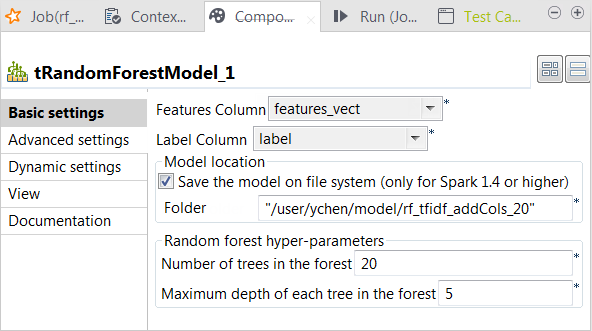
[Save the model on file system] (モデルをファイルシステムに保存)チェックボックスをオンにし、表示された[HDFS folder] (HDFSフォルダー)フィールドに、生成されたモデルの保管に使うディレクトリーを入力します。
[Number of trees in the forest] (フォレスト内のツリーの数)フィールドに、tRandomForestModelで構築するデシジョンツリーの数を入力します。現在のジョブを実行して分類モデルを作成するには、さまざまな数を数回試す必要があります。各実行で作成されたすべてのモデルの評価結果を比較した後、使う必要がある数を判断できます。このシナリオでは20入力します。