
Gegevensverzamelingen beheren
U kunt de gegevensverzamelingen die zijn opgenomen in gegevenstaken voor Tussenopslag, Opslag, Transformatie, Datamart, Streaming tussenopslag, Streaming transformatie en Replication beheren om transformaties te maken, de gegevens te filteren en kolommen toe te voegen.
De opgenomen gegevensverzamelingen worden vermeld onder Gegevensverzamelingen in de weergave Ontwerp. Met de kolomkiezer kunt u selecteren welke kolommen worden weergegeven (![]() ).
).
Gegevensverzamelingen in de weergave Ontwerp van een gegevenstaak

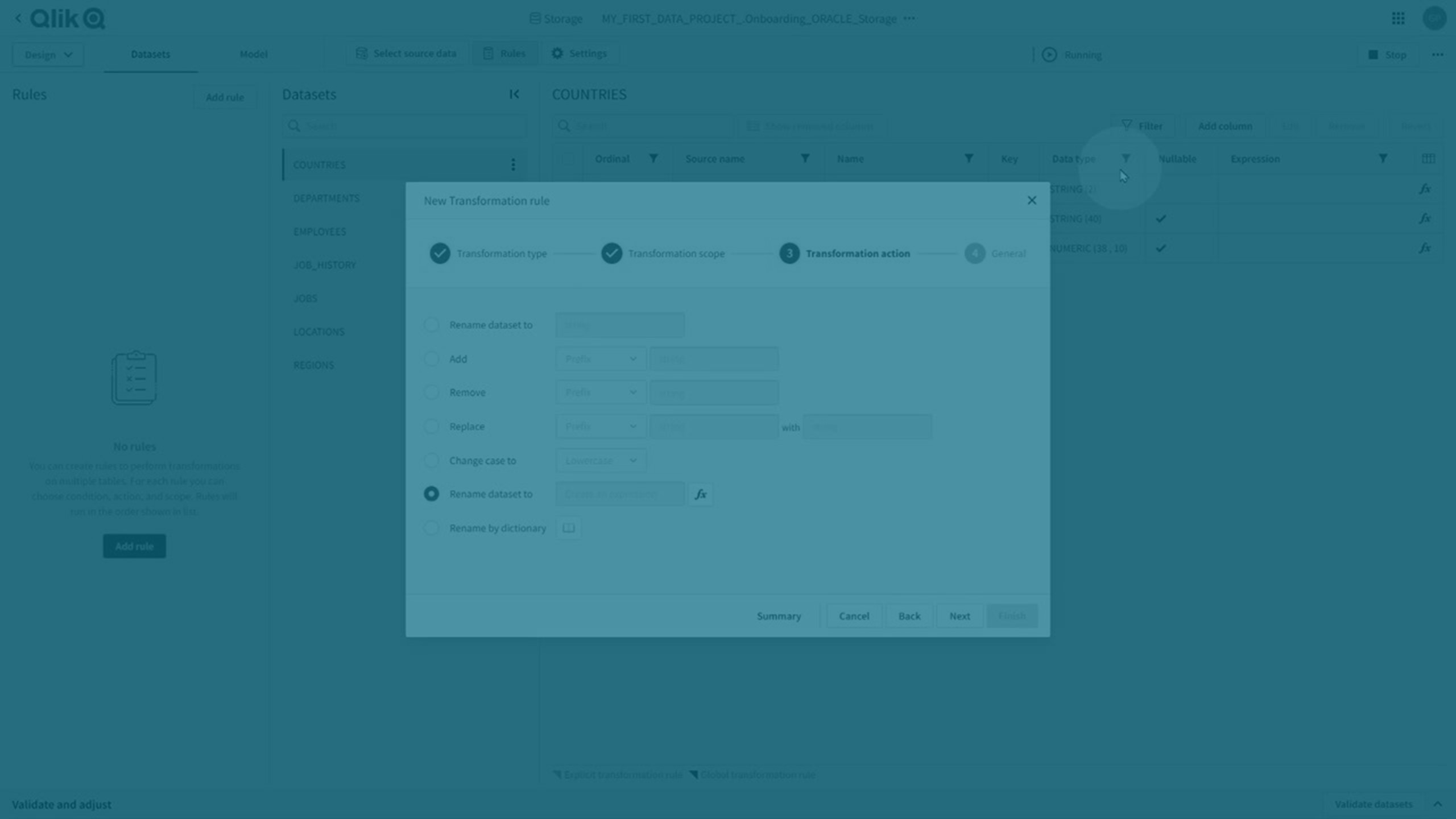
Transformatieregels en expliciete transformaties
U kunt zowel algemene als expliciete transformaties uitvoeren.
Transformatieregels
U kunt globale transformaties uitvoeren door een transformatieregel aan te maken die % gebruikt als jokerteken in de scope en deze toe te passen op alle overeenkomstige datasets.
-
Klik op Regels, en vervolgens op Regel toevoegen om een nieuwe transformatieregel te creëren.
Ga voor meer informatie naar Regels maken om datasets te transformeren.
Transformatieregels worden aangegeven door een donkerpaarse hoek op het kenmerk
Expliciete transformaties
Expliciete transformaties worden gecreëerd:
-
Wanneer u een kolomkenmerk wijzigt met Bewerken,
-
wanneer u Naam wijzigen toepast op een gegevensverzameling,
-
wanneer u een kolom toevoegt.
Expliciete transformaties gaan boven algemene transformaties en worden aangegeven met een donkerpaarse hoek op het betreffende kenmerk.
Gegevensverzamelingsmodel
Gegevensverzamelingen kunnen zowel bron- als doelgebaseerd zijn, afhankelijk van het taaktype en de bewerkingen in de taak. Het gebruikte gegevensverzamelingsmodel beïnvloedt het gedrag van de pijplijn bij bronwijzigingen en welke bewerkingen u kunt uitvoeren.
-
Brongebaseerde gegevensverzamelingen
De gegevensverzameling is gebaseerd op brongegevensverzamelingen en bevat alleen wijzigingen in de metagegevens. Een wijziging in de brongegevens wordt automatisch toegepast, wat kan leiden tot wijzigingen in alle downstreamtaken. Het is niet mogelijk om de volgorde van kolommen te wijzigen of de brongegevensverzameling te wijzigen.
De volgende taaktypen maken altijd gebruik van een brongebaseerd gegevensverzamelingsmodel: tussenopslag, opslag, geregistreerde gegevens, replicatie en tussenopslag in een datalake.
-
Doelgebaseerde gegevensverzamelingen
De gegevensverzameling is gebaseerd op de metagegevens van het doel. Als een kolom vanuit de bron wordt toegevoegd of verwijderd, wordt deze niet automatisch toegepast op de volgende downstreamtaak. U kunt ook de volgorde van kolommen wijzigen en de brongegevensverzameling wijzigen. Dit betekent dat de taak meer autonoom is en dat u het effect van wijzigingen in de bron kunt controleren.
De volgende taaktypen kunnen gebruik maken van een doelgebaseerd gegevensverzamelingsmodel: transformeren, datamart. In sommige gevallen wordt op basis van de bewerking een brongebaseerd model gebruikt voor transformatietaken.
-
Als een SQL-transformatie of een transformatiestroom een kolomselectie uitvoert, wordt de gegevensverzameling doelgebaseerd. Als u bijvoorbeeld SELECT A, B, C from XYZ gebruikt in een SQL-transformatie of de processor Kolommen selecteren gebruikt in een transformatiestroom.
-
Als de standaardkolommen worden behouden, is de gegevensverzameling brongebaseerd. Bijvoorbeeld als u SELECT * from XYZ gebruikt in een SQL-transformatie.
-
Projecten bijwerken van een brongebaseerd model naar een brongebaseerd model
Bestaande projecten worden indien mogelijk bijgewerkt naar het doelgebaseerde gegevensverzamelingsmodel. U wordt door het bijwerkingsproces begeleid als u voor het eerst een project opent. Er zijn enkele overwegingen bij het importeren en exporteren van projecten met verschillende gegevensverzamelingen.
-
Het is niet mogelijk om een project met een brongebaseerd model te importeren naar een project met een doelgebaseerd model.
Importeer het project met een brongebaseerd model naar een nieuw project, werk het nieuwe project bij en exporteer vervolgens het resulterende project. U kunt dit project nu opnieuw importeren naar het project met een doelgebaseerd model.
-
Het is niet mogelijk om een project met een doelgebaseerd model te importeren naar een project met een brongebaseerd model.
Werk het project bij naar een doelgebaseerd model voordat een project met een doelgebaseerd model wordt geïmporteerd.
Een gegevensverzameling filteren
U kunt gegevens filteren om desgewenst een subset van rijen te maken.
-
Klik op Filter.
Ga voor meer informatie naar Een dataset filteren.
De naam van een gegevensverzameling wijzigen
U kunt een gegevensverzameling een andere naam geven.
-
Klik op
 van een gegevensverzameling en vervolgens op Bewerken.
van een gegevensverzameling en vervolgens op Bewerken.
Kolommen toevoegen
U kunt desgewenst kolommen toevoegen met transformaties op rijniveau.
-
Klik op Kolom toevoegen
Ga voor meer informatie naar Kolommen toevoegen aan een gegevensset.
Een kolom bewerken
U kunt kolomeigenschappen bewerken door een kolom te selecteren en te klikken op Bewerken.
-
Naam
-
Sleutel
Stel een kolom in als primaire sleutel. U kunt ook sleutels instellen door deze te selecteren of te deselecteren in de kolom Sleutel.
-
Null-waarde toegestaan
-
Gegevenstype
Stel het gegevenstype van de kolom in. Voor sommige gegevenstypen kunt u een extra eigenschap instellen, zoals Lengte.
InformatieWanneer u het gegevenstype of de grootte van het gegevenstype van een kolom wijzigt, kan dit gevolgen hebben voor de taken die de dataset gebruiken. Ga voor meer informatie naar Gegevenstypen beheren.
Kolommen verwijderen
U kunt een of meer kolommen uit een gegevensverzameling verwijderen.
-
Selecteer de te verwijderen kolommen en klik op Verwijderen.
Als u verwijderde kolommen wilt zien, klikt u op Verwijderde tabellen weergeven. Verwijderde kolommen zijn doorgestreept. U kunt een verwijderde kolom terughalen door deze te selecteren en te klikken op Herstellen.
Expliciete wijzigingen in kolommen terugdraaien
U kunt alle expliciete wijzigingen in één of meer kolommen terugdraaien.
-
Selecteer de kolommen waarvan u wijzigingen wilt terugdraaien en klik op Herstellen.
Wijzigingen door algemene transformatieregels worden niet teruggedraaid.
Als u een toegevoegde kolom terugdraait, wordt deze verwijderd.
Instellingen van gegevensverzameling
U kunt instellingen voor de gegevensverzameling wijzigen. De standaardinstelling is om de instelling van de gegevenstaak over te nemen, maar u kunt een instelling ook expliciet aan of uit zetten.
-
Klik
 op een gegevensverzameling, en vervolgens Instellingen.
op een gegevensverzameling, en vervolgens Instellingen.
Koptekstkolommen weergeven in weergaven
Voor Qlik Open Lakehouse Streaming tussenopslag- en Transformatietaken kunt u bepalen of de kopkolommen moeten worden weergegeven of verborgen. De opties verschillen per taaktype.
Streaming tussenopslagtaak
Om de koptekstkolommen weer te geven, schakel Koptekstkolommen weergeven in rechts van het zoekvak.
Streaming transformatietaak
Rechts van het zoekvak vindt u een vervolgkeuzelijst met de volgende opties.
-
Koptekstkolommen verbergen: De standaard.
-
Koptekstkolommen tonen
-
Standaard: Selecteer om koptekstkolommen voor standaardweergaven weer te geven.
-
Geschiedenis: Selecteer om koptekstkolommen weer te geven voor geschiedenisweergaven. Let op: deze optie is alleen beschikbaar als Een historische gegevensopslag aanmaken (Type 2) is ingeschakeld in de taak- of datasetinstellingen.
-
Ga naar Landingstabellen en Weergaven voor een beschrijving van de beschikbare kopkolommen.
Gegevens weergeven
U kunt een voorbeeld van de gegevens tonen om de vorm van uw gegevens te bekijken en valideren als u uw gegevenspijplijn gaat ontwerpen.
Er moet aan de volgende vereisten worden voldaan:
-
Het weergeven van gegevens is ingeschakeld op tenantniveau in het Beheer-activiteitencentrum.
Om dit in te schakelen, gaat u naar de Instellingen pagina, selecteert u het tabblad Functiebeheer en schakelt u Gegevens bekijken in Gegevensintegratie in.
-
De rol Kan gegevens bekijken is aan u toegewezen in de ruimte waarin de verbinding zich bevindt.
-
De rol Kan bekijken is aan u toegewezen in de ruimte waarin het project zich bevindt.
Bekijken voorbeeldgegevens
Om voorbeeldgegevens weer te geven op het tabblad Gegevensverzameling in de weergave Ontwerp:
-
Klik op Gegevens weergeven.
Er wordt een voorbeeld van de gegevens weergegeven. U kunt met Aantal rijen instellen hoeveel gegevensrijen in het voorbeeld worden opgenomen.
Inzicht in gegevensstructuur
Het gegevensvoorbeeld geeft zowel bedrijfskolommen als door het systeem gegenereerde kolommen weer. Bij het bekijken van gegevens uit streaming datasets, bieden headerkolommen (voorzien van het voorvoegsel hdr__) metadata over de gegevensbron en transformaties. Voorbeelden zijn hdr__from_timestamp (wanneer gegevens werden geladen) en hdr__operation (type bewerking toegepast).
Koptekstkolommen zijn alleen-lezen en kunnen niet worden gewijzigd of verwijderd uit het voorbeeld. Om te bepalen welke kopteksten standaard worden weergegeven, configureert u standaardweergavekopteksten op project- of datasetniveau.
Wisselen tussen gegevensverzamelingen en tabellen
Om te wisselen tussen gegevensverzamelingen en tabellen:
-
Selecteer Gegevensverzamelingen om de logische weergave van de gegevens te tonen.
-
Selecteer Fysieke objecten om de fysieke weergave in de database evenals in de tabellen en weergaven te tonen.
NieuwsDeze optie is niet beschikbaar als de fysieke weergave nog niet is gemaakt.
Filters
U kunt de voorbeeldgegevens op twee manieren filteren:
-
Gebruik
 om te filteren welke voorbeeldgegevens worden opgehaald.
om te filteren welke voorbeeldgegevens worden opgehaald.Als u het filter ${OrderYear}>2023 gebruikt en Aantal rijen is ingesteld op 10, krijgt u een voorbeeld met 10 orders van 2024.
-
U kunt de voorbeeldgegevens sorteren op een specifieke kolom.
Dit is alleen van invloed op de bestaande voorbeeldgegevens. Als u
hebt gebruikt om alleen orders van 2024 op te nemen en u stelt de kolomfilter in om orders van 2022 te tonen, dan krijgt u een leeg resultaat.
Sorteren
U kunt de voorbeeldgegevens ook sorteren op een specifieke kolom. Het sorteren is allleen van invloed op de bestaande voorbeeldgegevens. Als u ![]() hebt gebruikt om alleen orders van 2024 op te nemen en u keert de sorteervolgorde om, dan bevatten de voorbeeldgegevens nog steeds alleen orders van 2024.
hebt gebruikt om alleen orders van 2024 op te nemen en u keert de sorteervolgorde om, dan bevatten de voorbeeldgegevens nog steeds alleen orders van 2024.
Kolommen verbergen
U kunt de kolommen verbergen in de gegevensweergave:
-
Verberg een afzonderlijke kolom door te klikken op
op de kolom en vervolgens op Kolom verbergen. -
Verberg meerdere kolommen door te klikken op
op een kolom en vervolgens op Kolommen weergeven. Hiermee kunt u de zichtbaarheid voor alle kolommen in de weergave beheren.
Het downloaden van de voorbeeldgegevens
U kunt de weergegeven voorbeeldgegevens downloaden:
-
Klik
 om de inhoud van de voorbeeldgegevensweergave te downloaden.
om de inhoud van de voorbeeldgegevensweergave te downloaden.
De voorbeeldgegevens worden gedownload als een CSV-bestand naar de downloads van uw browser.
Valideren en aanpassen van de gegevensverzamelingen
U kunt alle gegevensverzamelingen valideren die zijn opgenomen in de gegevenstaak.
Vouw Valideren en aanpassen uit om alle validatiefouten en ontwerpwijzigingen te zien.
Gegevensverzamelingen valideren
-
Klik op Gegevensverzamelingen valideren om de gegevensverzamelingen te valideren.
Validatie omvat het controleren of:
-
alle tabellen een primaire sleutel hebben,
-
er geen ontbrekende kenmerken zijn,
-
er geen dubbele tabel- of kolomnamen zijn.
Verder krijgt u een lijst met ontwerpwijzigingen in vergelijking met de bron:
-
toegevoegde tabellen en kolommen
-
verwijderde tabellen en kolommen
-
hernoemde tabellen en kolommen
-
gewijzigde primaire sleutels en gegevenstypen
Vouw Valideren en aanpassen uit om alle validatiefouten en ontwerpwijzigingen te zien.
-
Herstel de validatiefouten en valideer de gegevensverzamelingen opnieuw.
-
De meeste ontwerpwijzigingen kunnen automatisch worden aangepast, behalve gewijzigde primaire sleutels of gegevenstypen. In dit geval moet u de gegevensverzamelingen synchroniseren.
De gegevensverzamelingen voorbereiden
U kunt gegevensverzamelingen voorbereiden om ontwerpwijzigingen waar mogelijk zonder verlies van gegevens aan te passen. Als er ontwerpwijzigingen zijn die niet kunnen worden aangepast zonder gegevensverlies, hebt u de mogelijkheid om tabellen van de bron opnieuw te maken met gegevensverlies.
Hiervoor moet de taak worden gestopt.
-
Klik op
 en vervolgens op Voorbereiden.
en vervolgens op Voorbereiden.
Wanneer de gegevensverzamelingen zijn voorbereid, valideert u de gegevensverzamelingen voordat u de opslagtaak opnieuw start.
Gegevensverzamelingen opnieuw maken
U kunt de gegevensverzamelingen opnieuw maken vanuit de bron. Als u een gegevensverzameling opnieuw maakt, gaan er gegevens verloren. Zolang u beschikt over de brongegevens kunt u deze laden vanuit de bron.
Hiervoor moet de taak worden gestopt.
-
Klik op
, en klik vervolgens op Tabellen opnieuw maken.
Validatiegegevens downloaden
U kunt de gegevens downloaden van Validatiefouten, Ontwerpaanpassingen en Voortgang voorbereiding:
-
Klik
om te downloaden.
De gegevens worden gedownload als een CSV-bestand naar de downloads van uw browser.
Beperkingen
-
Als u in Google BigQuery een kolom verwijdert of hernoemt, wordt de tabel opnieuw aangemaakt en gaan er gegevens verloren.