
Hantera datauppsättningar
Du kan hantera datauppsättningarna som ingår i Mellanlagring, Lagring, Transformering, Datamart, Strömmande mellanlagring, Strömmande transformering och Replikering datauppgifter för att skapa transformeringar, filtrera data och lägga till kolumner.
De datauppsättningar som ingår listas under Datauppsättningar i vyn Design. Du kan välja vilka kolumner som visas med kolumnväljaren (![]() ).
).
Datauppsättningar i Designvyn för en dataarbetsuppgift

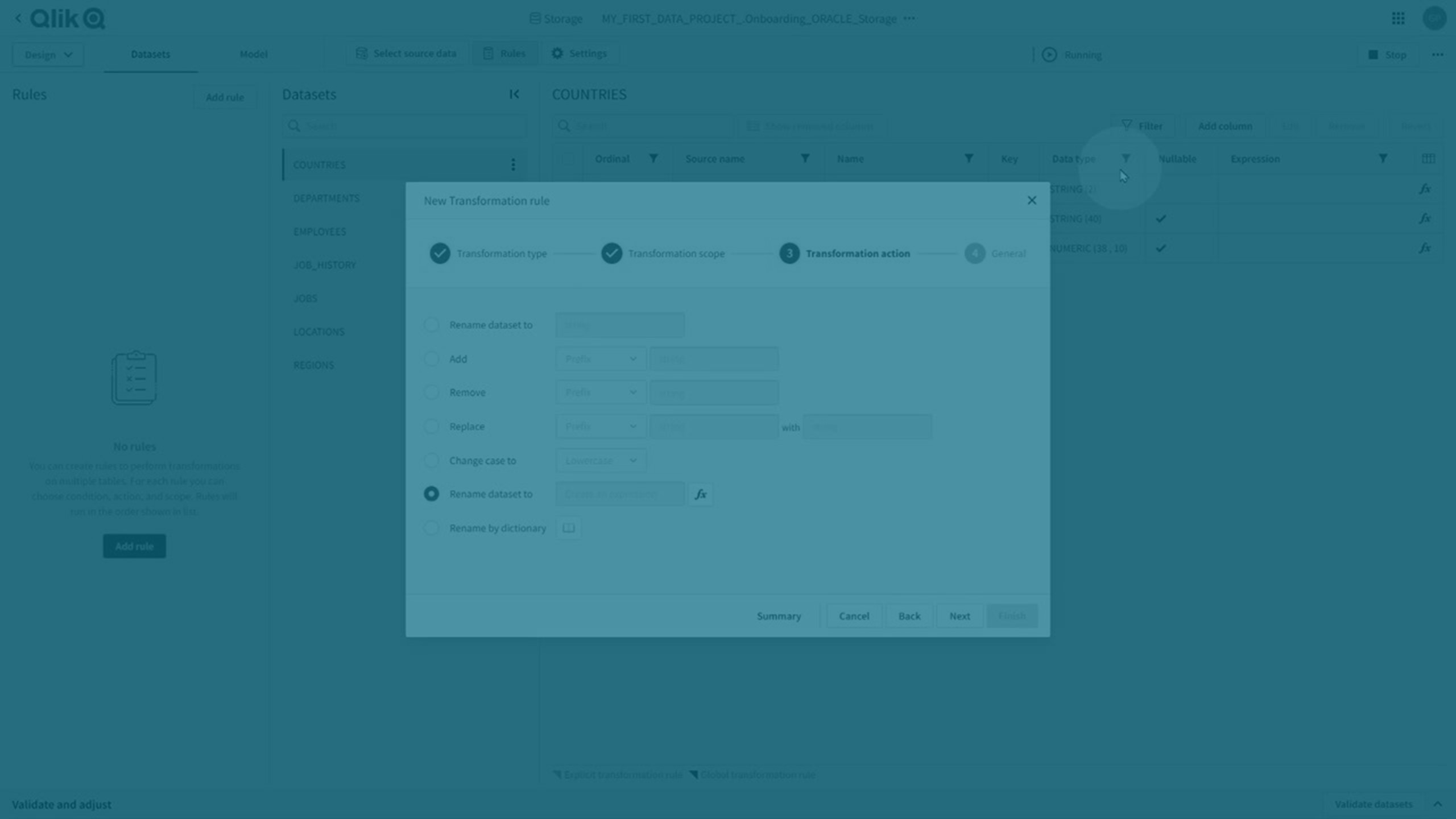
Transformeringsregler och explicita transformeringar
Du kan utföra både globala och uttryckliga omvandlingar.
Transformeringsregler
Du kan utföra globala transformeringar genom att skapa en transformeringsregel som använder % som jokertecken i omfattningen så att den används på alla matchande datauppsättningar.
-
Klicka på Regler och sedan på Lägg till regel för att skapa en ny omvandlingsregel.
Mer information finns i Skapa regler för att transformera dataset.
Transformeringsregler visas med ett mörklila hörn på det attribut som påverkas.
Uttryckliga omvandlingar
Uttryckliga transformeringar skapas:
-
När du använder Redigera för att ändra ett kolumnattribut
-
När du använder Byt namn på en datauppsättning.
-
När du lägger till en kolumn.
Uttryckliga omvandlingar åsidosätter globala omvandlingar, och anges med ett ljuslila hörn på det berörda attributet.
Datauppsättningsmodeller
Datauppsättningar kan vara antingen källbaserade eller målbaserade, beroende på uppgiftstyp och åtgärder i uppgiften. Den modell för datauppsättning som används påverkar pipelines beteende vid ändringar i källan och vilka åtgärder du kan utföra.
-
Källbaserade datauppsättningar
Datauppsättningen baseras på källdatauppsättningar och kommer endast att innehålla förändringar i metadata. En ändring i källdata tillämpas automatiskt vilket kan orsaka ändringar i alla nedströmsuppgifter. Det är inte möjligt att ändra kolumnordning eller att ändra källdatauppsättning.
Följande uppgiftstyper använder alltid en källbaserad datauppsättningsmodell: mellanlagring, lagringsplats, registrerade data, replikering och mellanlagra data i datasjö.
-
Målbaserade datauppsättningar
Datauppsättningen baseras på målets metadata. Om en kolumn läggs till eller tas bort från källan tillämpas den inte automatiskt på nästa nedströmsuppgift. Du kan ändra ordningen på kolumnerna och källdatauppsättningen. Detta innebär att uppgiften är mer fristående och låter dig kontrollera effekten av källändringar.
Följande uppgiftstyper kan använda en målbaserad datauppsättningsmodell: transformation, datamart. Det finns vissa fall där en källbaserad modell används för transformation av uppgifter baserat på driften.
-
Om en SQL-transformation eller ett transformationsflöde utför ett val av kolumn kommer datauppsättningen att vara målbaserad. Om du exempelvis använder SELECT A, B, C from XYZ i en SQL-transformering eller om du använder processorn välj kolumner i ett transformeringsflöde.
-
Om standardkolumnerna bibehålls är datauppsättningen källbaserad. Exempelvis om du använder SELECT * from XYZ i en SQL-transformering.
-
Uppdatera projekt från en källbaserad modell till en målbaserad modell
Befintliga projekt kommer att uppdateras till den nya målbaserade datauppsättningsmodellen i förekommande fall. Du kommer att guidas genom uppdateringsförfarandet när du först öppnar projektet. Det finns några saker att tänka på när du importerar och exporterar projekt med olika datauppsättningsmodeller.
-
Det är inte möjligt att importera ett projekt med en källbaserad modell till ett projekt med en målbaserad modell.
Importera projektet med en källbaserad modell till ett nytt projekt, uppdatera det nya projektet och exportera sedan det resulterande projektet. Du kan nu återimportera detta projekt till projektet med en målbaserad modell.
-
Det är inte möjligt att importera ett projekt med en målbaserad modell till ett projekt med en källbaserad modell.
Uppdatera projektet till en målbaserad modell innan du importerar ett projekt med en målbaserad modell.
Filtrera en datauppsättning
Du kan vid behov filtrera data för att skapa en delmängd av rader.
-
Klicka på Filter.
Mer information finns i Filtrera ett dataset.
Byta namn på en datauppsättning
Du kan byta namn på en datauppsättning.
-
Klicka på
 i en datauppsättning, och sedan på Redigera.
i en datauppsättning, och sedan på Redigera.
Lägga till kolumner
Du kan vid behov lägga till kolumner med transformeringar på radnivå.
-
Klicka på Lägg till kolumn
Mer information finns i Lägga till kolumner i en datauppsättning.
Redigera en kolumn
Du kan redigera kolumnegenskaper genom att välja en kolumn och klicka på Redigera.
-
Namn
-
Nyckel
Välj en kolumn som primär nyckel. Du kan också ställa in nycklar genom att markera eller avmarkera i Nyckel-kolumnen.
-
Nollningsbar
-
Datatyp
Ställ in datatyp för kolumnen. För vissa datatyper kan du ställa in ytterligare en egenskap, till exempel Längd.
Anteckning om informationNär du ändrar datatypen eller datatypstorleken för en kolumn kan detta få konsekvenser för de uppgifter som använder datamängden. Mer information finns i Hantera datatyper.
Ta bort kolumner
Du kan ta bort en eller flera kolumner från en datauppsättning.
-
Välj de kolumner som du vill ta bort och klicka på Ta bort.
Om du vill se borttagna kolumner klickar du på Visa borttagna kolumner. Borttagna kolumner anges med genomstruken text. Du kan hämta en borttagen kolumn genom att markera den och klicka på Återställ.
Återställa uttryckliga ändringar av kolumner
Du kan återställa alla uttryckliga ändringar av en eller flera kolumner.
-
Välj de kolumner som ändringar ska återställas för och klicka på Återställ.
Ändringar från globala transformeringsregler återställs inte.
Om du återställer en tillagd kolumn tas den bort.
Inställningar för datauppsättningar
Du kan ändra inställningarna för datauppsättningen. Standardinställningen är att ärva inställningen i datauppgiften, men du kan också ändra en inställning så att den uttryckligen är Av eller På.
-
Klicka på
 på en datauppsättning och sedan på Inställningar.
på en datauppsättning och sedan på Inställningar.
Visa rubrikkolumner i vyer
För Qlik Open Lakehouse Streaming-mellanlagrings- och Transform-uppgifter kan du styra om rubrikkolumnerna ska visas eller döljas. Alternativen skiljer sig åt beroende på uppgiftstyp.
Streaming mellanlagringsuppgift
För att visa rubrikkolumnerna, aktivera Visa rubrikkolumner till höger om sökrutan.
Strömmande transformeringsuppgift
Till höger om sökrutan finns en listruta med följande alternativ.
-
Dölj rubrikkolumner: Standard.
-
Visa rubrikkolumner
-
Standard: Välj att visa rubrikkolumner för standardvyer.
-
Historik: Välj för att visa rubrikkolumner för historikvyer. Observera att det här alternativet endast är tillgängligt om Skapa en historisk datalagring (typ 2) är aktiverat i uppgifts- eller datamängdsinställningarna.
-
En beskrivning av de tillgängliga rubrikkolumnerna finns i Mellanlagringstabeller och Vyer.
Visa data
Du kan visa ett exempel på data och visa och validera formen på dina data när du utformar din datapipeline.
Följande krav måste vara uppfyllda:
-
Visning av data är aktiverat på klientorganisationsnivå i Administration aktivitetscentret.
Du aktiverar det genom att gå till sidan Inställningar, välja fliken Funktionskontroll och aktivera Visa data i Dataintegrering.
-
Du har tilldelats rollen Kan visa data i det utrymme där kopplingen finns.
-
Du har tilldelats rollen Kan visa i det utrymme där projektet finns.
Visa exempeldata
För att visa exempeldata i fliken Datauppsättningar i Designvyn:
-
Klicka på Visa data.
Ett urval av data visas. Du kan ställa in hur många datarader som ska tas med i exemplet med Antal rader.
Förståelse för datastruktur
Dataprevyn visar både verksamhetskolumner och systemgenererade kolumner. När du visar data från strömmande datamängder, tillhandahåller rubrikkolumner (med prefixet hdr__) metadata om datakälla och transformationer. Exempel inkluderar hdr__from_timestamp (när data laddades) och hdr__operation (typ av åtgärd som tillämpades).
Rubrikkolumner är skrivskyddade och kan inte ändras eller tas bort från förhandsgranskningen. För att styra vilka rubriker som visas som standard, konfigurera rubriker för standardvyer på projekt- eller datamängdsnivå.
Växla mellan datauppsättningar och tabeller
För att växla mellan datauppsättningar och tabeller:
-
Välj Datauppsättningar för att visa den logiska representationen av data.
-
Välj Fysiska objekt för att visa den fysiska representationen i databasen som tabeller och vyer.
Anteckning om nyheterDet här alternativet är inte tillgängligt om den fysiska representationen inte har skapats ännu.
Filtrera
Du kan filtrera exempeldata på två sätt:
-
Använd
 för att filtrera vilka exempeldata som ska hämtas.
för att filtrera vilka exempeldata som ska hämtas.Om du till exempel använder filtret ${OrderYear}>2023 och Antal rader är inställt till 10, kommer du att få ett urval på 10 ordrar från 2024.
-
Filtrera exempeldata efter en specifik kolumn.
Detta kommer bara att påverka befintliga exempeldata. Om du använder
så att bara ordrar från 2024 inkluderas och ställer in kolumnfiltret så att ordrar från 2022 visas blir resultatet ett tomt urval.
Sortering
Du kan också sortera dataurvalet via en specifik kolumn. Sorteringen kommer bara att påverka befintliga exempeldata. Om du använder ![]() så att bara ordrar från 2024 inkluderas och inverterar sorteringsordningen kommer exempeldata fortfarande bara innehålla ordrar från 2024.
så att bara ordrar från 2024 inkluderas och inverterar sorteringsordningen kommer exempeldata fortfarande bara innehålla ordrar från 2024.
Dölja kolumner
Du kan dölja kolumner i datavyn:
-
Dölj en enstaka kolumn genom att klicka på
på kolumnen och sedan på Dölj kolumn. -
Dölj flera kolumner genom att klicka på
på valfri kolumn och sedan på Visa kolumner. På så sätt kan du kontrollera synligheten för alla kolumner i vyn.
Laddar ned exempeldata
Du kan hämta de visade exempeldata:
-
Klicka
 om du vill hämta innehållet i exempeldatavyn.
om du vill hämta innehållet i exempeldatavyn.
Exempeldatan hämtas som en CSV-fil till webbläsarens hämtade filer.
Validera och justera datauppsättningarna
Du kan validera alla datauppsättningar som ingår i dataarbetsuppgiften.
Expandera Validera och justera för att visa alla valideringsfel och designändringar.
Validera datauppsättningarna
-
Klicka på Validera datauppsättningar för att validera datauppsättningarna.
I validering ingår kontroll av att:
-
Alla tabeller har en primär nyckel
-
Det inte finns några saknade attribut.
-
Det inte finns någon fördubblad tabell eller kolumnnamn.
Du kommer också att få en lista med designändringar jämfört med källan:
-
Tillagda tabeller och kolumner
-
Släppta tabeller och kolumner
-
Tabeller och kolumner som har bytt namn
-
Ändrade primärnycklar och datatyper
Expandera Validera och justera för att visa alla valideringsfel och designändringar.
-
Rätta valideringsfelen och validera datauppsättningarna igen.
-
De flesta designändringar kan justeras automatiskt, utom ändrade primärnycklar och datatyper. I det här fallet måste du synkronisera datauppsättningarna.
Förbereda datauppsättningarna
Du kan förbereda datauppsättningar för att justera designändringar utan att data går förlorade om möjligt. Om det finns designändringar som inte kan justeras utan dataförlust får du möjlighet att återskapa tabeller från källan med dataförlust.
Uppgiften måste då stoppas.
-
Klicka på
 och sedan på Förbered.
och sedan på Förbered.
När datauppsättningarna har förberetts ska du validera datauppsättningarna innan du startar om lagringsuppgiften.
Återskapa datauppsättningar
Du kan återskapa datauppsättningarna från källan. När du återskapar en datauppsättning kommer data att gå förlorade. Så länge du har källdata kan du ladda om dem från källan.
Uppgiften måste då stoppas.
-
Klicka på
, sedan Återskapa tabeller.
Laddar ned valideringsdata
Du kan hämta data från Valideringsfel, Designändringar, och Förberedelseförlopp:
-
Klicka på
för att hämta.
Datan hämtas som en CSV-fil till din webbläsares nedladdningar.
Begränsningar
-
Om du tar bort eller byter namn på en kolumn i Google BigQuery leder det till att tabellen återskapas och till att data förloras.