
Indexer des évaluations de téléphones avec une base de données et des intégrations vectorielles
Ce Job lit des fichiers texte d'évaluations de téléphones depuis un dossier, scinde le contenu en morceaux plus petits pour une meilleure analyse, génère des intégrations vectorielles à l'aide d'Azure OpenAI et les stocke dans une base de données Pinecone vectorielle, pour implémenter la recherche sémantique.
Avant de commencer
Avant d'exécuter ce Job, assurez-vous d'avoir les éléments suivants :
- Un compte Azure OpenAI actif avec accès au modèle text-embedding-3-small.
- Votre clé API et votre endpoint (point de terminaison) Azure OpenAI sont configuré·es.
- Un compte Pinecone avec un index créé pour stocker les intégrations.
- Votre clé API et votre endpoint d'hôte Pinecone sont configuré·es.
- Vous avez téléchargé le fichier archive tembeddingai-tpineconeclient_phone-review-files.zip et extrait les fichiers LG.txt et Iphones.txt.
- Vous avez créé le répertoire <folder_path>/phone-reviews/ avec les fichiers de texte d'évaluation des téléphones.
Relier les composants
Procédure
-
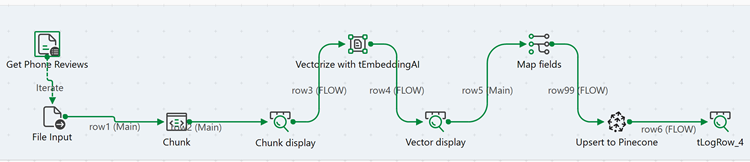
Reliez le tPineconeClient au dernier tLogRow à l'aide d'un lien Row > FLOW.
Configurer les composants
Pourquoi et quand exécuter cette tâche
Procédure
-
Dans l'onglet Basic settings, configurez les paramètres suivants :
- Cliquez sur Edit schema et vérifiez que le schéma comporte la colonne suivante : embedding (List).
- Dans la liste Platform, sélectionnez Azure OpenAI.
- Dans le champ Model name, cliquez sur le bouton [...] et sélectionnez text-embedding-3-small.
- Dans le champ Token/API Key, cliquez sur le bouton [...] et saisissez votre clé API Azure OpenAI, puis cliquez sur OK.
- Dans le champ Azure endpoint, saisissez votre endpoint (point de terminaison) Azure OpenAI (par exemple : https://your-resource-name.openai.azure.com/).
- Dans la liste Column for embedding, sélectionnez chunk.
Ce composant génère des intégrations vectorielles pour chaque morceau de texte d'évaluation de téléphones.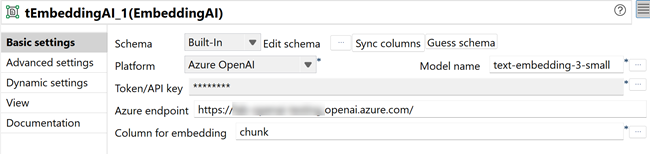
-
Dans le Map Editor, créez le schéma de sortie avec les colonnes suivantes :
- id (String)
- vector (List) - Mappez-la à la colonne d'entrée embedding
- text (String)
Ce mapping vérifie que toutes les métadonnées sont bien transférées au composant tPineconeClient. Les colonnes id et values sont requises par Pinecone pour les opérations d'upsert.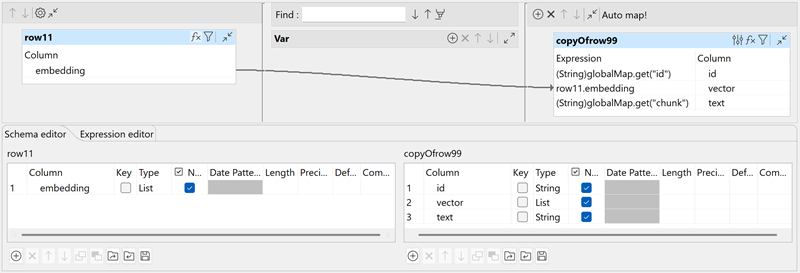
-
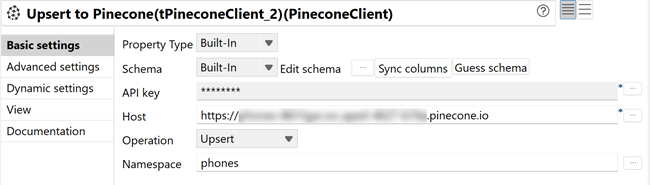
Dans l'onglet Basic settings, configurez les paramètres suivants :
- Cliquez sur Edit schema et vérifiez que le schéma comporte la colonne suivante : upsertedCount (Int).
- Dans le champ API Key, cliquez sur le bouton [...] et saisissez votre clé API Pinecone, puis cliquez sur OK.
- Dans le champ Host, saisissez l'hôte de votre index Pinecone (par exemple : "your-index-name.svc.environment.pinecone.io").
- Dans la liste Operation, sélectionnez Upsert pour charger les données d'évaluation vectorisées dans l'index Pinecone.
- Dans le champ Namespace, saisissez le nom de l'espace de noms (par exemple : phones") ou laissez le champ vide pour utiliser l'espace de noms par défaut.
Exécuter le Job
Procédure
- Appuyez sur les touches Ctrl+S pour enregistrer le Job.
- Appuyez sur F6 pour exécuter le Job.
Résultats
Le Job lit les fichiers d'évaluation, scinde le texte en morceaux, génère des intégrations à l'aide d'Azure OpenAI, vérifie le transfert des métadonnées via le tMap et effectue un upsert sur les données vectorisées dans Pinecone pour la recherche sémantique.
Les intégrations d'évaluations de téléphones stockées dans Pinecone activent les requêtes de recherches sémantiques, permettant aux utilisateur·trices de trouver les évaluations pertinentes en se basant sur le contexte plutôt que sur des correspondances exactes de mots-clés. La scission du texte en morceaux assure des résultats de recherche plus précis et de meilleures fonctionnalités d'analyse.