
Zarządzanie zestawami danych
Zestawami danych zawartymi w zadaniach danych do umieszczania, pamięci masowej, transformacji, data mart, umieszczania strumieniowego, transformacji strumieniowej i replikacji można zarządzać w celu tworzenia przekształceń, filtrowania danych i dodawania kolumn.
Lista uwzględnionych zestawów danych znajduje się w obszarze Zestawy danych w widoku Projekt. Kolumny, które mają być wyświetlane, możesz wybrać za pomocą selektora kolumn (![]() ).
).
Zestawy danych w widoku Projekt zadania danych

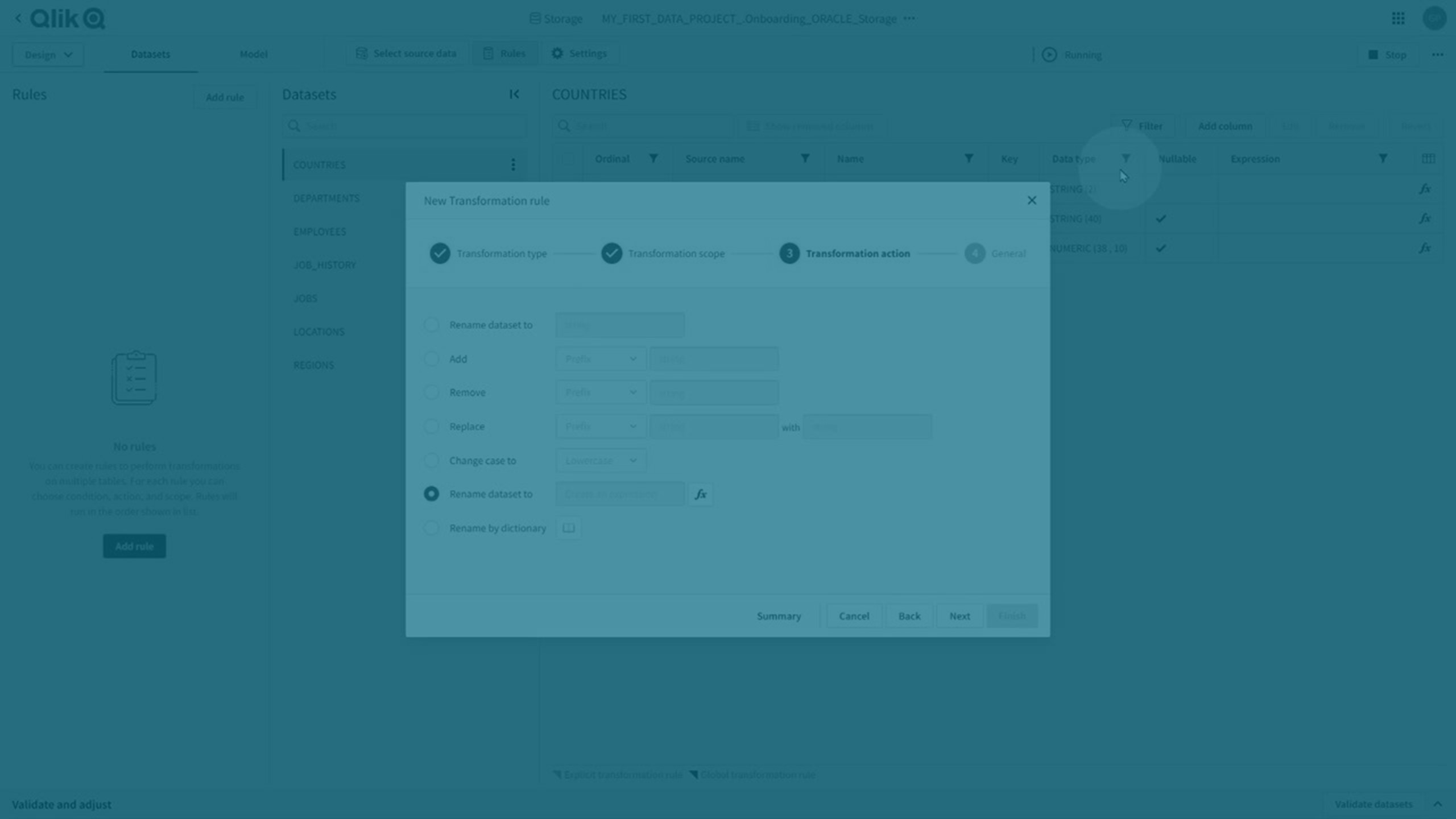
Reguły transformacji i transformacje jawne
Można wykonywać zarówno transformacje globalne, jak i jawne.
Reguły transformacji
Możesz dokonywać transformacji globalnych, tworząc regułę transformacji, która używa symbolu wieloznacznego % w zakresie w celu zastosowania do wszystkich pasujących zestawów danych.
-
Aby utworzyć nową regułę transformacji, kliknij pozycję Reguły, a następnie przycisk Dodaj regułę.
Więcej informacji zawiera temat Tworzenie reguł transformacji zestawów danych.
Reguły transformacji są wskazywane za pomocą ciemnofioletowego narożnika danego atrybutu.
Transformacje jawne
Transformacje jawne tworzy się:
-
Po wybraniu opcji Edytuj w celu zmiany atrybutu kolumny.
-
Po wybraniu opcji Zmień nazwę w zestawie danych.
-
Podczas dodawania kolumny.
Transformacje jawne zastępują transformacje globalne i są wskazane za pomocą jasnofioletowego narożnika danego atrybutu.
Modele zestawów danych
Zestawy danych mogą być oparte na źródle lub oparte na celu, w zależności od rodzaju zadania i operacji w zadaniu. Używany model zestawu danych wpływa na działanie potoku przy zmianach źródła i na to, jakie operacje można wykonywać.
-
Źródłowe zestawy danych
Zestaw danych jest oparty na źródłowych zestawach danych i będzie przechowywał tylko zmiany w metadanych. Zmiana danych źródłowych jest automatycznie stosowana, co może powodować zmiany we wszystkich zadaniach podrzędnych. Nie jest możliwa zmiana kolejności kolumn ani zmiana źródłowego zestawu danych.
Następujące typy zadań zawsze używają zestawu danych opartego na źródle: umieszczanie danych, pamięć masowa, zarejestrowane dane, replikacja oraz umieszczanie danych w jeziorze danych.
-
Zestawy danych oparte na celach
Zestaw danych jest oparty na docelowych metadanych. Jeżeli kolumna zostanie dodana ze źródła lub usunięta, nie zostanie to automatycznie zastosowane do następnego zadania podrzędnego. Możesz zmienić kolejność kolumn i źródłowy zestaw danych. Oznacza to, że zadanie jest bardziej autonomiczne oraz pozwala kontrolować efekt zmian w źródle.
Następujące typy zadań mogą korzystać z modelu zestawu danych opartego na celu: transformacja, data mart. Istnieją przypadki, w których model oparty na źródle jest używany w zadaniach transformacji w zależności od operacji.
-
Jeśli transformacja SQL lub przepływ transformacji dokonuje wyboru kolumny, zestaw danych będzie oparty na celu. Na przykład, jeśli używasz SELECT A, B, C from XYZ w transformacji SQL lub procesora Wybierz kolumny w przepływie transformacji.
-
Jeśli domyślne kolumny zostaną zachowane, zestaw danych będzie oparty na źródle. Na przykład, jeśli używasz SELECT * from XYZ w transformacji SQL.
-
Aktualizowanie projektów z modelu opartego na źródle do modelu opartego na celu.
Dotychczasowe projekty są aktualizowane do modelu danych opartego na celu, gdy jest to uzasadnione. Użytkownik zostanie przeprowadzony przez proces aktualizacji po pierwszym otwarciu projektu. Istnieją pewne kwestie do uwzględnienia podczas importu i eksportu projektów w przypadku różnych modeli zestawów danych.
-
Nie można importować projektu z modelem opartym na źródle do projektu z modelem opartym na celu.
Importuj projekt z modelem opartym na źródle do nowego projektu, zaktualizuj nowy projekt, a następnie wyeksportuj projekt wynikowy. Możesz teraz ponownie zaimportować ten projekt do projektu z modelem opartym na celu.
-
Nie można importować projektu z modelem opartym na celu do projektu z modelem opartym na źródle.
Zaktualizuj projekt do modelu opartego na celu przed zaimportowaniem projektu z modelem opartym na celu.
Filtrowanie zestawów danych
W razie potrzeby można filtrować dane, aby utworzyć podzbiór wierszy.
-
Kliknij Filtruj.
Więcej informacji zawiera temat Filtrowanie zestawu danych.
Zmiana nazwy zestawu danych
Nazwę zestawu danych można zmienić.
-
Kliknij
 na zestawie danych, a następnie Edytuj.
na zestawie danych, a następnie Edytuj.
Dodawanie kolumn
W razie potrzeby można dodać kolumny z transformacjami na poziomie wiersza.
-
Kliknij przycisk Dodaj kolumnę.
Więcej informacji zawiera temat Dodawanie kolumn do zbioru danych.
Edytowanie kolumny
Właściwości kolumny można edytować po wybraniu kolumny i kliknięciu przycisku Edytuj.
-
Nazwa
-
Klucz
Ustaw kolumnę jako klucz podstawowy. Klucze można też ustawić przez zaznaczenie opcji lub anulowanie wyboru w kolumnie Klucz.
-
Nullowalne
-
Typ danych
Ustaw typ danych kolumny. W przypadku niektórych typów danych można ustawić właściwość dodatkową, na przykład Długość.
InformacjaZmiana typu danych lub rozmiaru typu danych kolumny może mieć wpływ na zadania korzystające z zestawu danych. Więcej informacji zawiera temat Zarządzanie typami danych.
Usuwanie kolumn
Z zestawu danych można usunąć co najmniej jedną kolumnę.
-
Wybierz kolumny do usunięcia i kliknij przycisk Usuń.
Aby zobaczyć usunięte kolumny, kliknij przycisk Pokaż usunięte kolumny. Wskaźnikiem usuniętych kolumn jest przekreślony tekst. Usuniętą kolumnę można przywrócić, zaznaczając ją i klikając przycisk Odwróć.
Odwracanie jawnych zmian w kolumnach
Można odwrócić wszystkie jawne zmiany w co najmniej jednej kolumnie.
-
Wybierz kolumny do odwrócenia zmian i kliknij przycisk Odwróć.
Zmiany wynikające z globalnych reguł transformacji nie zostaną odwrócone.
Odwrócenie dodanej kolumny spowoduje jej usunięcie.
Ustawienia zestawu danych
Ustawienia zestawu danych można zmienić. Ustawienie domyślne jest dziedziczone z ustawienia zadania danych, ale można też zmienić ustawienie, aby było jawnie włączone lub wyłączone.
-
Kliknij ikonę
 obok zestawu danych, a następnie wybierz polecenie Ustawienia.
obok zestawu danych, a następnie wybierz polecenie Ustawienia.
Wyświetlanie kolumn nagłówkowych w widokach
Dla Qlik Open Lakehouse zadań umieszczania strumieniowego i transformacji, możesz kontrolować, czy wyświetlać, czy ukrywać kolumny nagłówka. Opcje różnią się w zależności od typu zadania.
Zadanie umieszczania strumieniowego
Aby wyświetlić kolumny nagłówka, włącz Pokaż kolumny nagłówka po prawej stronie pola wyszukiwania.
Zadanie transformacji strumieniowania
Lista rozwijana z następującymi opcjami jest dostępna po prawej stronie pola wyszukiwania.
-
Ukryj kolumny nagłówka: Domyślnie.
-
Pokaż kolumny nagłówka
-
Standard: Wybierz, aby wyświetlić kolumny nagłówkowe dla widoków standardowych.
-
Historia: Zaznacz, aby wyświetlić kolumny nagłówka dla widoków historii. Należy pamiętać, że ta opcja będzie dostępna tylko wtedy, gdy Utwórz magazyn danych historycznych (typ 2) jest włączona w ustawieniach zadania lub zestawu danych.
-
Opis dostępnych kolumn nagłówka zawiera Tabele związane z umieszczaniem i Widoki.
Wyświetlanie danych
Możesz wyświetlić próbkę danych, aby zobaczyć i zweryfikować stan danych podczas projektowania potoku danych.
Muszą zostać spełnione następujące wymagania:
-
Wyświetlanie danych jest włączone na poziomie dzierżawy w funkcji Administrowanie.
Aby to włączyć, przejdź do strony Ustawienia, wybierz kartę Kontrola funkcji i włącz Wyświetlanie danych w Integracja danych.
-
Przypisano Ci rolę Może wyświetlać dane w przestrzeni, w której znajduje się połączenie.
-
Przydzielono Ci rolę Może wyświetlać w przestrzeni, w której znajduje się ten projekt.
Przeglądanie danych przykładowych
Aby wyświetlić przykładowe dane na karcie Zestawy danych w widoku Projekt:
-
Kliknij Wyświetl dane.
Wyświetlona zostanie próbka danych. Ustawienie Liczba wierszy umożliwia określenie, ile wierszy danych należy uwzględnić w próbce.
Zrozumienie struktury danych
Podgląd danych wyświetla zarówno kolumny biznesowe, jak i kolumny generowane przez system. Podczas przeglądania danych ze strumieniowych zestawów danych, kolumny nagłówkowe (poprzedzone hdr__) dostarczają metadanych o źródło danych i transformacjach. Przykłady obejmują hdr__from_timestamp (kiedy dane zostały załadowane) oraz hdr__operation (typ zastosowanej operacji).
Kolumny nagłówkowe są tylko do odczytu i nie można ich modyfikować ani usuwać z podglądu. Aby kontrolować, które nagłówki są wyświetlane domyślnie, skonfiguruj nagłówki widoków standardowych na poziomie projektu lub zbioru danych.
Przełączanie między zestawami danych i tabelami
Aby przełączać zestawy danych i tabele:
-
Wybierz Zestawy danych, aby wyświetlić logiczną reprezentację danych.
-
Wybierz Obiekty fizyczne, aby wyświetlić fizyczną reprezentację w bazie danych w postaci tabel i widoków.
Uwaga dotycząca wiadomościTa opcja nie jest dostępna, jeśli reprezentacja fizyczna nie została jeszcze utworzona.
Filtrowanie
Dane przykładowe można filtrować na dwa sposoby:
-
Użyj
 do filtrowania pobieranych danych przykładowych.
do filtrowania pobieranych danych przykładowych.Jeżeli na przykład użyjesz filtru ${OrderYear}>2023 i Liczba wierszy będzie ustawiona na 10, otrzymasz próbkę 10 zamówień z 2024 roku.
-
Filtruj dane przykładowe według określonej kolumny.
Wpłynie to tylko na istniejące dane przykładowe. Jeżeli użyto
do uwzględnienia tylko zamówień z roku 2024, a filtr kolumny ustawiono tak, by wyświetlać zamówienia z 2022 roku, wynikiem będzie pusta próbka.
Sortowanie
Możesz także posortować próbkę danych według określonej kolumny. Sortowanie wpłynie tylko na istniejące dane przykładowe. Jeżeli użyto ![]() do uwzględniania tylko zamówień z 2024 roku i odwrócono kolejność sortowania, dane przykładowe będą nadal zawierać tylko zamówienia z 2024 roku.
do uwzględniania tylko zamówień z 2024 roku i odwrócono kolejność sortowania, dane przykładowe będą nadal zawierać tylko zamówienia z 2024 roku.
Ukrywanie kolumn
Możesz ukryć kolumny w widoku danych:
-
Ukryj pojedynczą kolumnę, klikając
na kolumnie, a następnie Ukryj kolumnę. -
Ukryj kilka kolumn, klikając
na dowolnej kolumnie, a następnie Wyświetl kolumny. W ten sposób możesz kontrolować widoczność wszystkich kolumn w widoku.
Pobieranie danych przykładowych
Możesz pobierać wyświetlone dane przykładowe:
-
Kliknij
 , aby pobrać zawartość widoku danych przykładowych.
, aby pobrać zawartość widoku danych przykładowych.
Dane przykładowe są pobierane jako plik CSV do pobranych plików przeglądarki.
Sprawdzanie poprawności i dostosowywanie zestawów danych
Można sprawdzić poprawność wszystkich zestawów danych uwzględnionych w zadaniu danych.
Aby zobaczyć wszystkie błędy wykryte podczas sprawdzania poprawności i zmiany w projekcie, rozwiń pozycję Sprawdź poprawność i dostosuj.
Sprawdzanie poprawności zestawów danych
-
Aby sprawdzić poprawność zestawów danych, kliknij przycisk Sprawdź poprawność zestawów danych.
Sprawdzenie poprawności obejmuje ustalenie, czy:
-
Wszystkie tabele mają klucz podstawowy,
-
Nie brakuje atrybutów,
-
Nie ma zduplikowanych nazw tabeli lub kolumn.
Zostanie też wyświetlona lista zmian w projekcie w porównaniu ze źródłem:
-
Dodane tabele i kolumny,
-
Usunięte tabele i kolumny,
-
Tabele i kolumny o zmienionych nazwach,
-
Zmienione klucze podstawowe i typy danych.
Aby zobaczyć wszystkie błędy wykryte podczas sprawdzania poprawności i zmiany w projekcie, rozwiń pozycję Sprawdź poprawność i dostosuj.
-
Popraw wykryte błędy, a następnie ponownie sprawdź poprawność zestawu danych.
-
Większość zmian w projekcie można dostosować automatycznie, poza zmienionymi kluczami podstawowymi i typami danych. W takim przypadku jest konieczna synchronizacja zestawów danych.
Przygotowanie zestawów danych
Możesz przygotować zestawy danych, aby dostosować zmiany w projekcie w miarę możliwości bez utraty danych. Jeśli istnieją zmiany w projekcie, których nie można dostosować bez utraty danych, uzyskasz opcję odtworzenia tabel ze źródła z utratą danych.
To wymaga zatrzymania zadania.
-
Kliknij
 , a następnie Przygotuj.
, a następnie Przygotuj.
Po przygotowaniu zestawów danych, ale przed ponownym uruchomieniem zadania pamięci masowej sprawdź poprawność zestawów danych.
Odtwarzanie zestawów danych
Zestawy danych możesz odtworzyć ze źródła. Podczas odtwarzania zestawu danych nastąpi utrata danych. Dopóki masz dane źródłowe, możesz załadować je ponownie ze źródła.
To wymaga zatrzymania zadania.
-
Kliknij
, a następnie Odtwórz tabele.
Pobieranie danych walidacyjnych
Możesz pobierać dane z Błędy walidacji, Zmiany projektu i Postęp przygotowań:
-
Kliknij
aby pobrać.
Dane są pobierane jako plik CSV do pobranych plików przeglądarki.
Ograniczenia
-
Usunięcie kolumny lub zmiana jej nazwy w przypadku platformy Google BigQuery powoduje odtworzenie tabeli i utratę danych.