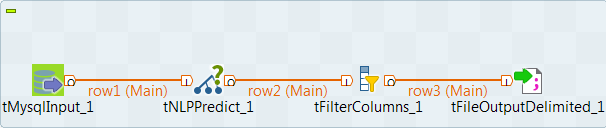
ジョブを作成し、ネームドエンティティをテキストデータから抽出する
このジョブでは、tNLPPredictがネームドエンティティを予測し、分類モデルを使用して、トークンに分割されたテキストデータに自動的にラベル付けします。
手順
- tMySQLInput、tReplace、tNLPPredict、tFilterColumnsを、[Palette] (パレット)からデザインワークスペースにドロップします。
- 接続を使用してコンポーネントを接続します。
タスクの結果