
Gerenciando conjuntos de dados
Você pode gerenciar os conjuntos de dados incluídos nas tarefas de Aterrisagem, Armazenamento, Transformação, Datamart, Aterrisagem de streaming, Transformação de streaming e Replicação para criar transformações, filtrar os dados e adicionar colunas.
Os conjuntos de dados incluídos estão listados em Conjuntos de dados na exibição Design. Você pode selecionar quais colunas serão exibidas com o seletor de coluna (![]() ).
).
Conjuntos de dados na exibição Design de uma tarefa de dados

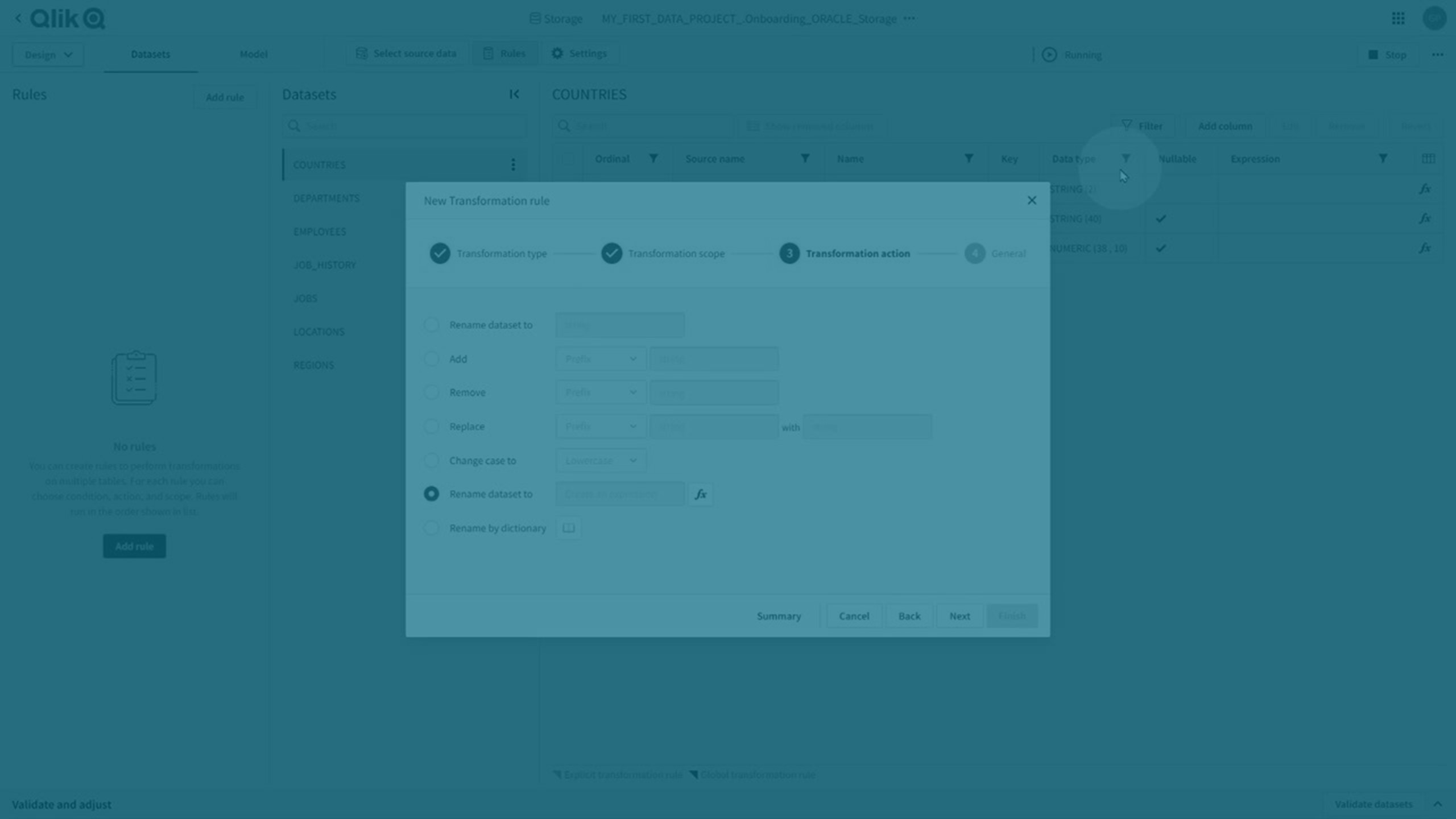
Regras de transformação e transformações explícitas
Você pode realizar transformações globais e explícitas.
Regras de transformação
Você pode realizar transformações globais criando uma regra de transformação que usa % como curinga no escopo a ser aplicada a todos os conjuntos de dados correspondentes.
-
Clique em Regras e, em seguida, em Adicionar regra para criar uma nova regra de transformação.
Para obter mais informações, consulte Criando regras para transformar conjuntos de dados.
As regras de transformação são indicadas por um canto roxo escuro no atributo afetado.
Transformações explícitas
Transformações explícitas são criadas:
-
Quando você usa Editar para alterar um atributo de coluna
-
Ao usar Renomear em um conjunto de dados.
-
Quando você adiciona uma coluna.
Transformações explícitas substituem transformações globais e são indicadas por um canto roxo claro no atributo afetado.
Modelos de conjunto de dados
Os conjuntos de dados podem ser baseados na origem ou no destino, dependendo do tipo de tarefa e das operações na tarefa. O modelo de conjunto de dados usado afeta o comportamento do pipeline nas alterações de origem e as operações que você pode executar.
-
Conjuntos de dados baseados na origem
O conjunto de dados se baseia em conjuntos de dados de origem e conterá apenas alterações nos metadados. Uma alteração nos dados de origem é aplicada automaticamente, o que pode causar alterações em todas as tarefas posteriores. Não é possível alterar a ordem das colunas ou alterar o conjunto de dados de origem.
Os seguintes tipos de tarefas sempre usam um modelo de conjunto de dados de origem: aterrisagem, armazenamento, dados registrados, replicação e aterrisagem em um data lake.
-
Conjuntos de dados baseados no destino
O conjunto de dados é baseado nos metadados de destino. Se uma coluna for adicionada da origem ou removida, ela não será aplicada automaticamente para a próxima tarefa downstream. Você pode alterar a ordem das colunas e alterar o conjunto de dados de origem. Isso significa que a tarefa é mais autocontida e permite que você controle o efeito das alterações de origem.
Os seguintes tipos de tarefas podem usar um modelo de conjunto de dados baseado em destino: transformar, datamart. Há alguns casos em que um modelo baseado em origem é usado para tarefas Transformar com base na operação.
-
Se uma transformação SQL ou um fluxo de transformação executar uma seleção de coluna, o conjunto de dados será baseado no destino. Por exemplo, se você usar SELECT A, B, C from XYZ em uma transformação SQL, ou usar o processador Selecionar colunas em um fluxo de transformação.
-
Se as colunas padrão forem mantidas, o conjunto de dados será baseado na origem. Por exemplo, se você usar SELECT * from XYZ em uma transformação SQL.
-
Atualizando projetos de um modelo baseado na origem para um modelo baseado no destino
Os projetos existentes são atualizados para o modelo de conjunto de dados baseado no destino quando aplicável. Você será guiado pelo processo de atualização ao abrir um projeto pela primeira vez. Existem algumas considerações ao importar e exportar projetos com diferentes modelos de conjunto de dados.
-
Não é possível importar um projeto com um modelo baseado em origem para um projeto com um modelo baseado no destino.
Importe o projeto com um modelo baseado na origem para um novo projeto, atualize o novo projeto e exporte o projeto resultante. Agora você pode reimportar este projeto para o projeto com um modelo baseado no destino.
-
Não é possível importar um projeto com um modelo baseado em destino para um projeto com um modelo baseado na origem.
Atualize o projeto para um modelo baseado em destino antes de importar um projeto com um modelo baseado no destino.
Filtrando um conjunto de dados
Você pode filtrar dados para criar um subconjunto de linhas, se necessário.
-
Clique em Filtro.
Para obter mais informações, consulte Filtrando um conjunto de dados.
Renomeando um conjunto de dados
Você pode renomear um conjunto de dados.
-
Clique em
 em um conjunto de dados e depois em Editar.
em um conjunto de dados e depois em Editar.
Adicionando colunas
É possível adicionar colunas com transformações em nível de linha, se necessário.
-
Clique em Adicionar coluna
Para obter mais informações, consulte Adicionando colunas a um conjunto de dados.
Editando uma coluna
Você pode editar as propriedades da coluna selecionando uma coluna e clicando em Editar.
-
Nome
-
Chave
Defina uma coluna como chave primária. Você também pode definir teclas selecionando ou desmarcando na coluna Chave.
-
Anulável
-
Tipo de dados
Defina o tipo de dados da coluna. Para alguns tipos de dados, você pode definir uma propriedade adicional, por exemplo, Comprimento.
Nota informativaAlterar o tipo de dados ou o tamanho do tipo de dados de uma coluna pode ter implicações nas tarefas que utilizam o conjunto de dados. Para obter mais informações, consulte Gerenciando tipos de dados.
Removendo colunas
Você pode remover uma ou mais colunas de um conjunto de dados.
-
Selecione as colunas a serem removidas e clique em Remover.
Se quiser ver as colunas removidas, clique em Mostrar colunas removidas. As colunas removidas são indicadas com texto riscado. Você pode recuperar uma coluna removida selecionando-a e clicando em Reverter.
Revertendo alterações explícitas em colunas
Você pode reverter todas as alterações explícitas em uma ou mais colunas.
-
Selecione as colunas para as quais reverter as alterações e clique em Reverter.
As alterações nas regras de transformação global não serão revertidas.
Se você reverter uma coluna adicionada, ela será removida.
Configurações do conjunto de dados
É possível alterar as configurações do conjunto de dados. A configuração padrão é herdar a configuração da tarefa de dados, mas você também pode alterar uma configuração para ser explicitamente Ativada ou Desativada.
-
Clique em
 em um conjunto de dados e depois em Configurações.
em um conjunto de dados e depois em Configurações.
Exibindo colunas de cabeçalho em exibições
Para Qlik Open Lakehouse aterrisagem de fluxo e tarefas de transformação, você pode controlar se deseja mostrar ou ocultar as colunas de cabeçalho. As opções diferem de acordo com o tipo de tarefa.
Tarefa de aterrisagem de streaming
Para exibir as colunas de cabeçalho, ative Exibir colunas de cabeçalho à direita da caixa de Pesquisa.
Tarefa de transformação de streaming
Uma lista suspensa com as seguintes opções está disponível à direita da caixa de pesquisa.
-
Ocultar colunas de cabeçalho: O padrão.
-
Mostrar colunas do cabeçalho
-
Padrão: Selecione para exibir as colunas de cabeçalho para exibições padrão.
-
Histórico: Selecione para exibir as colunas de cabeçalho para visualizações de histórico. Observe que esta opção estará disponível apenas se Criar um armazenamento de dados históricos (Tipo 2) estiver habilitado nas configurações da tarefa ou do conjunto de dados.
-
Para obter uma descrição das colunas de cabeçalho disponíveis, consulte Tabelas de preparação e Exibições.
Exibição de dados
Você pode visualizar uma amostra dos dados para ver e validar a forma dos seus dados enquanto projeta seu pipeline de dados.
Os seguintes requisitos devem ser atendidos:
-
A visualização de dados está habilitada no nível do locatário no centro de atividades de Administração.
Para ativá-la, vá para a página Configurações, selecione a guia Controle de recursos e ative Exibindo dados no Data Integration.
-
Você recebeu a função Pode visualizar dados no espaço onde reside a conexão.
-
Você recebeu a função Pode visualizar no espaço onde reside o projeto.
Exibindo dados de amostra
Para visualizar dados de amostra na guia Conjuntos de dados na exibição Design:
-
Clique em Exibir dados.
Uma amostra dos dados é exibida. Você pode definir quantas linhas de dados incluir na amostra com Número de linhas.
Entendendo a estrutura de dados
A visualização de dados exibe tanto colunas de negócio quanto colunas geradas pelo sistema. Ao visualizar dados de conjuntos de dados de streaming, as colunas de cabeçalho (prefixadas com hdr__) fornecem metadados sobre a fonte de dados e as transformações. Exemplos incluem hdr__from_timestamp (quando os dados foram carregados) e hdr__operation (tipo de operação aplicada).
Colunas de cabeçalho são somente leitura e não podem ser modificadas ou removidas da visualização. Para controlar quais cabeçalhos são exibidos por padrão, configure os cabeçalhos da exibição padrão no nível do projeto ou do conjunto de dados.
Alternando entre conjuntos de dados e tabelas
Para alternar entre conjuntos de dados e tabelas:
-
Selecione Conjuntos de dados para visualizar a representação lógica dos dados.
-
Selecione Objetos físicos para visualizar a representação física no banco de dados como tabelas e exibições.
Nota de notíciasEsta opção não está disponível se a representação física ainda não tiver sido criada.
Filtragem
Você pode filtrar os dados de amostra de duas maneiras:
-
Use
 para filtrar quais dados de amostra serão recuperados.
para filtrar quais dados de amostra serão recuperados.Por exemplo, se você usar o filtro ${OrderYear}>2023 e Número de linhas estiver definido como 10, você obterá uma amostra de 10 pedidos de 2024.
-
Filtrar os dados de amostra por uma coluna específica.
Isso afetará apenas os dados de amostra existentes. Se você usava o
para incluir apenas pedidos de 2024 e definia o filtro de coluna para mostrar pedidos de 2022, o resultado seria uma amostra vazia.
Classificação
Você também pode classificar a amostra de dados por uma coluna específica. A classificação afetará apenas os dados de amostra existentes. Se você usava ![]() para incluir apenas pedidos de 2024 e inverter a ordem de classificação, os dados de amostra ainda conterão apenas pedidos de 2024.
para incluir apenas pedidos de 2024 e inverter a ordem de classificação, os dados de amostra ainda conterão apenas pedidos de 2024.
Ocultando colunas
Você pode ocultar colunas na exibição de dados:
-
Oculte uma única coluna clicando em
na coluna e depois em Ocultar coluna. -
Oculte várias colunas clicando em
em qualquer coluna e depois em Exibir colunas. Isso permite controlar a visibilidade de todas as colunas da exibição.
Baixando os dados de amostra
Você pode baixar os dados de amostra exibidos:
-
Clique em
 para baixar o conteúdo da visualização de dados de amostra.
para baixar o conteúdo da visualização de dados de amostra.
Os dados de amostra são baixados como um arquivo CSV para os downloads do seu navegador.
Validando e ajustando os conjuntos de dados
Você pode validar todos os conjuntos de dados incluídos na tarefa de dados.
Expanda Validar e ajustar para ver todos os erros de validação e alterações de design.
Validando os conjuntos de dados
-
Clique em Validar conjuntos de dados para validar os conjuntos de dados.
A validação inclui verificar se:
-
Todas as tabelas têm uma chave primária
-
Não estão faltando atributos.
-
Não há nomes duplicados de tabelas ou colunas.
Você também receberá uma lista de alterações de design em comparação com a origem:
-
Tabelas e colunas adicionadas
-
Tabelas e colunas descartadas
-
Tabelas e colunas renomeadas
-
Chaves primárias e tipos de dados alterados
Expanda Validar e ajustar para ver todos os erros de validação e alterações de design.
-
Corrija os erros de validação e valide os conjuntos de dados novamente.
-
A maioria das alterações de design pode ser ajustada automaticamente, exceto as chaves primárias ou os tipos de dados alterados. Nesse caso, você precisa sincronizar os conjuntos de dados.
Preparando os conjuntos de dados
Você pode preparar conjuntos de dados para ajustar as alterações de design sem perda de dados, se possível. Se houver alterações de design que não possam ser ajustadas sem perda de dados, você terá a opção de recriar tabelas a partir da origem com perda de dados.
Isso requer a interrupção da tarefa.
-
Clique em
 e em Preparar.
e em Preparar.
Quando os conjuntos de dados estiverem preparados, valide-os antes de reiniciar a tarefa de armazenamento.
Recriando conjuntos de dados
Você pode recriar os conjuntos de dados a partir da origem. Quando você recriar um conjunto de dados, haverá perda de dados. Desde que você tenha os dados de origem, poderá recarregá-los a partir da origem.
Isso requer a interrupção da tarefa.
-
Clique em
, depois em Recriar tabelas.
Baixando dados de validação
Você pode baixar os dados de Erros de validação, Alterações de design e Progresso da preparação:
-
Clique
para download.
Os dados são baixados como um arquivo CSV para os downloads do seu navegador.
Limitações
-
No Google BigQuery, se você excluir ou renomear uma coluna, isso recriará a tabela e resultará em perda de dados.