
特徴ベクトルを組み合わせる
手順
-
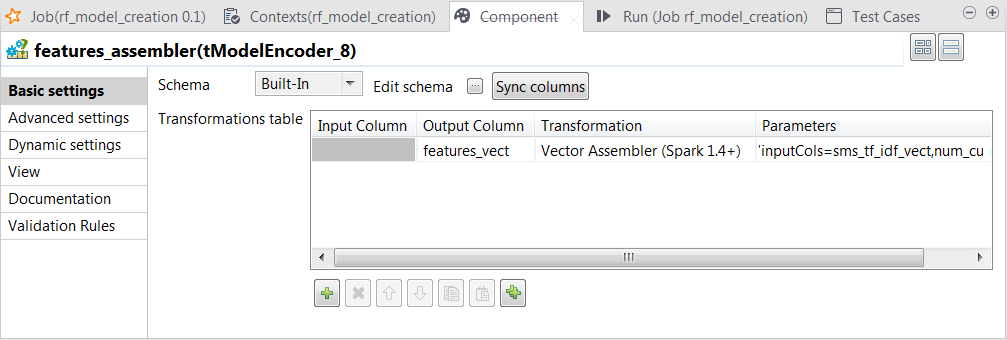
features_assemblerとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。
-
Tokenizerとラベル表示されたtModelEncoderに前述の操作を繰り返して、Vector型のfeatures_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。
[Parameters] (パラメーター)カラムに入力するパラメーターはinputCols=sms_tf_idf_vect,num_currency,num_numeric,num_exclamationです。
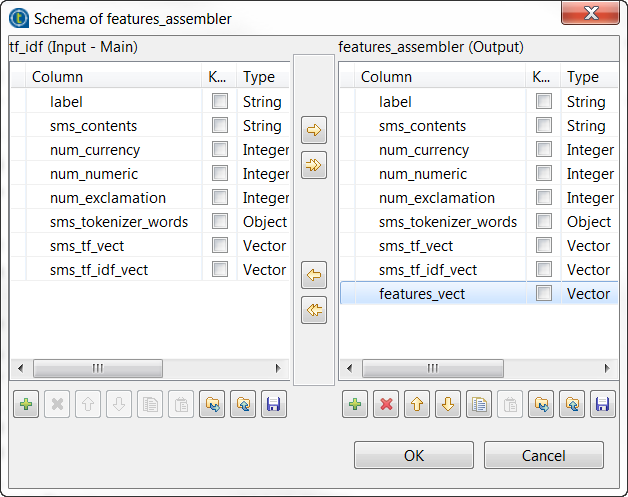 この変換では、tModelEncoderはすべての機能Vectorを1つの機能カラムに結合します。
この変換では、tModelEncoderはすべての機能Vectorを1つの機能カラムに結合します。