
各メッセージ内の無関係な単語の重みを軽くする
手順
-
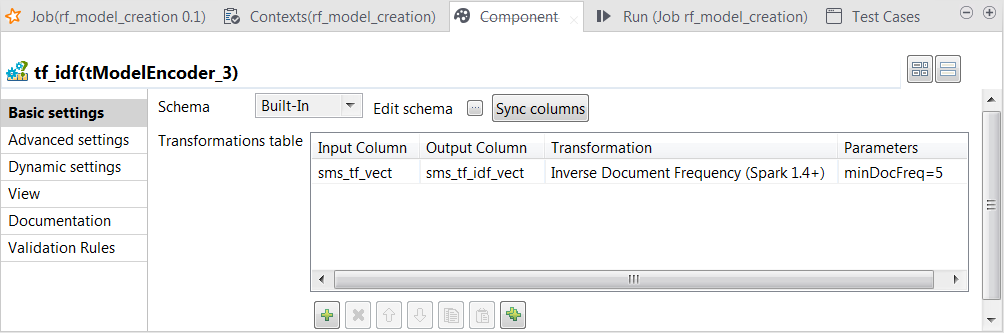
tf_idfとラベル表示されたtModelEncoderコンポーネントをダブルクリックして、[Component] (コンポーネント)ビューを開きます。この処理で、tModelEncoderは出現頻度が非常に高いものの、出現しているメッセージが多すぎる単語の重みを軽くします。この種の単語は、theのようにテキスト分析に有意な情報をもたらさない場合が多いためです。
-
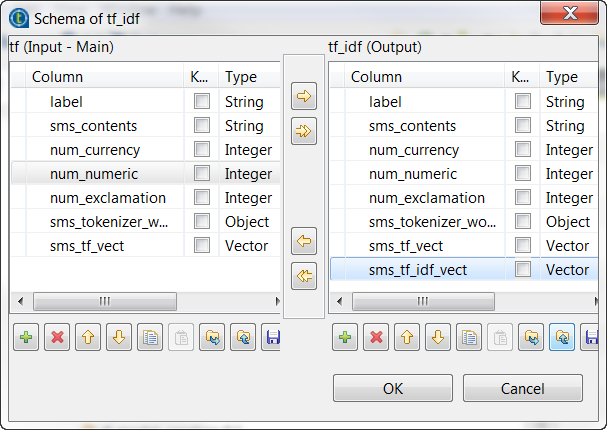
Tokenizerとラベル表示されたtModelEncoderに前述の操作を繰り返して、Vector型のsms_tf_idf_vectカラムを出力スキーマに追加し、上の画像に示すように変換を定義します。
 この変換では、tModelEncoderは[Inverse Document Frequency] (文献出現頻度の逆数)を使って、5つ以上のメッセージに出現する単語の重みを軽くします。
この変換では、tModelEncoderは[Inverse Document Frequency] (文献出現頻度の逆数)を使って、5つ以上のメッセージに出現する単語の重みを軽くします。