
Réduire le poids des mots sans importance dans chaque message
Procédure
-
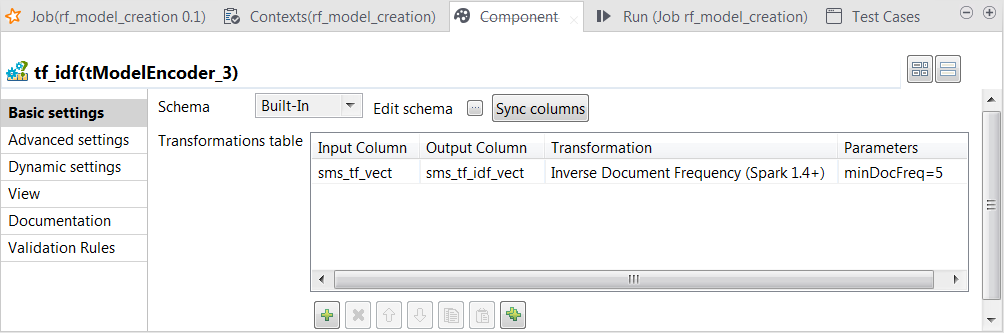
Double-cliquez sur le composant tModelEncoder nommé tf_idf pour ouvrir sa vue Component. Dans ce processus, le tModelEncoder réduit le poids des mots apparaissant très souvent mais dans de trop nombreux messages, car un mot de ce genre n'apporte généralement pas d'information utile lors d'une analyse de texte, comme le mot anglais the.
-
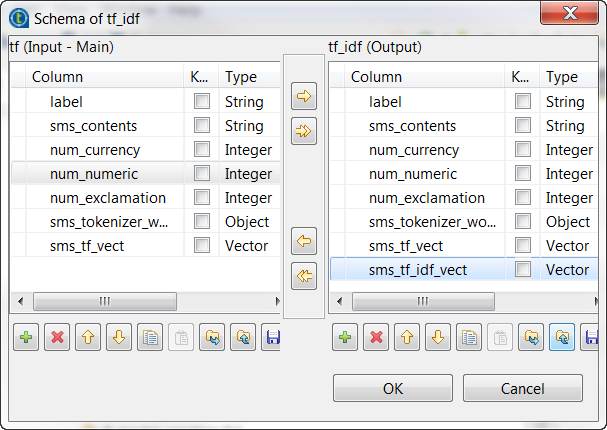
Répétez les opérations précédemment décrites durant la configuration du tModelEncoder nommé Tokenizer pour ajouter la colonne sms_tf_idf_vect de type Vector au schéma de sortie et définir la transformation comme affiché dans l'image ci-dessus.
 Dans cette transformation, le tModelEncoder utilise Inverse Document Frequency pour réduire le poids des mots apparaissant dans cinq messages ou plus.
Dans cette transformation, le tModelEncoder utilise Inverse Document Frequency pour réduire le poids des mots apparaissant dans cinq messages ou plus.