, puis cliquez sur le bouton [...] pour modifier le schéma.
Le panneau de sortie ajoute une colonne nommée label. Elle est la valeur factice pour la valeur prédite par le modèle de décision.
-
Ajoutez un tReplace dans l'espace de modélisation graphique et reliez-le au tPredict à l'aide d'un lien Row > Main.
-
Configurez le tReplace comme suit.

Le tReplace est requis pour convertir la sortie de prédiction depuis le tPredict à partir d'une représentation booléenne (0.0,10) en la représentation des données de test (yes/no).

-
Configurez le tAggregateRow comme suit.
La colonne de sortie Output column dans la section Operations a été choisie au hasard. age n'a pas été choisi pour une raison spécifique autre que la simplification du calcul pour Group by.

-
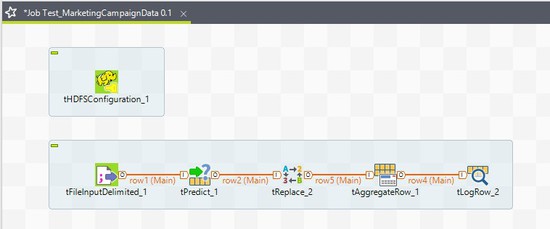
Ajoutez un tLogRow dans l'espace de modélisation graphique et reliez-le au tAggregateRow à l'aide d'un lien Row > Main.
Voici la configuration du Job.
Résultats
Le résultat attendu de ce Job est un résumé sous forme de tableau présentant les prédictions du modèle par rapport au résultat réel.

| count (age) (nombre, âge) | conversion (actual outcome) (résultat réel) | label (predicted outcome) (libellé, résultat prédit) |
|---|---|---|
| 41 | yes | non |
| 12 | non | yes |
| 15 | yes | yes |
| 446 | non | non |
Sur un total de 514 enregistrements de test, la résultat est le suivant :
- Le modèle a prédit de manière incorrecte :
- (conversion = no) true pour 41 des tests
- (conversion = no) false pour 12 des tests
- Le modèle a prédit de manière correcte :
- (conversion = no) false pour 15 des tests
- (conversion = no) true pour 446 des tests