
各メッセージの単語の重みを計算する
手順
-
tfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。

-
Tokenizerとラベル表示されたtModelEncoderに前述の操作を繰り返して、Vector型のsms_tf_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。
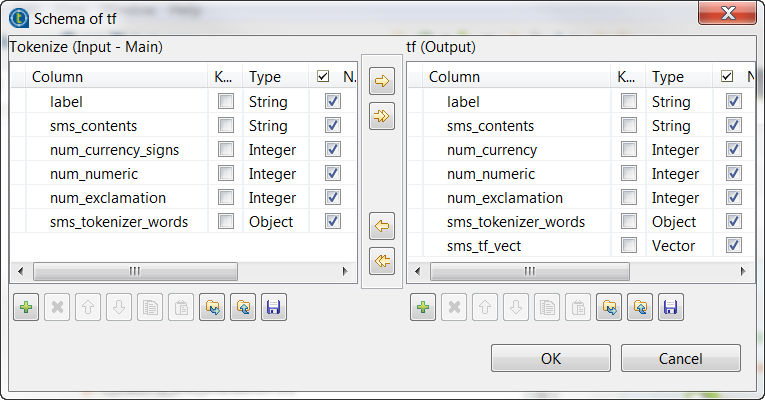 この変換では、tModelEncoderはHashingTFを使って、トークン化済みのSMSメッセージを固定長(このシナリオでは15)の特徴ベクトルに変換し、各SMSメッセージの単語の重要性を反映します。
この変換では、tModelEncoderはHashingTFを使って、トークン化済みのSMSメッセージを固定長(このシナリオでは15)の特徴ベクトルに変換し、各SMSメッセージの単語の重要性を反映します。