
顧客の数値データをHDFS上のクラスターにグルーピングする(非推奨)
このシナリオは、ビッグデータ関連Talend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントを参照してください。
このシナリオは、モデルベースのクラスタリングに関する研究論文から発想を得ています。そのデータは、Wholesale customers Data Set (英語のみ)にあります。研究論文は、Enhancing the selection of a model-based clustering with external categorical variables (英語のみ)から入手できます。このシナリオは、 Talend Studio にインポートできるData Quality Demosプロジェクトに含まれています。詳細は、 Talend Studioユーザーガイドを参照してください。
このシナリオのジョブは、特定のHadoop分散ファイルシステム(HDFS)に接続し、tMahoutClusteringのアルゴリズムを使って"卸売業者"の顧客を2つのクラスターにグルーピングし、特定のHDFSにデータを出力します。
データセットには、卸売業者のクライアントを参照する440個のサンプルがあります。これには、生鮮食品や食料品、牛乳などのさまざまな製品カテゴリーの通貨単位での年間支出が含まれます。
データセットは、さまざまなチャネルの顧客を参照しています: Horeca (ホテル/レストラン/カフェ)または小売(少量の商品販売)チャネル、および異なる地域から(リスボン/オポルト/その他)。 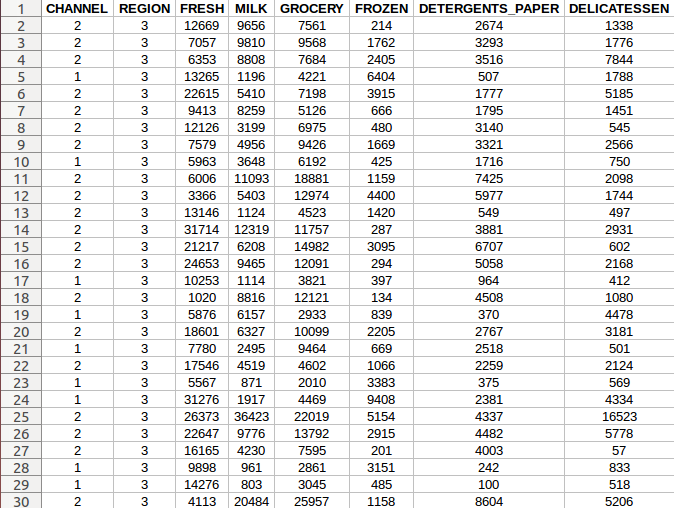
このジョブは以下を使います。
-
tMahoutClustering: 入力データセットのクラスターを計算します。
-
2つのtAggregateRowコンポーネント: カラムregionとchannelに基づいて、両方のクラスターのクライアント数をカウントします。
-
3つのtMapコンポーネント: チャネルと地域の入力フローを2つの別々の出力フローにマップします。これらのコンポーネントは、tMahoutClusteringから受け取った1つのclusterIDカラムを、地域とチャネルのクラスターに供給するカラム2つのデータフローにマップするためにも使われます。
-
2つのtHDFSOutputコンポーネント: 2つの出力ファイルでデータをHDFSに書き込みます。
前提条件: tMahoutClusteringコンポーネントを使うには、機能しているHadoopシステムが必要です。