
데이터 집합 관리
랜딩, 저장소, 변환, 데이터 마트, 스트리밍 랜딩, 스트리밍 변환 및 복제 데이터 작업에 포함된 데이터 집합을 관리하여 변환을 만들고, 데이터를 필터링하고, 열을 추가할 수 있습니다.
포함된 데이터 집합은 디자인 보기의 데이터 집합 아래에 나열됩니다.열 선택기(![]() )를 사용하여 표시할 열을 선택할 수 있습니다.
)를 사용하여 표시할 열을 선택할 수 있습니다.
데이터 작업의 디자인 보기에 있는 데이터 집합

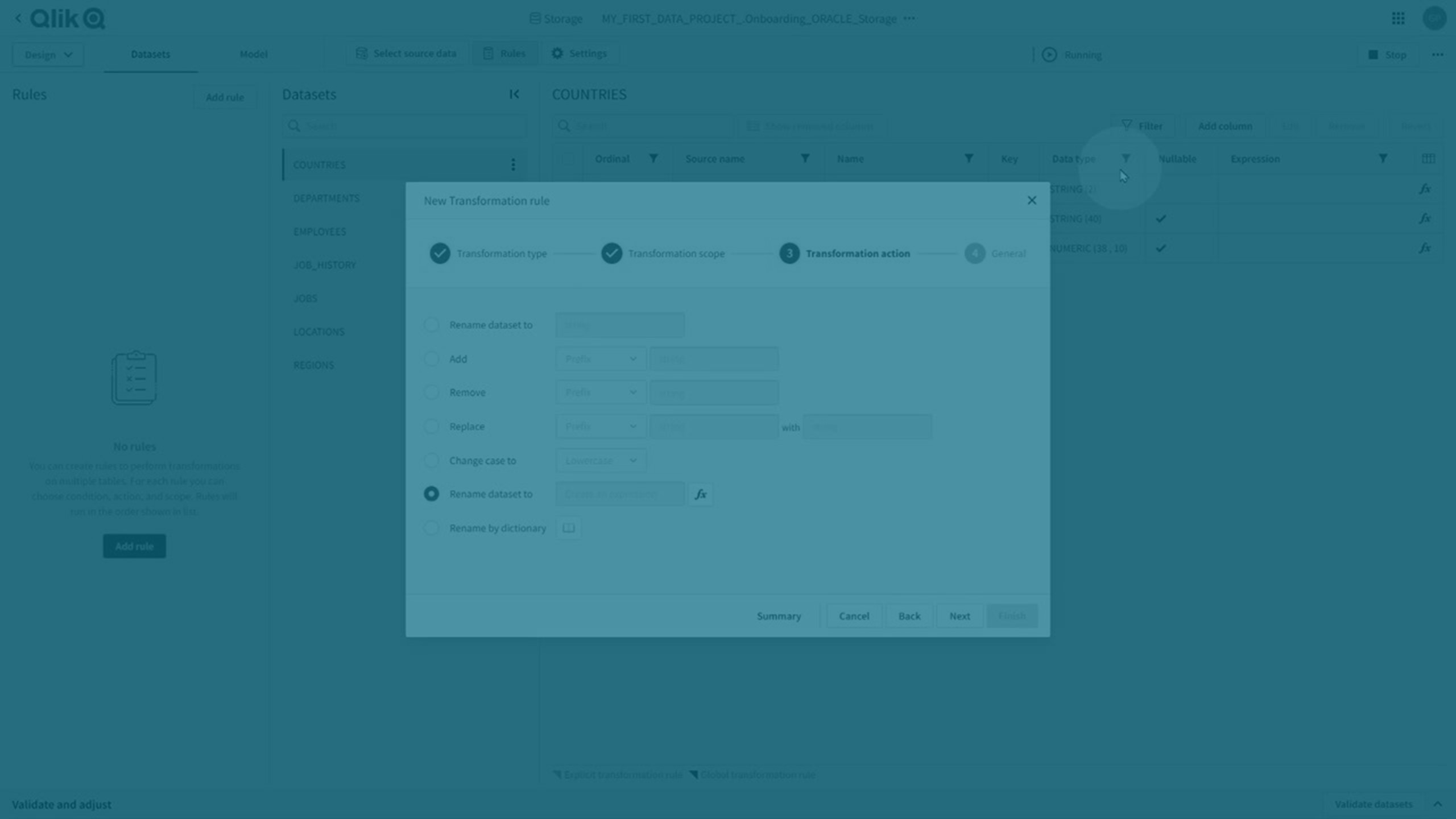
변환 규칙 및 명시적 변환
전역 및 명시적 변환을 모두 수행할 수 있습니다.
변환 규칙
일치하는 모든 데이터 집합에 적용할 범위에서 %를 와일드카드로 사용하는 변환 규칙을 만들어 전역 변환을 수행할 수 있습니다.
-
규칙을 클릭한 다음 규칙 추가를 클릭하여 새 변환 규칙을 만듭니다.
자세한 내용은 데이터 세트를 변환하는 규칙 만들기을 참조하십시오.
변환 규칙은 영향을 받는 특성에서 진한 보라색 모서리로 표시됩니다.
명시적 변환
명시적 변환은 다음과 같은 경우에 만들어집니다.
-
편집을 사용하여 열 특성을 변경하는 경우
-
데이터 집합에서 이름 바꾸기를 사용하는 경우
-
열을 추가하는 경우
명시적 변환은 전역 변환을 재정의하고 영향을 받는 특성에 밝은 자주색 모서리로 표시됩니다.
데이터 집합
데이터 집합은 작업 유형과 작업의 작업에 따라 소스 기반이거나 대상 기반일 수 있습니다.사용되는 데이터 집합 모델은 소스 변경 시 파이프라인의 동작과 수행할 수 있는 작업에 영향을 미칩니다.
-
소스 기반 데이터 집합
이 데이터 집합은 소스 데이터 집합을 기반으로 하며 메타데이터의 변경 내용만 포함합니다.소스 데이터가 변경되면 자동으로 적용되어 모든 다운스트림 작업이 변경될 수 있습니다.열 순서를 변경하거나, 소스 데이터 집합을 변경할 수 없습니다.
다음 작업 유형은 항상 소스 기반 데이터 집합 모델을 사용합니다. 데이터 레이크에서의 랜딩, 저장, 등록된 데이터, 복제 및 랜딩.
-
대상 기반 데이터 집합
데이터 집합은 대상 메타데이터를 기반으로 합니다.소스에서 열이 추가되거나 제거된 경우 해당 열은 다음 다운스트림 작업에 자동으로 적용되지 않습니다.열 순서를 변경하고, 소스 데이터 집합을 변경할 수 있습니다.즉, 작업이 더 독립적이며 소스 변경의 효과를 제어할 수 있습니다.
다음 작업 유형은 대상 기반 데이터 집합 모델을 사용할 수 있습니다. 변환, 데이터 마트.작업에 따라 소스 기반 모델이 변환 작업에 사용되는 경우가 있습니다.
-
SQL 변환이나 변환 흐름이 열 선택을 수행하는 경우 데이터 집합은 대상 기반이 됩니다.예를 들어, SQL 변환에서 SELECT A, B, C from XYZ를 사용하거나 변환 흐름에서 열 선택 프로세서를 사용하는 경우입니다.
-
기본 열이 유지되면 데이터 집합은 소스 기반입니다.예를 들어, SQL 변환에서 SELECT * from XYZ을 사용하는 경우.
-
소스 기반 모델에서 대상 기반 모델로 프로젝트 업데이트
해당되는 경우 기존 프로젝트가 대상 기반 데이터 집합 모델로 업데이트됩니다.프로젝트를 처음 열면 업데이트 과정으로 안내해 드립니다.다양한 데이터 집합 모델이 포함된 프로젝트를 가져오고 내보낼 때 고려해야 할 사항이 몇 가지 있습니다.
-
소스 기반 모델이 있는 프로젝트를 대상 기반 모델이 있는 프로젝트로 가져올 수 없습니다.
소스 기반 모델이 있는 프로젝트를 새 프로젝트로 가져온 다음, 새 프로젝트를 업데이트한 다음 결과 프로젝트를 내보냅니다.이제 이 프로젝트를 대상 기반 모델이 있는 프로젝트로 다시 가져올 수 있습니다.
-
소스 기반 모델이 있는 프로젝트로 대상 기반 모델이 있는 프로젝트를 가져올 수 없습니다.
대상 기반 모델이 포함된 프로젝트를 가져오기 전에 프로젝트를 대상 기반 모델로 업데이트합니다.
데이터 집합 필터링
필요한 경우 데이터를 필터링하여 행의 하위 집합을 만들 수 있습니다.
-
필터를 클릭합니다.
자세한 내용은 데이터 세트 필터링을 참조하십시오.
데이터 집합 이름 바꾸기
데이터 집합의 이름을 바꿀 수 있습니다.
-
데이터 집합에서
 을 클릭하고 편집을 클릭합니다.
을 클릭하고 편집을 클릭합니다.
열 추가
필요한 경우 행 수준 변환이 있는 열을 추가할 수 있습니다.
-
열 추가를 클릭합니다.
자세한 내용은 데이터 세트에 열 추가을 참조하십시오.
열 편집
열을 선택하고 편집을 클릭하여 열 속성을 편집할 수 있습니다.
-
이름
-
키
열을 기본 키로 설정합니다.키 열에서 선택하거나 선택 취소하여 키를 설정할 수도 있습니다.
-
Null 허용
-
데이터 유형
열의 데이터 유형을 설정합니다.일부 데이터 유형의 경우 길이와 같은 추가 속성을 설정할 수 있습니다.
정보 메모컬럼의 데이터 타입 또는 데이터 타입 크기를 변경하면, 해당 데이터셋을 사용하는 태스크에 영향을 미칠 수 있습니다.자세한 내용은 데이터 유형 관리을 참조하십시오.
열 제거
데이터 집합에서 하나 이상의 열을 제거할 수 있습니다.
-
제거할 열을 선택하고 제거를 클릭합니다.
제거된 열을 보려면 제거된 열 표시를 클릭합니다.제거된 열은 취소선이 표시된 텍스트로 나타납니다.제거된 열을 선택하고 되돌리기를 클릭하여 검색할 수 있습니다.
열에 대한 명시적 변경 내용 되돌리기
하나 이상의 열에 대한 모든 명시적 변경 내용을 되돌릴 수 있습니다.
-
변경 내용을 되돌릴 열을 선택하고 되돌리기를 클릭합니다.
전역 변환 규칙의 변경 내용은 되돌릴 수 없습니다.
추가된 열을 되돌리면 제거됩니다.
데이터 집합 설정
데이터 집합에 대한 설정을 변경할 수 있습니다.기본 설정은 데이터 작업의 설정을 상속하는 것이지만 설정을 명시적으로 켜기 또는 끄기로 변경할 수도 있습니다.
-
데이터 집합에서
 을 클릭한 다음 설정을 클릭합니다.
을 클릭한 다음 설정을 클릭합니다.
보기에서 헤더 열 표시
Qlik 오픈 레이크하우스 스트리밍 랜딩 및 변환 작업의 경우, 헤더 열을 표시할지 숨길지 제어할 수 있습니다.옵션은 작업 유형에 따라 다릅니다.
스트리밍 랜딩 작업
헤더 열을 표시하려면 검색 상자 오른쪽에 있는 헤더 열 표시를 켜십시오.
스트리밍 변환 작업
검색 상자 오른쪽에 다음 옵션이 있는 드롭다운 목록이 제공됩니다.
-
헤더 열 숨기기: 기본값입니다.
-
헤더 열 표시
-
표준: 표준 보기에 헤더 열을 표시하려면 선택합니다.
-
기록: 기록 보기에 대한 헤더 열을 표시하려면 선택합니다.이 옵션은 작업 또는 데이터셋 설정에서 기록 데이터 저장소(유형 2) 생성이(가) 활성화된 경우에만 사용할 수 있습니다.
-
사용 가능한 헤더 열에 대한 설명은 랜딩 테이블 및 보기을 참조하십시오.
데이터 보기
데이터 파이프라인을 설계할 때 데이터 샘플을 보고 데이터의 형태의 확인하고 유효성 검사할 수 있습니다.
다음 요구 사항을 충족해야 합니다.
-
데이터 보기는 관리 활동 센터의 테넌트 수준에서 활성화됩니다.
이를 활성화하려면 설정 페이지로 이동하여 기능 제어 탭을 선택한 다음 데이터 통합에서 데이터 보기를 켜십시오.
-
연결이 있는 공간에서 데이터 볼 수 있음 역할이 할당됩니다.
-
프로젝트가 있는 공간에서 볼 수 있음 역할이 할당됩니다.
샘플 데이터 보기
설계 보기의 데이터 집합 탭에서 샘플 데이터를 보려면 다음 단계를 따르십시오.
-
데이터 보기를 클릭합니다.
데이터 샘플이 표시됩니다.행 수를 사용하여 샘플에 포함할 데이터 행 수를 설정할 수 있습니다.
데이터 구조 이해
데이터 미리 보기에는 비즈니스 열과 시스템 생성 열이 모두 표시됩니다.스트리밍 데이터세트에서 데이터를 볼 때, 헤더 열(hdr__로 접두사 붙음)은 데이터 소스 및 변환에 대한 메타데이터를 제공합니다.예시로는 hdr__from_timestamp (데이터가 로드된 시점) 및 hdr__operation (적용된 작업 유형) 등이 있습니다.
헤더 열은 읽기 전용이며 미리 보기에서 수정하거나 제거할 수 없습니다.기본적으로 어떤 헤더를 표시할지 제어하려면 프로젝트 또는 데이터세트 수준에서 표준 보기 헤더를 구성합니다.
데이터 집합과 테이블 간 변경
데이터 집합과 테이블 간을 변경하려면 다음 안내를 따르십시오.
-
데이터의 논리적 표현을 보려면 데이터 집합를 선택합니다.
-
데이터베이스의 물리적 표현을 테이블과 뷰로 보려면 물리적 개체를 선택합니다.
뉴스 메모물리적 표현이 아직 만들어지지 않은 경우에는 이 옵션을 사용할 수 없습니다.
필터링
다음 두 가지 방법으로 샘플 데이터를 필터링할 수 있습니다.
-
 을 사용하여 검색할 샘플 데이터를 필터링합니다.
을 사용하여 검색할 샘플 데이터를 필터링합니다.예를 들어, 필터 ${OrderYear}>2023을(를) 사용하고 행 수가 10으로 설정된 경우, 2024년 주문 10개의 샘플을 가져오게 됩니다.
-
특정 열을 기준으로 샘플 데이터를 필터링합니다.
이는 기존 샘플 데이터에만 영향을 미칩니다.
을 사용하여 2024년 주문만 포함하고 열 필터를 2022년 주문을 표시하도록 설정한 경우 결과는 빈 샘플입니다.
정렬
특정 열을 기준으로 데이터 샘플을 정렬할 수도 있습니다.정렬은 기존 샘플 데이터에만 영향을 미칩니다.![]() 을 사용하여 2024년 주문만 포함하고 역순으로 정렬한 경우 샘플 데이터에는 여전히 2024년 주문만 포함됩니다.
을 사용하여 2024년 주문만 포함하고 역순으로 정렬한 경우 샘플 데이터에는 여전히 2024년 주문만 포함됩니다.
열 숨기기
데이터 보기에서 열을 숨길 수 있습니다.
-
열에서
을 클릭한 다음 열 숨기기를 클릭하여 단일 열을 숨깁니다. -
임의의 열에서
를 클릭한 다음 열 표시를 클릭하여 여러 열을 숨깁니다.이를 통해 보기의 모든 열에 대한 가시성을 제어할 수 있습니다.
샘플 데이터 다운로드
표시된 샘플 데이터를 다운로드할 수 있습니다:
-
샘플 데이터 뷰의 내용을 다운로드하려면
 을(를) 클릭합니다.
을(를) 클릭합니다.
샘플 데이터는 CSV 파일로 브라우저 다운로드에 다운로드됩니다.
데이터 집합 유효성 검사 및 조정
데이터 작업에 포함된 모든 데이터 집합의 유효성을 검사할 수 있습니다.
유효성 검사 및 조정을 확장하여 모든 유효성 검사 오류 및 디자인 변경 사항을 확인합니다.
데이터 집합 유효성 검사
-
데이터 집합 유효성 검사를 클릭하여 데이터 집합의 유효성을 검사합니다.
유효성 검사에는 다음을 확인하는 것이 포함됩니다.
-
모든 테이블에는 기본 키가 있습니다.
-
누락된 특성이 없습니다.
-
중복된 테이블 또는 열 이름이 없습니다.
또한 소스와 비교하여 설계 변경 내용 목록을 얻을 수 있습니다.
-
추가된 테이블 및 열
-
삭제된 테이블 및 열
-
이름이 변경된 테이블 및 열
-
변경된 기본 키 및 데이터 유형
유효성 검사 및 조정을 확장하여 모든 유효성 검사 오류 및 디자인 변경 사항을 확인합니다.
-
유효성 검사 오류를 수정한 다음 데이터 집합의 유효성을 다시 검사합니다.
-
변경된 기본 키 또는 데이터 유형을 제외하고 대부분의 설계 변경 내용은 자동으로 조정될 수 있습니다.이 경우 데이터 집합을 동기화해야 합니다.
데이터 집합 준비
가능한 경우 데이터 손실 없이 설계 변경을 조정하도록 데이터 집합을 준비할 수 있습니다.데이터 손실 없이 조정할 수 없는 설계 변경 내용이 있는 경우 데이터 손실이 있는 소스에서 테이블을 다시 만들 수 있습니다.
이를 위해서는 작업을 중지해야 합니다.
-
 을 클릭한 다음 준비를 클릭합니다.
을 클릭한 다음 준비를 클릭합니다.
데이터 집합이 준비되면 저장소 작업을 다시 시작하기 전에 데이터 집합의 유효성을 검사합니다.
데이터 집합 다시 만들기
소스에서 데이터 집합을 다시 만들 수 있습니다.데이터 집합을 다시 만들면 데이터가 손실됩니다.소스 데이터가 있으면 소스에서 다시 로드할 수 있습니다.
이를 위해서는 작업을 중지해야 합니다.
-
을 클릭한 다음 테이블 다시 만들기를 클릭합니다.
유효성 검사 데이터 다운로드 중
다음에서 데이터를 다운로드할 수 있습니다: 유효성 검사 오류, 설계 변경 및 준비 진행 상황.
-
다운로드하려면
을(를) 클릭합니다.
데이터는 CSV 파일로 브라우저 다운로드에 다운로드됩니다.
제한 사항
-
Google BigQuery에서 열을 삭제하거나 이름을 바꾸면 테이블이 다시 만들어져 데이터가 손실됩니다.