
Finaliser et exécuter l'analyse d'un ensemble de colonnes
Avant de commencer
Procédure
-
Cliquez sur Save and run.
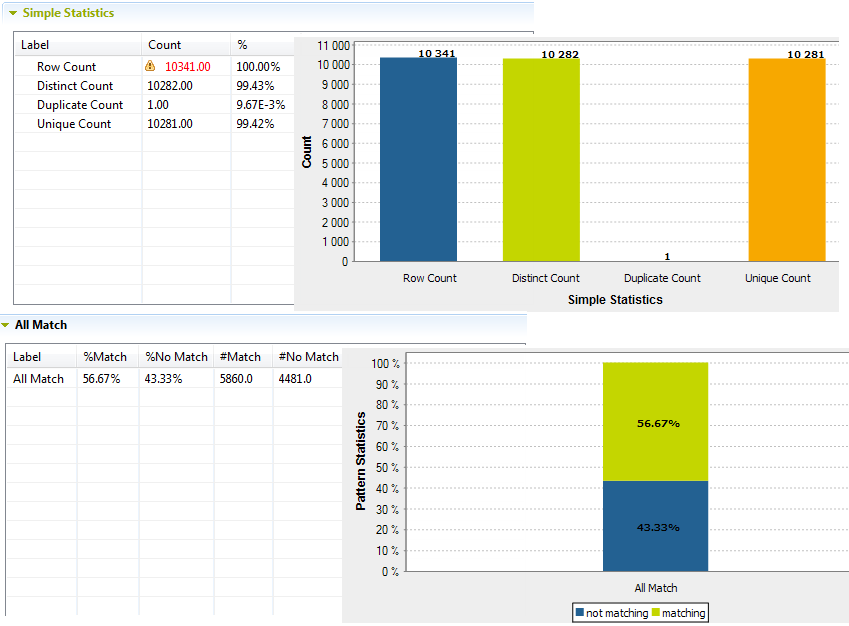
L'éditeur d'analyse passe à la vue des résultats d'analyse dans laquelle vous pouvez lire les résultats d'analyse dans des tables et des diagrammes. Les résultats graphiques fournissent les statistiques simples sur les enregistrements complets de l'ensemble de colonnes analysées et non sur les valeurs au sein de chaque colonne séparément.
Que faire ensuite
Note InformationsRestriction : La table All Match est disponible uniquement lorsque vous exécutez l'analyse avec le moteur Java.