Ce scénario décrit un Job Spark Batch vous permettant de préparer, d'analyser et de transformer des données stockées dans des tables Delta Lake gérées utilisant Unity Catalog.
Dans ce scénario, vous utilisez des enregistrements relatifs au streaming de musique contenant les chansons les plus écoutées et les albums les plus écoutés, dans un jeu de données Delta Lake. Vous souhaitez analyser les chansons en fonction de leur popularité et de leur style, pour pouvoir les consommer de manière fluide dans une même table Databricks.
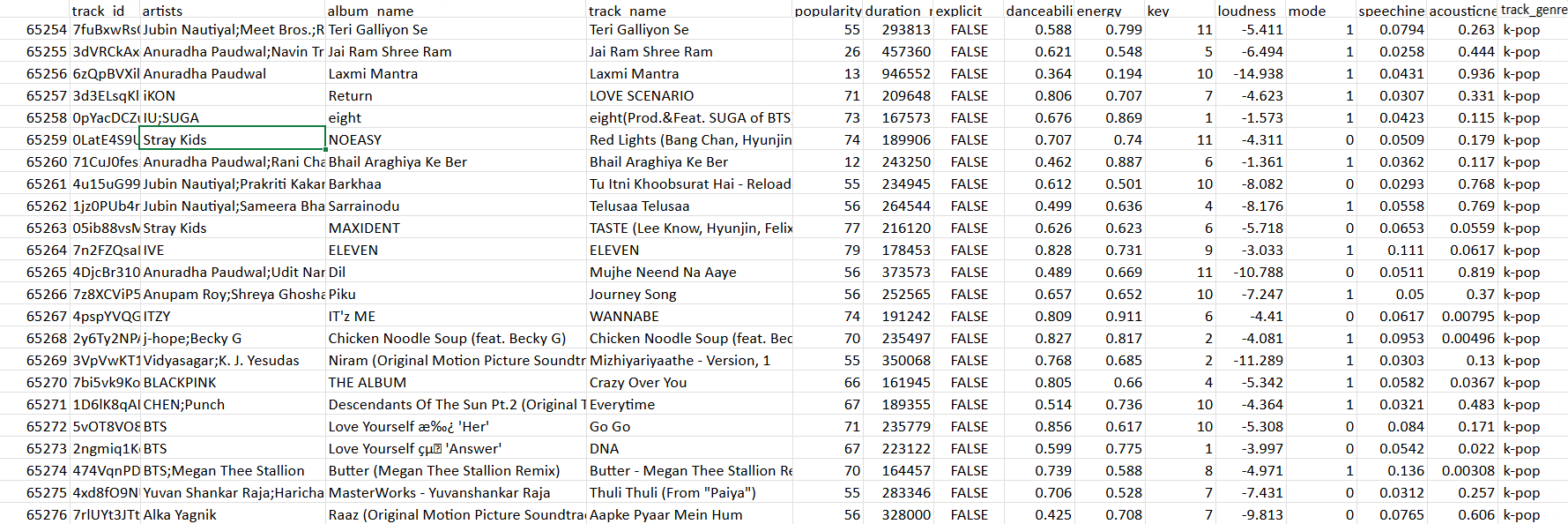
Voici un échantillon du jeu de données utilisé pour ce scénario :
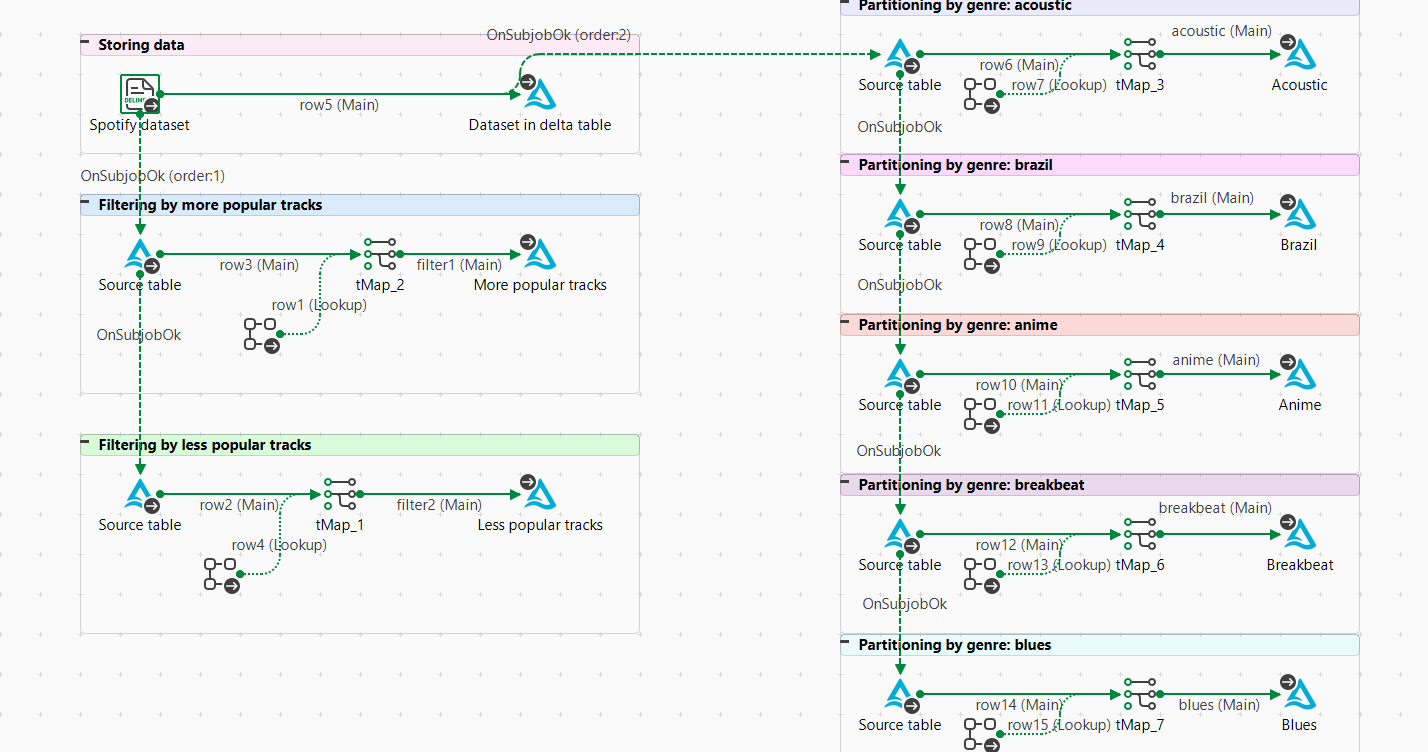
Pour ce scénario, vous devez créer un Job Spark Batch contenant plusieurs sous-Jobs. Chaque sous-Job est utilisé pour effectuer une action différente.
Procédure
Créez un Job Spark Batch et ajoutez les composants suivants :
sept tDeltaLakeInput,
huit tDeltaLakeOutput,
un tFileInputDelimited,
sept tFixedFlowInput,
sept tMap.
Créez le sous-Job Storing data :
Reliez le tFileInputDelimited au tDeltaLakeOuput.
Créez les sous-Jobs Filtering pour chaque action de filtre, par exemple more popular tracks :
Reliez le tDeltaLakeInput au tMap.
Reliez le tFixedFlowInput au tXMLMap.
Reliez le tMap au tDeltaLakeOutput.
Créez les sous-Jobs Partitioning by genre pour chaque style, par exemple anime :
Reliez le tDeltaLakeInput au tMap.
Reliez le tFixedFlowInput au tXMLMap.
Reliez le tMap au tDeltaLakeOutput.
Reliez les sous-Jobs Filtering au sous-Job Storing data.
Reliez les sous-Jobs Partitioning by genre au sous-Job Storing data.
Stocker des données dans Unity Catalog
La première étape de ce scénario consiste à charger le fichier CSV contenant les enregistrements relatifs au streaming de musique dans le Studio Talend, puis à stocker le jeu de données dans une table Delta Lake.
Pourquoi et quand exécuter cette tâche
Pour cette tâche, utilisez le sous-Job Storing data.
Procédure
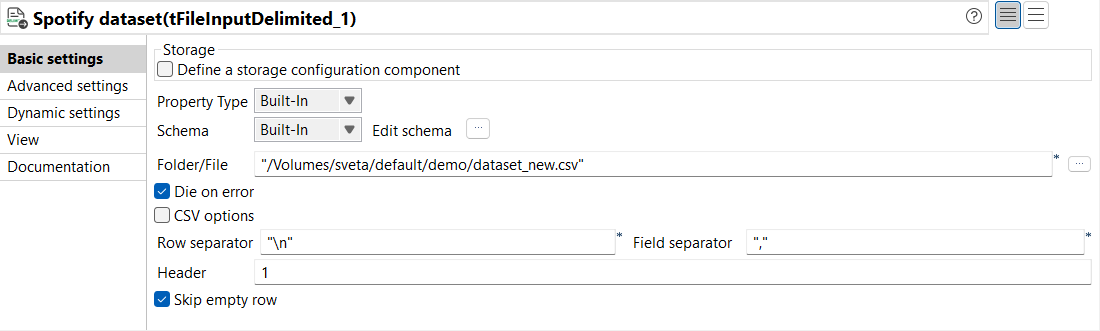
Dans la vue Basic settings du tFileInputDelimited, configurez les paramètres comme suit :
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans le champ Folder/File, saisissez le chemin d'accès aux données à utiliser. Dans cet exemple, utilisez un fichier CSV.
Laissez les autres paramètres tels qu'ils sont.
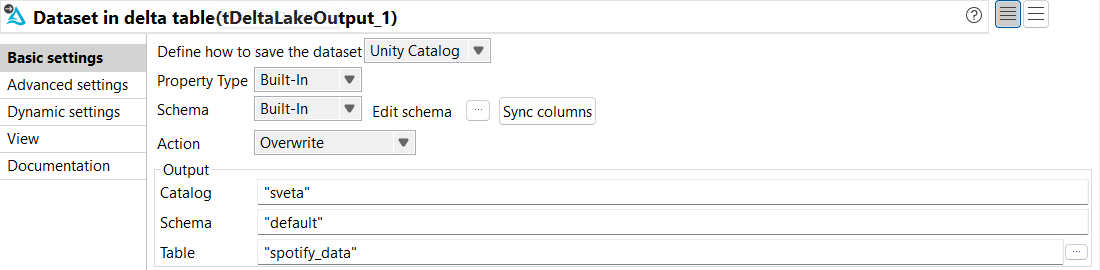
Dans la vue Basic settings du tDeltaLakeOutput, configurez les paramètres comme suit :
Dans la liste déroulante Define how to save the dataset, sélectionnez Unity Catalog.
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans la liste Action, sélectionnez Overwrite.
Dans le champ Catalog, saisissez le nom du catalogue dans lequel stocker les données.
Dans le champ Schema, saisissez le nom du schéma dans lequel stocker les données.
Dans le champ Table, saisissez le nom de la table dans laquelle stocker les données. Dans cet exemple, son nom est spotify_data.
Résultats
Le sous-Job Storing data est prêt à être utilisé. Une fois que le sous-Job est démarré, la table Delta Lake spotify_data est créée.
Filtrer les chansons par popularité
La deuxième étape de ce scénario consiste à filtrer les chansons du jeu de données Delta Lake en fonction de leur popularité. Le premier filtre s'applique aux pistes les plus populaires et le second aux moins populaires.
Pourquoi et quand exécuter cette tâche
Pour cette tâche, utilisez le sous-Job Filtering by more popular tracks. Vous pouvez effectuer les mêmes actions pour le sous-Job Filtering by less popular tracks.
Procédure
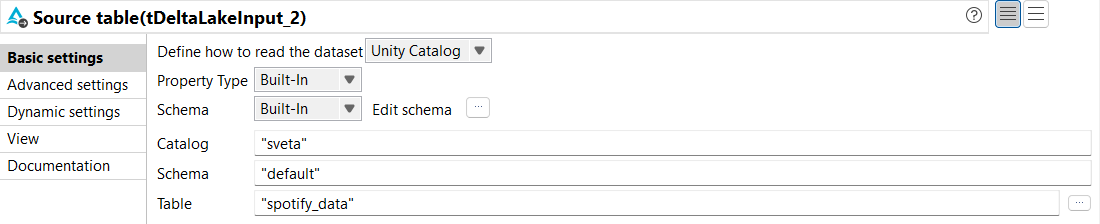
Dans la vue Basic settings du tDeltaLakeInput, configurez les paramètres comme suit :
Dans la liste déroulante Define how to read the dataset, sélectionnez Unity Catalog.
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans la liste Action, sélectionnez Overwrite.
Dans le champ Catalog, saisissez le nom du catalogue dans lequel stocker les données.
Dans le champ Schema, saisissez le nom du schéma dans lequel stocker les données.
Dans le champ Table, saisissez le nom de la table de laquelle lire les données. Dans cet exemple, son nom est spotify_data.
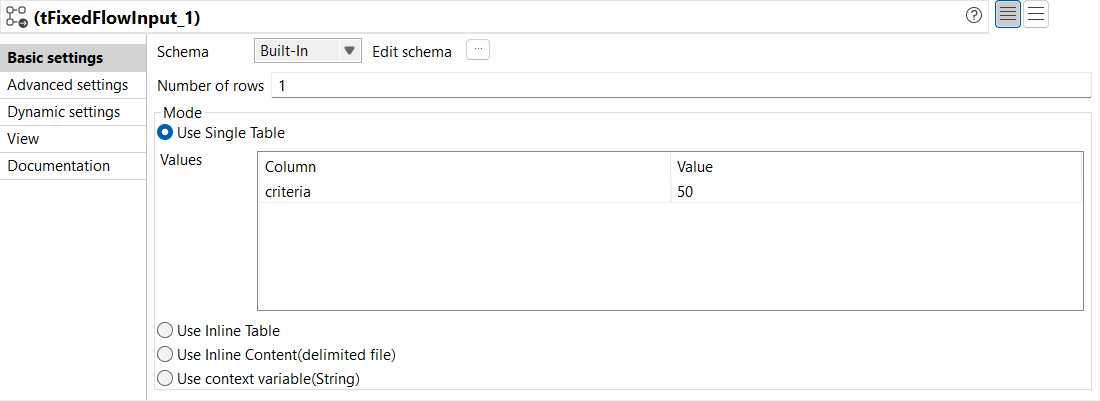
Dans la vue Basic settings du tFixedFlowInput, configurez les paramètres comme suit :
Dans la liste déroulante Schema, sélectionnez Built-In.
Dans le champ Number of rows, saisissez le nombre de lignes à générer. Dans cet exemple, saisissez 1.
Sélectionnez le mode Use Single Table et saisissez les données que vous souhaitez générer dans le champ correspondant. Dans cet exemple, il s'agit d'une colonne nommée criteria, ayant une valeur de 50.
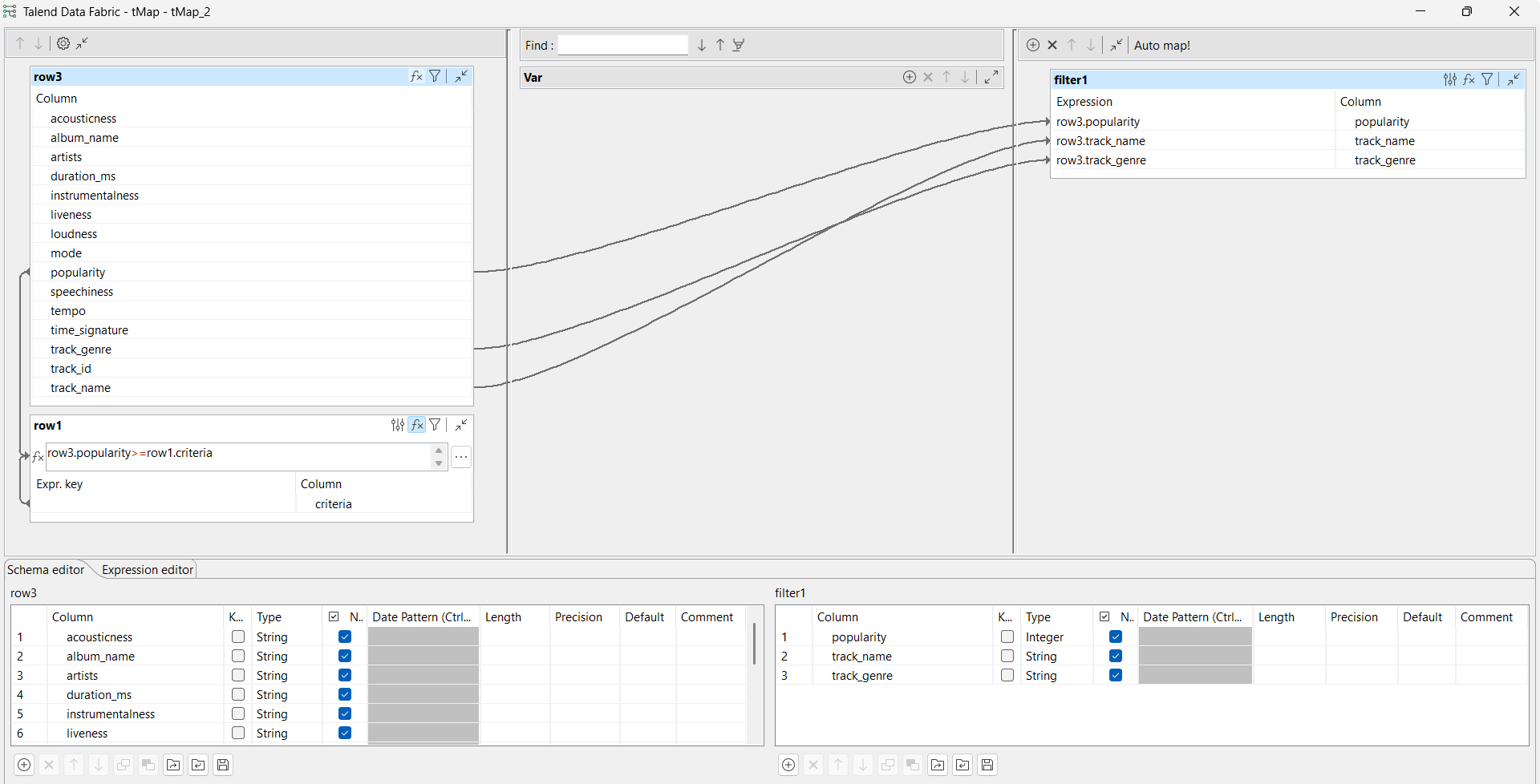
Dans la vue Basic settings du tMap, configurez le mapping comme suit :
Double-cliquez sur le composant tMap pour accéder au Map Editor.
Créez une expression pour la ligne popularity. Dans cet exemple, l'expression est row3.popularity>=row1.criteria, où criteria est configuré à 50 dans le composant tFixedFlowInput, ce qui signifie que l'expression filtre uniquement les chansons ayant une popularité supérieure ou égale à 50.
Créez une jointure entre le flux d'entrée principal et le nouveau flux d'entrée pour les lignes popularity, track_name et track_genre.
Cliquez sur OK pour valider les paramètres de mapping et fermer le Map Editor.
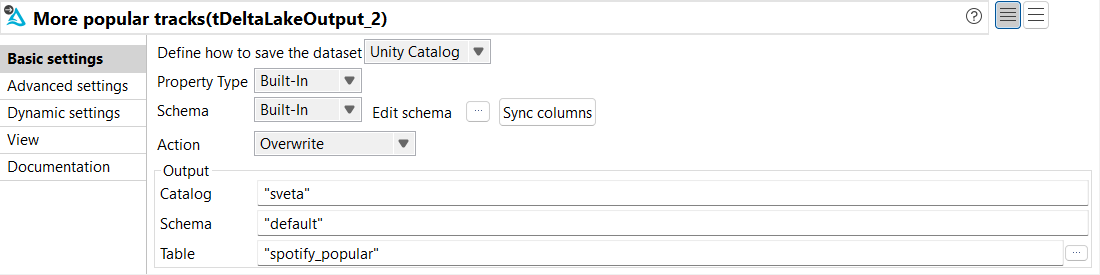
Dans la vue Basic settings du tDeltaLakeOutput, configurez les paramètres comme suit :
Dans la liste déroulante Define how to save the dataset, sélectionnez Unity Catalog.
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans la liste Action, sélectionnez Overwrite.
Dans le champ Catalog, saisissez le nom du catalogue dans lequel stocker les données.
Dans le champ Schema, saisissez le nom du schéma dans lequel stocker les données.
Dans le champ Table, saisissez le nom de la table dans laquelle stocker les données. Dans cet exemple, son nom est spotify_popular.
Résultats
Le sous-Job Filtering by more popular tracks est prêt à être utilisé. Une fois que le sous-Job est démarré, la table Delta Lake spotify_popular est créée.
Partitionner les chansons en fonction de leur style
La troisième étape de scénario consiste à partitionner les chansons en cinq styles : acoustic, brazilian, anime, breakbeat et blues dans cet exemple. Chaque style représente une nouvelle table.
Pourquoi et quand exécuter cette tâche
Pour cette tâche, utilisez le sous-Job Partitioning by genre: anime. Effectuez les mêmes actions pour les sous-Jobs suivants :
Partitioning by genre: acoustic
Partitioning by genre: brazil
Partitioning by genre: breakbeat
Partitioning by genre: blues
Procédure
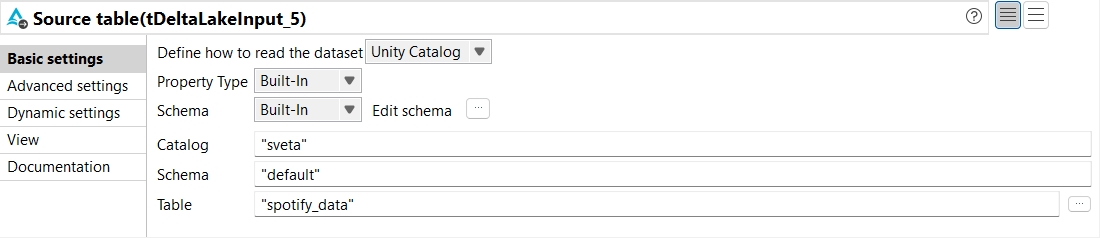
Dans la vue Basic settings du tDeltaLakeInput, configurez les paramètres comme suit :
Dans la liste déroulante Define how to read the dataset, sélectionnez Unity Catalog.
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans la liste Action, sélectionnez Overwrite.
Dans le champ Catalog, saisissez le nom du catalogue dans lequel stocker les données.
Dans le champ Schema, saisissez le nom du schéma dans lequel stocker les données.
Dans le champ Table, saisissez le nom de la table de laquelle lire les données. Dans cet exemple, son nom est spotify_data.
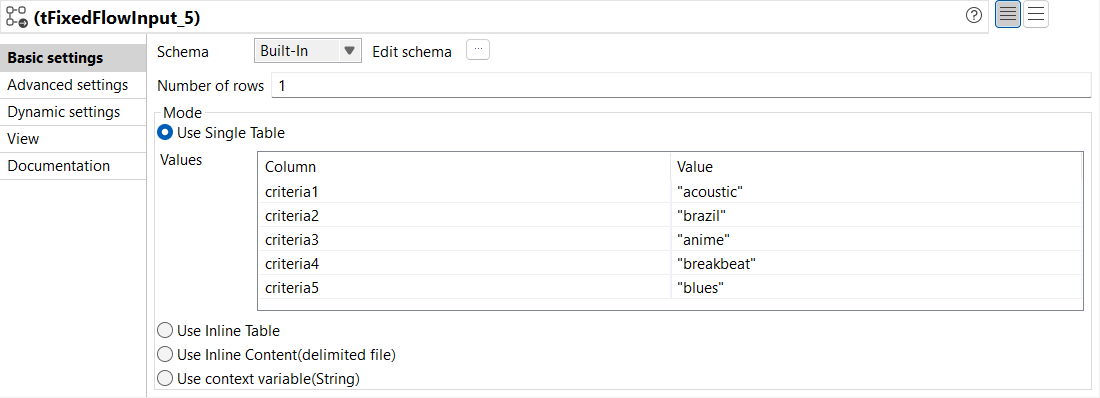
Dans la vue Basic settings du tFixedFlowInput, configurez les paramètres comme suit :
Dans la liste déroulante Schema, sélectionnez Built-In.
Dans le champ Number of rows, saisissez le nombre de lignes à générer. Dans cet exemple, saisissez 1.
Sélectionnez le mode Use Single Table et saisissez les données que vous souhaitez générer dans le champ correspondant. Dans cet exemple, il s'agit d'une colonne nommée criteria3, ayant la valeur anime.
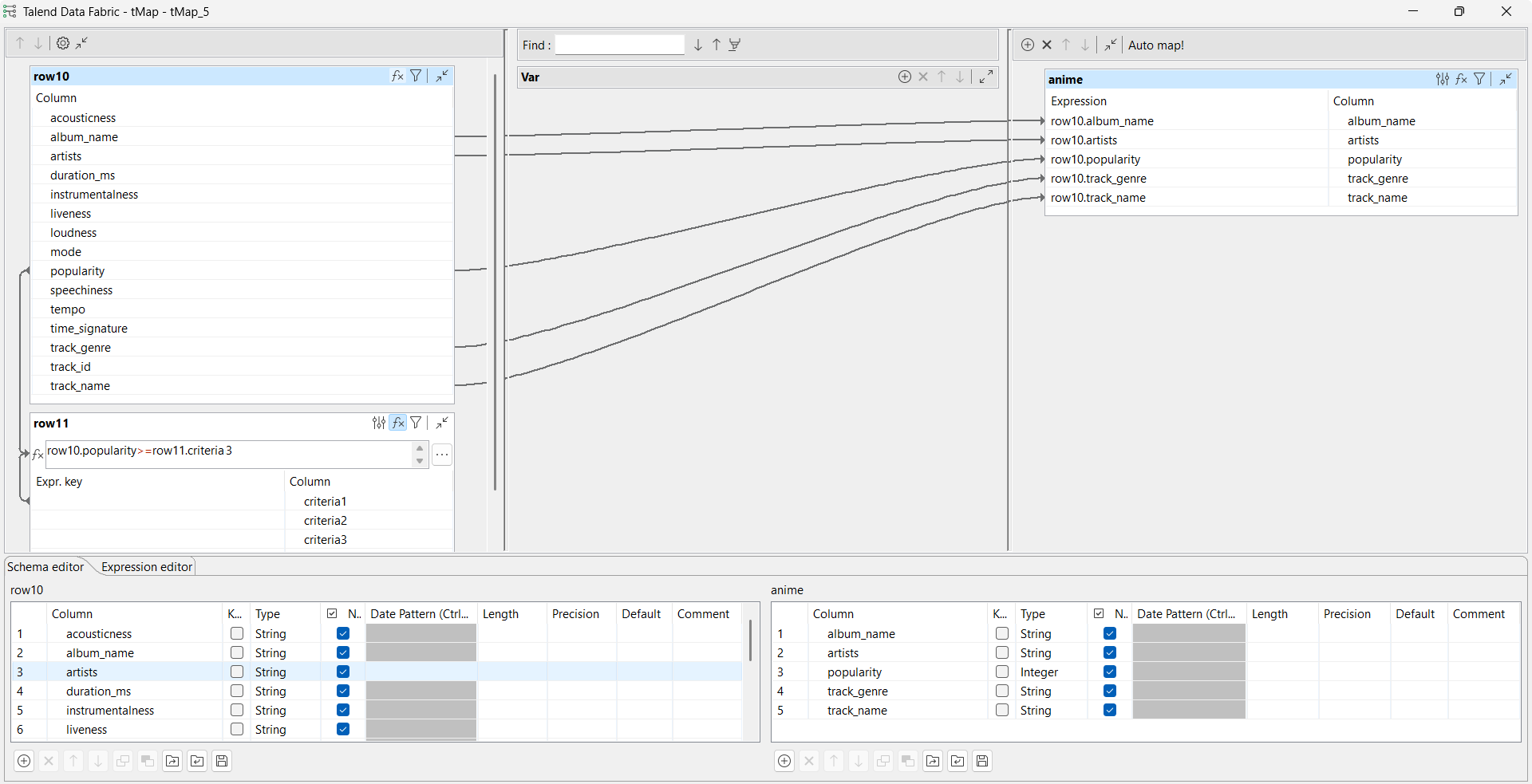
Dans la vue Basic settings du tMap, configurez le mapping comme suit :
Double-cliquez sur le composant tMap pour accéder au Map Editor.
Créez une expression pour la ligne popularity. Dans cet exemple, l'expression est row10.popularity>=row11.criteria3, où criteria3 est configuré à anime dans le composant tFixedFlowInput, ce qui signifie que l'expression filtre uniquement les chansons du genre anime.
Créez une jointure entre le flux d'entrée principal et le nouveau flux d'entrée pour les lignes album_name, artists, popularity, track_genre et track_name.
Cliquez sur OK pour valider les paramètres de mapping et fermer le Map Editor.
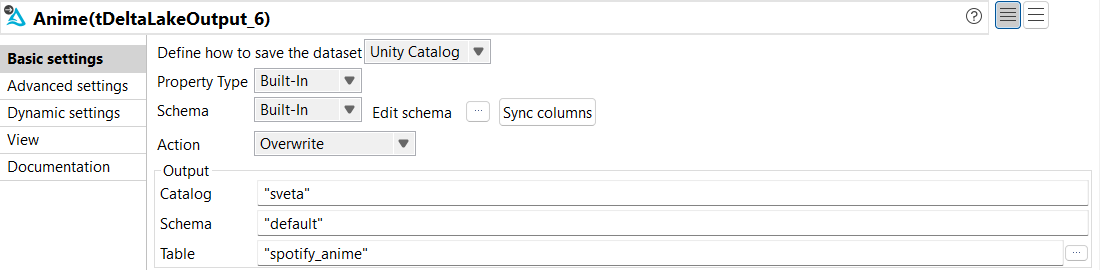
Dans la vue Basic settings du tDeltaLakeOutput, configurez les paramètres comme suit :
Dans la liste déroulante Define how to save the dataset, sélectionnez Unity Catalog.
Dans les listes déroulantes Property Type et Schema, sélectionnez Built-In.
Dans la liste Action, sélectionnez Overwrite.
Dans le champ Catalog, saisissez le nom du catalogue dans lequel stocker les données.
Dans le champ Schema, saisissez le nom du schéma dans lequel stocker les données.
Dans le champ Table, saisissez le nom de la table dans laquelle stocker les données. Dans cet exemple, son nom est spotify_anime.
Résultats
Le sous-Job Partitioning by genre: anime est prêt à être utilisé. Une fois que le sous-Job est démarré, la table Delta Lake spotify_anime est créée.
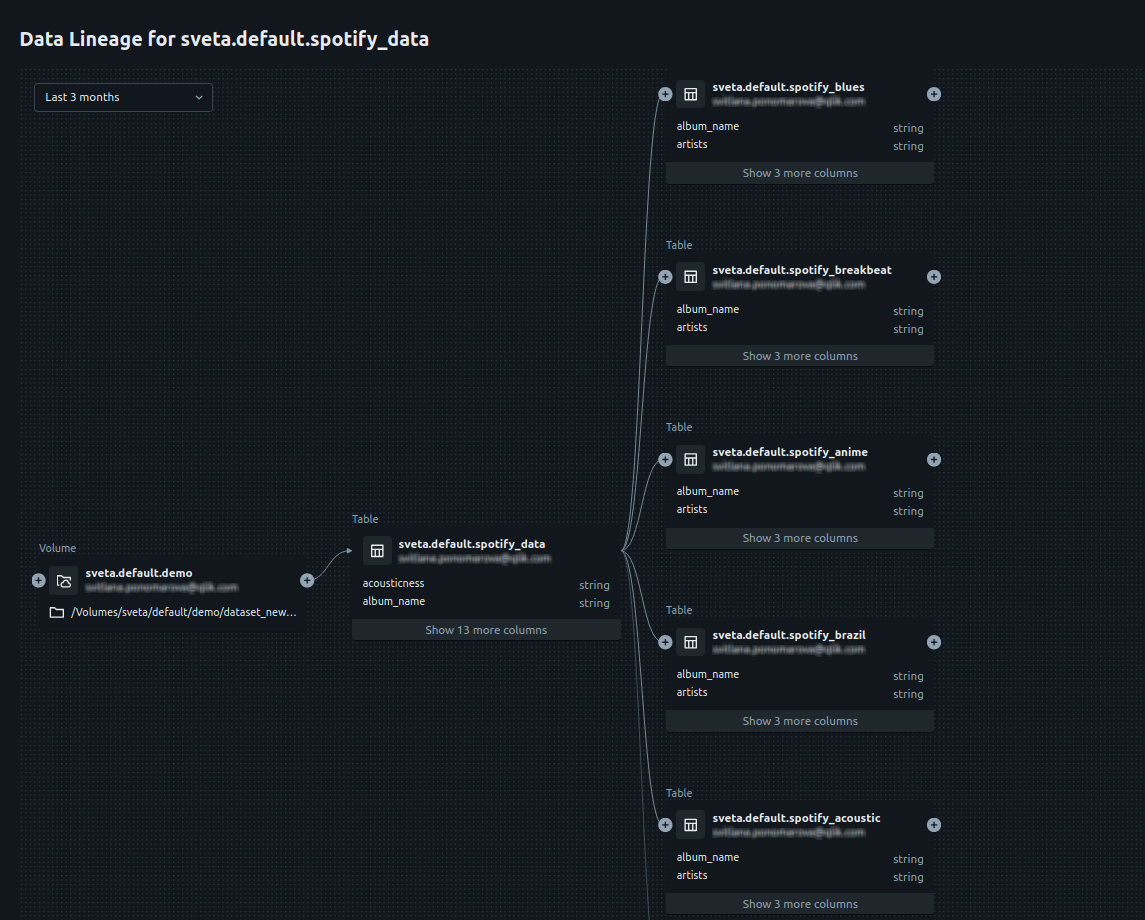
Analyser le lignage de données
La dernière étape de ce scénario consiste à analyser les données finales avec l'outil de lignage de données d'Unity Catalog.
Procédure
Exécutez le Job Spark Batch.
Les nouvelles tables sont créées en fonction de la popularité et du style des chansons.
Côté Databricks, sélectionnez la table spotify_data et ouvrez l'onglet Lineage. Pour plus d'informations, consultez Capture and view data lineage using Unity Catalog (en anglais) dans la documentation Databricks officielle.
Le graphique du lignage s'affiche. Vous pouvez analyser le graphique pour voir comment ont été créées les tables, en se basant sur le volume initial d'Unity Catalog provenant du fichier CSV.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.