
Criando e gerenciando projetos de pipeline de dados
Você pode criar um pipeline de dados para realizar toda a integração de dados em um projeto usando tarefas de dados. A integração move dados para o projeto a partir de fontes de dados que estão no local ou na nuvem e armazena os dados em conjuntos de dados prontos para consumo. Você pode integrar dados a um armazém de dados ou ao Qlik Open Lakehouse.
Ao integrar dados a um armazém de dados, você também pode executar transformações e criar datamarts para aproveitar seus conjuntos de dados gerados e transformados. O pipeline de dados pode ser simples e linear, ou pode ser um pipeline complexo que consome diversas fontes de dados e gera muitas saídas.
Todas as tarefas de dados serão criadas no mesmo espaço do projeto ao qual pertencem.
Você também pode visualizar a linhagem para rastrear dados e transformações de dados de trás para frente até a fonte original e realizar análises de impacto que mostram a visão prospectiva e de downstream da tarefa de dados, conjunto de dados ou dependências de campo. Para obter mais informações, consulte Trabalhando com a análise de linhagem e de impacto no Data Integration.
Integrando dados em um armazém de dados
Isso inclui aterrisar os dados em uma área de teste e, em seguida, armazenar os conjuntos de dados em um armazém de dados na nuvem. As tarefas de dados de aterrissagem e de armazenamento são criadas em uma única etapa. Se precisar, você também pode realizar a aterrisagem e o armazenamento com tarefas separadas.
Integrando dados no Qlik Open Lakehouse
Crie um projeto de pipeline do Qlik Open Lakehouse para copiar dados de qualquer fonte suportada para o formato de tabela aberta do Iceberg. Tabelas podem ser acessadas e consultadas a partir do seu mecanismo de análise de armazém de dados na nuvem, sem duplicar dados usando uma Tarefa de espelhamento de dados.
Registrando dados que já estão na plataforma de dados
Registre dados que já existem na plataforma de dados para organizar e transformar dados e criar data marts. Isso permite que você use dados integrados a outras ferramentas além do Qlik Talend Data Integration, por exemplo, Qlik Replicate, ou Stitch.
Transformando dados
Crie transformações reutilizáveis em nível de linha nos dados integrados com base em regras e SQL personalizado. Isso cria uma tarefa de transformação de dados.
Criando e gerenciando datamarts
Crie um datamart para aproveitar seus conjuntos de dados. Isso cria uma tarefa de dados de Datamart.
Criando datamarts de conhecimento
Crie um datamart de conhecimento para incorporar e armazenar seus dados estruturados e não estruturados em um banco de dados vetorial. Isso cria uma tarefa de dados de datamart de conhecimento.
Plataformas de dados de destino
O projeto está associado a uma plataforma de dados usada como destino para todas as saídas.
Para obter mais informações sobre plataformas de dados compatíveis, consulte Configurando conexões com destinos.
Introdução em vídeo a projetos
Exemplo de criação de um projeto
O exemplo a seguir realiza a integração de dados, a transformação dos dados e a criação de um datamart. Isso criará um pipeline de dados linear simples que você poderá expandir integrando mais fontes de dados, criando mais transformações e adicionando as tarefas de dados geradas ao datamart.
Exemplo de um pipeline de dados linear em um projeto

-
Crie um novo projeto.
Em Integração de Dados > Projetos de pipeline, clique em Criar novo > Projeto.
-
Insira um nome e uma descrição para o projeto.
Nota informativaSe você ativar posteriormente o controle de versão para o projeto, não poderá alterar o nome do projeto enquanto ele estiver sob controle de versão. -
Selecione um espaço para criar o projeto. Todas as tarefas de dados serão criadas no espaço do projeto ao qual pertencem.
- Selecione Pipeline de dados em Caso de uso.
-
Selecione qual plataforma de dados usar no projeto.
-
Selecione uma conexão com o armazém de dados na nuvem que você deseja usar no projeto. Isso será usado para acessar arquivos de dados e armazenar conjuntos de dados e exibições. Se você ainda não preparou uma conexão, crie uma com Criar nova.
-
Se você selecionou o Google BigQuery, o Databricks ou o Microsoft Azure Synapse Analytics como plataforma de dados, você também precisa se conectar a uma área de teste.
-
Se você selecionou o Snowflake como plataforma de dados, pode optar por transferir os dados para o armazenamento em nuvem. Consulte Transferindo dados para um lakehouse.
-
Se você selecionou o Qlik Cloud como plataforma de dados:
Você pode armazenar dados no armazenamento gerenciado da Qlik ou em seu próprio compartimento gerenciado do Amazon S3. Se você quiser usar seu próprio compartimento do Amazon S3, precisará selecionar uma conexão com esse compartimento.
Em ambos os casos, você também precisa selecionar uma conexão com uma área de preparação do Amazon S3. Se você usar o mesmo compartimento que definiu na etapa anterior, certifique-se de usar outra pasta no compartimento para teste.
-
-
Clique em Criar.
O projeto é criado, e você pode criar seu pipeline de dados adicionando tarefas de dados.
-
-
Integrar os dados
No projeto, clique em Criar e depois em Integrar dados.
Para obter mais informações, consulte Integrando dados em um armazém de dados.
Isso criará uma tarefa de aterrisagem de dados e uma tarefa de armazenamento de dados. Para começar a replicar dados, você precisa:
-
Preparar e executar a tarefa de aterrisagem de dados.
Para obter mais informações, consulte Aterrissagem de dados de fontes de dados.
-
Preparar e executar a tarefa de dados de armazenamento.
Para obter mais informações, consulte Armazenando conjuntos de dados.
-
-
Transformando os dados
Quando a tarefa de armazenamento de dados for criada, volte para o projeto. Agora, você pode realizar transformações nos conjuntos de dados criados.
Clique em ... na tarefa de armazenamento de dados e selecione Transformar dados para criar uma tarefa de transformação de dados com base nessa tarefa de armazenamento de dados. Para obter instruções sobre transformações, consulte Transformando dados.
-
Criando um datamart
Você pode criar um datamart com base em uma tarefa de armazenamento de dados ou em uma tarefa de transformação de dados.
Clique em ... na tarefa de dados e selecione Criar datamart para criar uma tarefa de dados de datamart. Para obter instruções sobre como criar um datamart, consulte:
Depois de realizar o primeiro carregamento total dos conjuntos de dados e datamarts armazenados e transformados, você pode usá-los em um aplicativo de análise, por exemplo. Para obter mais informações sobre como criar aplicativos de análise, consulte Criando um aplicativo de análise usando conjuntos de dados gerados no Data Integration.
Você também pode expandir o pipeline de dados integrando mais fontes de dados e combiná-las na transformação ou no datamart.
Construindo pipelines entre projetos
Você pode criar pipelines entre projetos onde uma tarefa pode consumir tarefas de outro projeto. Isso permite que você alcance a segmentação de várias maneiras possíveis:
-
Você pode criar um pipeline de movimentação de dados separado para cada unidade organizacional e consumir as saídas em um único pipeline de datamart.
-
Você pode criar um único pipeline de movimentação de dados e consumir a saída em vários pipelines de transformação.
Tarefas de transformação e de datamart podem consumir tarefas de armazenamento e transformação localizadas em outro projeto.
-
Você deve ter pelo menos a função Pode consumir no espaço do projeto consumido.
-
Ambos os projetos devem estar na mesma plataforma de dados.
Todos os conjuntos de dados de uma tarefa são compartilhados com projetos downstream. Isso significa que, se você quiser obter a segregação do conjunto de dados, deverá filtrar os conjuntos de dados no projeto consumido criando uma tarefa de transformação.
Na visualização de projetos, você pode visualizar tarefas que são consumidas por outro projeto e tarefas de outros projetos que são consumidas no projeto atual. Todas as tarefas fora do projeto atual estão em cinza. As dependências são por referência e não por nome, o que significa que você pode renomear uma tarefa sem quebrar a referência. Isso também significa que, se você excluir uma tarefa que foi consumida e criar uma nova tarefa com o mesmo nome, a referência ainda será interrompida.
Há várias maneiras de reutilizar os dados existentes:
-
Criando um novo projeto
Selecione a opção Usar dados de outro projeto depois de criar um projeto.
Você pode criar uma transformação ou um datamart, consumindo dados integrados de outro pipeline.
-
Em uma tarefa de transformação ou de datamart, você pode selecionar dados de outro projeto em Selecionar dados de origem.
Ao selecionar dados de origem, selecione Projeto. Se o projeto selecionado estiver sob controle de versão, selecione uma Ramificação. A ramificação padrão é a principal. A lista de tarefas de dados é atualizada para refletir a ramificação selecionada. Em seguida, selecione uma tarefa de dados para ver quais conjuntos de dados estão disponíveis.
Você pode escolher se deseja exibir tarefas em outros projetos que consomem uma tarefa nesse projeto.
-
Clique em Camadas e ative ou desative Saída entre projetos.
Todas as tarefas fora do projeto atual estão em cinza.
Limitações do controle de versão
Como os pipelines entre projetos são divididos entre vários projetos, isso aumenta a complexidade ao usar o controle de versão. Nesses exemplos, Projeto1 é consumido pelo Projeto2.
Exemplo de pipeline entre projetos

-
Projeto2 pode consumir uma ramificação específica de Projeto1. Selecione a ramificação em Selecionar dados de origem na tarefa de transformação ou de datamart. A ramificação padrão é a principal. Se o projeto referenciado não estiver sob controle de versão, o seletor de ramificação não será exibido e Projeto2 usará o projeto como está.
-
Você pode criar uma ramificação para o Projeto1, mas a versão ramificada não mostrará que é consumida pelo Projeto2.
-
Você pode mesclar o Projeto2 com o principal, mas a dependência ainda existirá.
Se a ramificação selecionada em Projeto1 for excluída posteriormente, a referência será quebrada da mesma forma que quando uma tarefa referenciada é excluída. Se a tarefa referenciada tiver uma saída diferente na ramificação selecionada, a referência se comportará da mesma forma que quando a saída da tarefa referenciada muda.
Melhores práticas
-
Verifique se as tarefas no projeto consumido estão pelo menos preparadas, para garantir que sejam válidas.
-
Se você estiver planejando exportar e importar projetos entre locatários, será mais fácil se você mantiver os mesmos nomes para espaços e projetos nos locatários. Se os nomes forem diferentes, você precisará mapear os projetos e as tarefas ao importar o projeto.
-
Se você quiser alterar a plataforma de dados usando exportação e importação, todos os projetos com dependências devem estar na mesma plataforma.
Siga estes passos para uma troca de plataforma fácil e segura. Neste exemplo, o projeto que é consumido é chamado de Consumido, e o projeto que lê Consumido é chamado de Consumidor.
-
Exporte Consumido e Consumidor.
-
Importe Consumido para Consumed_New, alterando para a nova plataforma de dados.
-
Importe Consumidor para Consumer_New, mudando para a mesma plataforma de dados de Consumed_New e substituindo o projeto de dados de origem (Consumido) por Consumed_New.
-
Operações em um projeto de pipeline de dados
Você pode executar as mesmas operações que estão disponíveis para uma tarefa de dados como operações de projeto. Isso permite que você orquestre as operações no pipeline de dados.
-
Ative e desative agendamentos
-
Executar operações de design
-
Iniciar e parar a execução de tarefas de dados
-
Excluir tarefas de dados
Clique em Operações para visualizar o status de uma operação em andamento ou a última operação executada.
Você pode interromper uma operação em andamento clicando em Parar operação. As tarefas de dados em andamento não serão interrompidas, mas cancelarão qualquer tarefa que ainda não tenha sido iniciada.
Ativando e desativando agendamentos
Você pode controlar os agendamentos para tarefas de dados no nível do projeto.
-
Clique em ... e em Agendar.
Você pode ativar ou desativar o agendamento para todas as tarefas de dados ou para uma seleção de tarefas. Somente as tarefas com agendamento definido são exibidas.
Nota informativaEsta opção não está disponível para projetos com o Qlik Cloud como plataforma de dados.
Para obter mais informações sobre como agendar tarefas de dados individuais, consulte:
Executando operações de design
Você pode executar operações de design em todas as tarefas de dados no projeto ou em uma seleção de tarefas. Isso facilita o controle das tarefas do conjunto de dados no projeto, em vez de executar as operações de design individualmente em cada tarefa.
-
Validar
Clique em Validar para validar todas as tarefas ou uma seleção de tarefas. As tarefas de dados que foram alteradas desde a última operação de validação são pré-selecionadas.
As tarefas de dados são validadas na ordem do pipeline.
-
Preparar
Clique em Preparar para preparar todas as tarefas ou uma seleção de tarefas. As tarefas de dados que foram alteradas desde a última operação de preparação são pré-selecionadas.
Você pode optar por recriar conjuntos de dados que requerem uma alteração de estrutura não suportada pela plataforma de dados. Isso pode levar a perda de dados.
-
Recriar
Clique em ... e em Recriar tabelas para recriar os conjuntos de dados da origem para todas as tarefas ou para uma seleção de tarefas.
Nota informativaSe houver problemas com tabelas individuais, é recomendável tentar primeiro recarregar as tabelas em vez de recriá-las. A recriação de tabelas pode causar perda de dados históricos. Se houver alterações significativas, você também deverá preparar tarefas de dados downstream que consomem os dados recriados.
Executando tarefas de dados
Você pode iniciar a execução de todas as tarefas de dados no projeto ou em uma seleção de tarefas, em vez de executar tarefas individualmente. Por exemplo, você pode executar todas as tarefas com uma programação baseada em tempo. Isso iniciará tarefas downstream com uma programação baseada em eventos.
-
Executar
Clique em Executar para iniciar a execução de todas as tarefas, ou uma seleção de tarefas. Isso inicia a execução de todas as tarefas selecionadas e é concluída assim que elas começam a ser executadas.
Você pode selecionar todas as tarefas que estão prontas para serem executadas. Tarefas com agendamento baseado em tempo e tarefas que usam CDC são pré-selecionadas. As tarefas com programação baseada em eventos não são pré-selecionadas, pois serão executadas quando tiverem dados para processar.
Em um projeto com o Qlik Cloud como plataforma de dados, todas as tarefas de pouso e armazenamento são pré-selecionadas.
Nota informativaTodas as tarefas de dados são executadas em paralelo. Isso significa que as verificações de dependência podem impedir a execução de algumas tarefas. -
Parar
Clique em Parar para interromper todas as tarefas ou uma seleção de tarefas.
Você pode selecionar entre as tarefas que estão em execução.
Excluindo tarefas de dados
-
Clique em Excluir para excluir todas as tarefas de dados no projeto ou uma seleção de tarefas.
Não é possível excluir tarefas em execução ou tarefas que são usadas por outras tarefas.
Alterando a exibição de um projeto
Há duas exibições diferentes de projeto. Você pode alternar entre essas exibições clicando em Exibição do pipeline.
-
A exibição do pipeline mostra o fluxo de dados das tarefas de dados.
Você pode escolher a quantidade de informações a serem mostradas para as tarefas de dados clicando em Camadas. Ative ou desative as seguintes informações:
-
Status
-
Originalidade dos dados
-
Agendar
-
Saída entre projetos
Isso exibirá tarefas em outros projetos que consomem uma tarefa neste projeto. Todas as tarefas fora do projeto atual estão em cinza.
-
-
A exibição de cartão mostra uma exibição de cartão com informações sobre a tarefa de dados.
Você pode filtrar por tipo de ativo e proprietário.
Excluindo um projeto
-
Na exibição Pipeline, clique em
 em um projeto e selecione Excluir.
em um projeto e selecione Excluir.
Selecione Manter tabelas e exibições criadas pelas tarefas neste projeto para reter tabelas e exibições que normalmente seriam descartadas após a exclusão de um projeto. Observe que, para os seguintes tipos de tarefa, tabelas e exibições sempre serão mantidas, mesmo quando esta opção não estiver selecionada:
-
Tarefas de aterrisagem
-
Tarefas de aterrisagem no lake
-
Tarefas de replicação
Exibição de dados
Você pode visualizar uma amostra dos dados para ver e validar a forma dos seus dados enquanto projeta seu pipeline de dados.
As seguintes permissões são necessárias:
-
A visualização de dados está habilitada no nível do locatário no Administração.
Ative ConfiguraçõesControle de recursosVisualizando dados em Data Integration.
-
Você recebeu a função Pode visualizar dados no espaço onde reside a conexão.
-
Você recebeu a função Pode visualizar no espaço onde reside o projeto.
Para visualizar dados de amostra na exibição do pipeline de dados:
-
Clique em
 no banner de visualização na parte inferior da exibição do pipeline.
no banner de visualização na parte inferior da exibição do pipeline. -
Selecione para qual tarefa de dados visualizar os dados.
Uma amostra dos dados é exibida. Você pode definir quantas linhas de dados incluir na amostra com Número de linhas.
Exportando e importando projetos
Você pode exportar um projeto para um arquivo JSON que contém tudo o que é necessário para reconstruir esse projeto. O arquivo JSON exportado pode ser importado no mesmo locatário ou em outro locatário. Você pode usar isso, por exemplo, para mover projetos de um locatário para outro ou para fazer cópias de backup de projetos.
Para obter mais informações, consulte Exportando e importando pipelines de dados.
Alterando o proprietário de um projeto
Tarefas de dados operam no contexto do proprietário do projeto ao qual pertencem. Você pode alterar o proprietário de um projeto para transferir o controle de todas as tarefas no projeto de dados para outro usuário. Isso é útil, por exemplo, se houver projetos que pertençam a um usuário que foi excluído.
-
Na exibição do projeto, clique em ... e depois em Alterar proprietário.
A alteração de propriedade se aplicará a todas as tarefas do projeto. Todos os conjuntos de dados catalogados criados por tarefas no projeto também mudarão de proprietário.
Alterando a conexão da plataforma de dados
Se você alterar a conexão da Plataforma de dados de um projeto, deverá:
-
Recriar tabelas em todas as tarefas de aterrisagem.
-
Prepare todas as outras tarefas do projeto.
Visualizando informações do projeto
Clique em ![]() na barra de menu para visualizar informações do projeto, como:
na barra de menu para visualizar informações do projeto, como:
-
Proprietário
-
Espaço
-
Plataforma de dados
-
ID do projeto
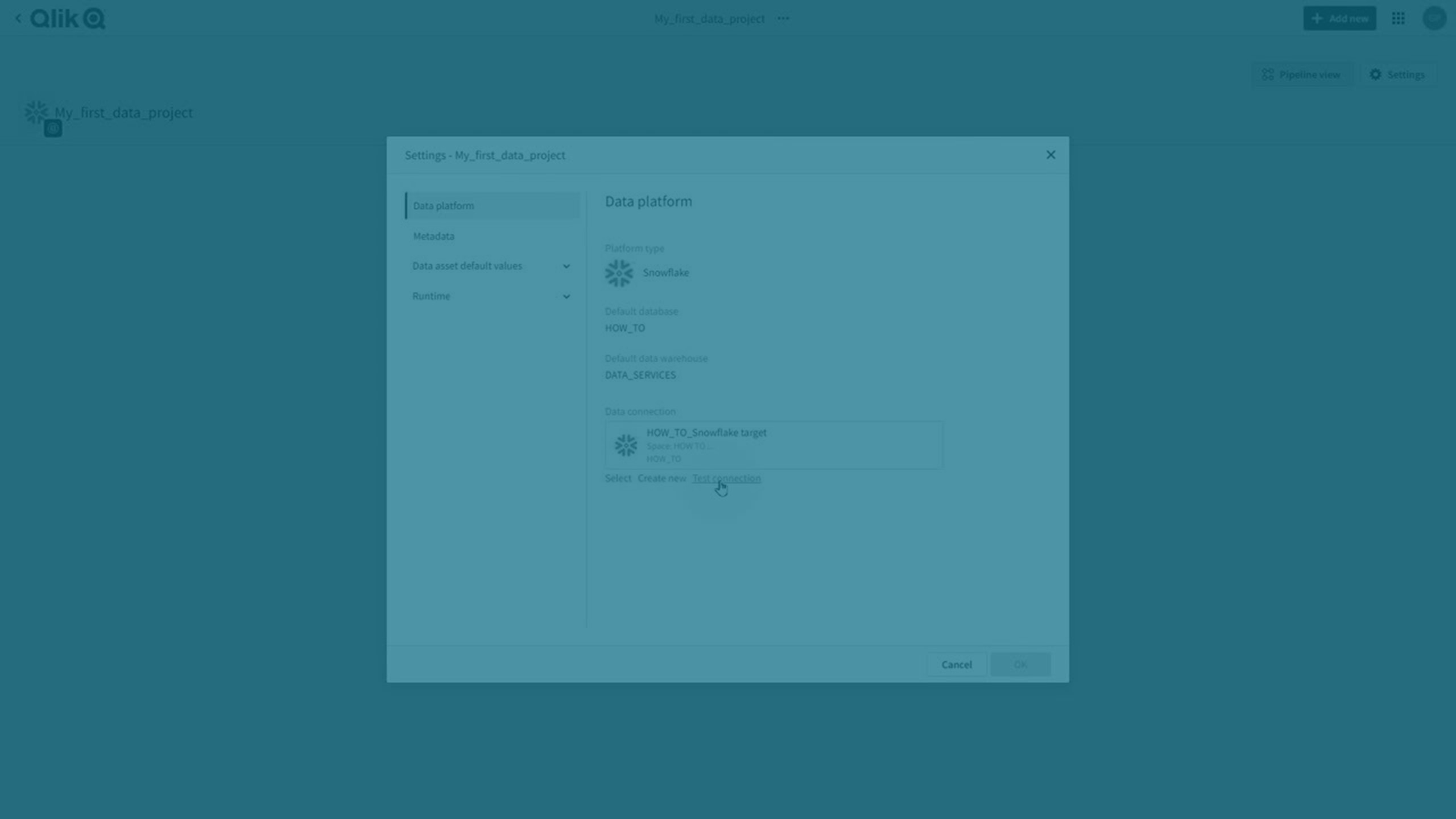
Configurações do projeto
Você pode definir propriedades que são comuns ao projeto e a todas as tarefas de dados incluídas.
-
Clique em Configurações.
Para obter mais informações, consulte Configurações do projeto de pipeline de dados.