
Skapa och hantera datapipelineprojekt
Du kan skapa en datapipeline för att utföra all dataintegrering inom ett projekt med dataarbetsuppgifter. Vid introduktionen flyttas data till projektet från lokala datakällor eller i molnet och lagrar data i datauppsättningar som kan användas direkt. Du kan infoga data i ett datalager eller i Qlik Open Lakehouse.
När du infogar data i ett datalager kan du även utföra omvandlingar och skapa datamarter för att utnyttja dina genererade och omvandlade datauppsättningar. Datapipelinen kan vara enkel och linjär, men den kan också vara en komplex pipeline som använder flera datakällor och genererar mycket utdata.
Alla dataarbetsuppgifter kommer att skapas i samma utrymme som det projekt som de tillhör.
Du kan också visa ursprung för att spåra data och dataomvandlingar bakåt till ursprungskällan och utföra påverkansanalys som visar den framåtpekande nedströmsvyn av en datauppgift, datauppsättning eller fältberoenden. Mer information finns i Arbeta med ursprung och konsekvensanalys i Dataintegrering.
Introduktion av data till ett datalager
Här ingår mellanlagring av data till ett mellanlagringsområde och sedan att lagra dataposterna i ett molndatalager. Dataarbetsuppgifter för mellanlagring och lagring skapas i ett enda steg. Vid behov kan du även utföra mellanlagring och lagring som separata uppgifter.
Introducear data till Qlik Open Lakehouse
Skapa ett Qlik Open Lakehouse pipelineprojekt för att kopiera data från valfri källa som stöds till Iceberg öppet tabellformat. Tabeller kan nås och frågas från din molndatalagers analysmotor, utan att duplicera data genom att använda en Mirror data task.
Registrera data som redan finns på dataplattformen
Registrera data som redan finns på dataplattformen för att kurera och omvandla data och skapa datamarter. Det innebär att du kan använda data som har introducerats med andra verktyg än Qlik Talend Data Integration, till exempel Qlik Replicate eller Stitch.
Omvandla data
Skapa återanvändbara omvandlingar på radnivå för introducerade data baserat på regler och anpassad SQL. Detta skapar en Transform-dataarbetsuppgift.
Skapa och hantera data marts
Skapa en datamart för att utnyttja dina datauppsättningar. Detta skapar en Data mart-dataarbetsuppgift.
Skapa kunskapsmartar
Skapa en kunskapsmart för att bädda in och lagra dina strukturerade och ostrukturerade data i en vektordatabas. Detta skapar en datauppgift för en kunskapsmart.
Måldataplattformar
Projektet är kopplat till en dataplattform som används som mål för all utdata.
Mer information om dataplattformar som stöds finns i Konfigurera kopplingar till mål.
Videointroduktion till projekt
Exempel på att skapa ett projekt
I det följande exemplet utförs introduktion av data, omvandling av data och en datamart skapas. Därigenom skapas en enkel linjär datapipeline som du kan utöka genom att registrera fler datakällor, skapa fler omvandlingar och lägga till de genererade datauppsättningarna i datamarten.
Exempel på en linjär datapipeline i ett projekt

-
Skapa ett nytt projekt
I Dataintegrering > Pipelineprojekt, klickar du på Skapa nytt > Projekt.
-
Ange ett namn och en beskrivning för projektet.
Anteckning om informationOm du senare aktiverar versionskontroll för projektet kommer du inte att kunna ändra projektnamnet när det är under versionskontroll. -
Välj ett utrymme att skapa projektet i. Alla dataarbetsuppgifter kommer att skapas i utrymmet för det projekt som de tillhör.
- Välj Datapipeline i Användningsfall.
-
Välj vilken dataplattform du vill använda i projektet.
-
Välj en koppling till det molndatalager som du vill använda i projektet. Det kommer att användas för att introducera datafiler och lagra datauppsättningar och vyer. Om du inte redan har förberett en koppling skapar du en med Skapa ny.
-
Om du har valt Google BigQuery, Databricks eller Microsoft Azure Synapse Analytics som dataplattform måste du också koppla till ett mellanlagringsområde.
-
Om du har valt Snowflake som dataplattform kan du välja att mellanlagra data i molnet. Se Mellanlagring av data till ett datasjöhus.
-
Om du har valt Qlik Cloud som dataplattform:
Du kan antingen lagra data i Qlik-hanterad lagring eller din egen hanterade Amazon S3-bucket. Om du vill använda din egen Amazon S3-bucket måste du välja en koppling för denna bucket.
I båda fallen måste du använda en koppling till ett mellanlagringsområde för Amazon S3. OM du använder samma bucket som du definierade i det föregående steget måste du använda en annan katalog i bucket för mellanlagring.
-
-
Klicka på Skapa.
Projektet skapas och du kan skapa din datapipeline genom att lägga till dataarbetsuppgifter.
-
-
Introducera data
I projektet klickar du på Skapa och sedan på Introducera data.
Mer information finns i Introduktion av data till ett datalager.
Detta kommer att skapa en dataarbetsuppgift för mellanlagring och en för lagring. För att börja replikera data behöver du:
-
Förbered och kör dataarbetsuppgiften för mellanlagring.
Mer information finns i Mellanlagra data från datakällor.
-
Förbered och kör lagringsuppgiften.
Mer information finns i Lagra datauppsättningar.
-
-
Omvandla data
När dataarbetsuppgiften för lagring skapas går du tillbaka till projektet. Du kan nu utföra omvandlingar på de skapade datauppsättningarna.
Klicka på ... på dataarbetsuppgiften för lagring och välj Omvandla data för att skapa en dataarbetsuppgift för omvandling baserat på den här dataarbetsuppgiften för lagring. Se Omvandla data för instruktioner om omvandlingar.
-
Skapa en datamart
Du kan skapa en datamart baserat på en dataarbetsuppgift lagring eller en dataarbetsuppgift för omvandling.
Klicka på … på dataarbetsuppgiften och välj Skapa datamart för att skapa en dataarbetsuppgift för datamart. Instruktioner om att skapa en datamart finns på:
När du har utfört den första fullständiga laddningen av de lagrade och transformerade datamängderna och datamarterna kan du till exempel använda dem i en analysapplikation. Mer information om att skapa analysapplikationer finns i Skapa en analysapp med datauppsättningar som genererats i Dataintegrering.
Du kan också utöka datapipelinen genom att introducera fler datakällor och kombinera dem i omvandlingen eller i datamarten.
Bygga projektövergripande pipelines
Du kan bygga projektövergripande pipelines där en uppgift kan använda uppgifter från ett annat projekt. Detta gör att du kan uppnå segmentering på flera möjliga sätt:
-
Du kan skapa en separat pipeline för dataflytt för varje organisatorisk enhet och använda utdata i en enda pipeline för datamart.
-
Du kan skapa en enda dataflyttpipeline och använda resultatet i flera olika transformeringspipelines.
Transformering och Data Mart-uppgifter kan använda lagrings- och transformeringsuppgifter som finns i ett annat projekt.
-
Du måste ha minst rollen Kan använda i utrymmet för det använda projektet.
-
Båda projekten måste finnas på samma dataplattform.
Alla datauppsättningar för en uppgift delas med nedströmsprojekt. Det innebär att om du vill uppnå segregering av datauppsättningen måste du filtrera ut datauppsättningen i det använda projektet genom att skapa en transformeringsuppgift.
I projektvyn kan du visa uppgifter som används av ett annat projekt och uppgifter från andra projekt som används i det aktuella projektet. Alla uppgifter utanför det aktuella projektet är gråa. Beroendena är referensbaserade och inte namnbaserade, vilket innebär att du kan byta namn på en uppgift utan att bryta referensen. Detta innebär också att om du tar bort en använd uppgift och skapar en ny uppgift med samma namn, kommer referensen fortfarande att brytas.
Det finns flera sätt att återanvända befintliga data:
-
Skapa ett nytt projekt
Välj alternativet Använd data från ett annat projekt när du har skapat ett projekt.
Du kan skapa en transformering eller en datamart som använder introducerade data från en annan pipeline.
-
I en transformeringsuppgift eller datamartuppgift kan du välja data från ett annat projekt i Välj källdata.
När du väljer källdata, väljer du Projekt. Om det valda projektet är under versionskontroll, välj en Gren. Standardgrenen är main. Datauppgiftslistan uppdateras för att återspegla den valda grenen. Välj sedan en Datauppgift för att se vilka datauppsättningar som finns tillgängliga.
Du kan välja om du vill visa uppgifter i andra projekt som använder en uppgift i det här projektet.
-
Klicka på Skikt och slå på eller av Utdata från gränsövergripande projekt.
Alla uppgifter utanför det aktuella projektet är gråa.
Begränsningar i versionshanteringen
Eftersom projektövergripande pipelines är uppdelade på flera projekt blir det mer komplicerat att använda versionshantering. I dessa exempel används Project1 av Project2.
Exempel på en projektöverskridande pipeline

-
Project2 kan använda en specifik gren av Project1. Välj grenen i Välj källdata i transformerings- eller datamart-uppgiften. Standardgrenen är main. Om det refererade projektet inte är under versionskontroll, visas inte grenväljaren och Project2 använder projektet som det är.
-
Du kan skapa en förgrening för Project1, men den förgrenade versionen kommer inte att visa att den används av Project2.
-
Du kan sammanfoga Project2 med huvudgrenen, men beroendet kommer fortfarande att finnas kvar.
Om grenen som valts i Project1 senare tas bort, bryts referensen på samma sätt som när en refererad uppgift tas bort. Om den refererade uppgiften har olika utdata på den valda grenen, beter sig referensen på samma sätt som när utdata från den refererade uppgiften ändras.
Metodtips
-
Kontrollera att uppgifterna i det använda projektet åtminstone är förberedda, för att säkerställa att de är giltiga.
-
Om du planerar att exportera och importera projekt mellan klientorganisationer blir det enklare om du behåller samma namn på utrymmen och projekt i klientorganisationerna. Om namnen skiljer sig åt måste du mappa projekt och uppgifter när du importerar projektet.
-
Om du vill ändra dataplattform med hjälp av exportera och importera måste alla projekt med beroenden vara på samma plattform.
Följ dessa steg för ett säkert och enkelt plattformsbyte. I det här exemplet kallas projektet som används för Consumed, och projektet som läser från Consumed kallas Consumer.
-
Exportera Consumed och Consumer.
-
Importera Consumed till Consumed_New och byt till den nya dataplattformen.
-
Importera Consumer till Consumer_New, byt till samma dataplattform som Consumed_New och ersätt källprojektet (Consumed) med Consumed_New.
-
Åtgärder i ett datapipelineprojekt
Du kan utföra samma operationer som är tillgängliga för en datauppgift som projektåtgärder. På så sätt kan du organisera åtgärderna i datapipelinen.
-
Slå på och av scheman
-
Utför designåtgärder.
-
Starta och stoppa utförandet av datauppgifter
-
Ta bort datauppgifter
Klicka på Operationer för att visa statusen för en pågående operation eller den senast utförda operationen.
Du kan stoppa en pågående operation genom att klicka på Stoppa operation. Datauppgifter som pågår stoppas inte, men alla uppgifter som ännu inte har startats avbryts.
Slå på och av scheman
Du kan styra schemana för datauppgifter på projektnivå.
-
Klicka på … och sedan på Schema.
Du kan aktivera eller inaktivera schemat för alla datauppgifter eller ett urval av uppgifter. Endast uppgifter med ett definierat schema visas.
Anteckning om informationDet här alternativet är inte tillgängligt för projekt med Qlik Cloud som dataplattform.
Mer information om schemaläggning av individuella datauppgifter finns i:
Utföra designåtgärder.
Du kan utföra designåtgärder på alla datauppgifter i projektet eller på ett urval av uppgifter. Detta gör det lättare att styra uppgifterna för datauppsättningen i projektet, i stället för att utföra designåtgärderna individuellt i varje uppgift.
-
Validera
Klicka på Validera för att validera alla uppgifter eller ett urval av uppgifter. Datauppgifter som ändrats sedan den senaste valideringsoperationen väljs i förväg.
Datauppgifterna valideras i pipeline-ordning.
-
Förbered
Klicka på Förbered för att förbereda alla uppgifter eller ett urval av uppgifter. Datauppgifter som ändrats sedan den senaste förberedelseoperationen väljs i förväg.
Du kan välja att återskapa datauppsättningar som kräver en strukturförändring som inte stöds av dataplattformen. Det kan leda till dataförlust.
-
Återskapa
Klicka på … och sedan på Återskapa tabeller för att återskapa datauppsättningarna från källan för alla uppgifter eller för ett urval av uppgifter.
Anteckning om informationOm det uppstår problem med enskilda tabeller rekommenderas du att först försöka läsa in tabellerna igen istället för att återskapa dem. Om du återskapar tabeller kan detta leda till att historiska data förloras. Om det sker stora förändringar måste du också förbereda datauppgifter nedströms som använder de återskapade datauppgifterna för att ladda data på nytt.
Köra datauppgifter
Du kan initiera utförandet av alla datauppgifter i projektet eller för ett urval av åtgärder i stället för att köra åtgärderna individuellt. Du kan till exempel köra alla uppgifter med ett tidsbaserat schema. Detta kommer att initiera nedströmsuppgifter med ett händelsebaserat schema.
-
Kör
Klicka på Kör för att påbörja utförandet av alla uppgifter eller ett urval av uppgifter. Detta initierar körningen av alla valda uppgifter och avslutas så snart de börjar utföras.
Du kan välja bland alla uppgifter som är redo att köras. Uppgifter med ett tidsbaserat schema och uppgifter som använder CDC är förvalda. Uppgifter med ett händelsebaserat schema är inte förvalda eftersom de utförs när de har data att bearbeta.
I ett projekt med Qlik Cloud som dataplattform är alla mellanlagrings- och lagringsuppgifter förvalda.
Anteckning om informationAlla datauppgifter utförs parallellt. Detta innebär att kontroller av beroenden kan hindra vissa uppgifter från att köras. -
Stoppa
Klicka på Stoppa för att stoppa alla uppgifter eller ett urval av uppgifter.
Du kan välja bland uppgifter som körs.
Ta bort datauppgifter
-
Klicka på Ta bort för att ta bort alla datauppgifter i projektet eller ett urval av uppgifter.
Det går inte att ta bort uppgifter som körs, eller uppgifter som används av andra uppgifter.
Ändra vy för ett projekt
Det finns två olika vyer av projekt. Du kan växla mellan vyerna genom att klicka på Pipelinevy.
-
Pipelinevyn visar dataflödet för datauppgifterna.
Du kan välja hur mycket information om ska visas för datauppgifterna genom att klicka på Skikt. Slå på eller av följande information:
-
Status
-
Uppgifternas aktualitet
-
Schema
-
Utdata från gränsöverskridande projekt
Det här kommer att visa uppgifter i andra projekt som använder en uppgift i det här projektet. Alla uppgifter utanför det aktuella projektet är gråa.
-
-
I kortvyn visas en kortvy med information om datauppgiften.
Du kan filtrera efter tillgångstyp och ägare.
Borttagning av projekt
-
I vyn Pipelineprojekt klickar du på
 i ett projekt och väljer Ta bort.
i ett projekt och väljer Ta bort.
Välj Behåll tabeller och vyer som skapats av uppgifterna i det här projektet för att behålla tabeller och vyer som normalt skulle tas bort efter att ett projekt har tagits bort. Observera att för följande uppgiftstyper kommer tabeller och vyer alltid att behållas, även när detta alternativ inte är valt:
-
Mellanlagringsuppgifter
-
Mellanlagringsuppgifter i sjö
-
Replikeringsuppgifter
Visa data
Du kan visa ett exempel på data och visa och validera formen på dina data när du utformar din datapipeline.
Följande behörigheter krävs:
-
Visning av data är aktiverat på klientorganisationsnivån i Administration.
Aktivera InställningarFunktionskontrollVisa data i Dataintegrering.
-
Du har tilldelats rollen Kan visa data i det utrymme där kopplingen finns.
-
Du har tilldelats rollen Kan visa i det utrymme där projektet finns.
För att visa exempeldata i datapipelinevyn:
-
Klicka på
 i förhandsgranskningsbanderollen längst ner i pipelinevyn.
i förhandsgranskningsbanderollen längst ner i pipelinevyn. -
Välj vilken datauppgift du vill förhandsgranska data för.
Ett urval av data visas. Du kan ställa in hur många datarader som ska tas med i exemplet med Antal rader.
Exportera och importera projekt
Du kan exportera ett projekt till en JSON-fil som innehåller allt som behövs för att rekonstruera projektet. Den exporterade JSON-filen kan importeras på samma klientorganisation eller på en annan klientorganisation. Du kan till exempel använda detta för att flytta projekt från en klientorganisation till en annan eller för att göra säkerhetskopior av projekt.
Mer information finns i Exportera och importera datapipelines.
Ändra ägare till ett projekt
Datauppgifterna styrs av ägaren till det projekt de tillhör. Du kan ändra ägare till ett projekt för att flytta kontrollen av samtliga uppgifter i dataprojektet till en annan användare. Detta är t.ex. användbart om det finns projekt som ägs av en användare som har raderats.
-
I projektvyn klickar du på ... och sedan på Byt ägare-
Ägarbytet kommer att gälla alla uppgifter i projektet. Alla katalogiserade datauppsättningar som skapas av uppgifter i projektet kommer också att byta ägare.
Ändra dataplattformskoppling
Om du ändrar dataplattformskopplingen för ett projekt måste du:
-
Återskapa tabeller i alla mellanlagringsuppgifter.
-
Förbereda alla andra uppgifter i projektet.
Visa projektinformation
Klicka på ![]() i menyraden för att visa projektinformation, till exempel:
i menyraden för att visa projektinformation, till exempel:
-
Ägare
-
Utrymme
-
Dataplattform
-
Projekt-id
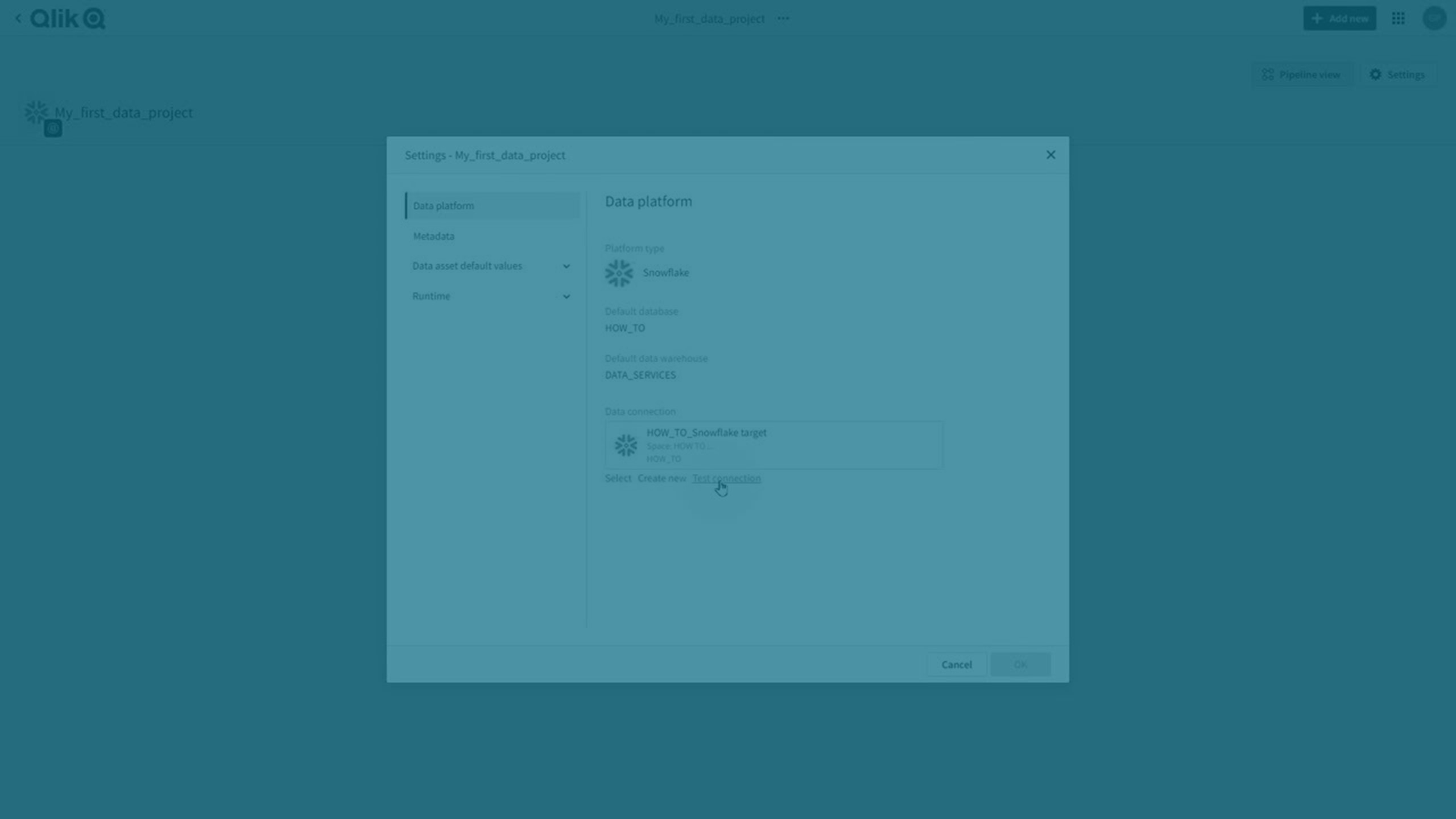
Projektinställningar
Du kan ställa in egenskaper som är gemensamma för projektet och alla dataarbetsuppgifter som ingår.
-
Klicka på Inställningar.
Mer information finns i Projektinställningar för datapipeline.