
ネームドエンティティをテキストデータから抽出する
このジョブでは、tNLPPredictコンポーネントは、tNLPModelコンポーネントによって生成された分類モデルを使用して、ネームドエンティティを予測し、自動的にラベル付けします。
手順
-
tNLPPredictコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
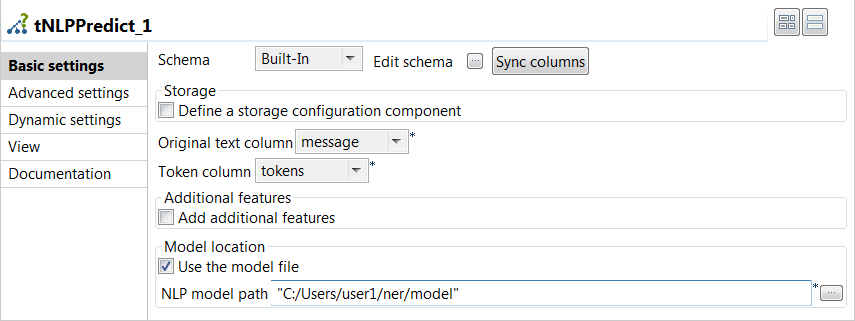
- [Sync columns] (カラムを同期)をクリックすると、ジョブで接続している先行コンポーネントからスキーマが取得されます。
- ラベル付けするテキストが含まれたカラムを[Original text column] (元のテキストカラム)リストから選択します(このサンプルではtext)。
- 機能の構築と予測に使用するカラムを[Token column] (トークンカラム)リストから選択します(このサンプルではtokens)。
- [NLP Library] (NLPライブラリー)リストから、モデルの生成に使用したのと同じライブラリーを選択します。
- ネームドエンティティ認識モデルが1つのファイルに保存されている場合は、[Use the model file] (モデルファイルの使用)チェックボックスをオンにします。
- モデルへのパスを[NLP model path] (NLPモデルパス)に指定します。
-
tFilterColumnsコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
-
スキーマをBuilt-inに設定し、[Edit schema] (スキーマを編集)をクリックして、元のテキスト、ラベル付けされたテキスト、およびラベルが保存されたカラムのみを保持します。
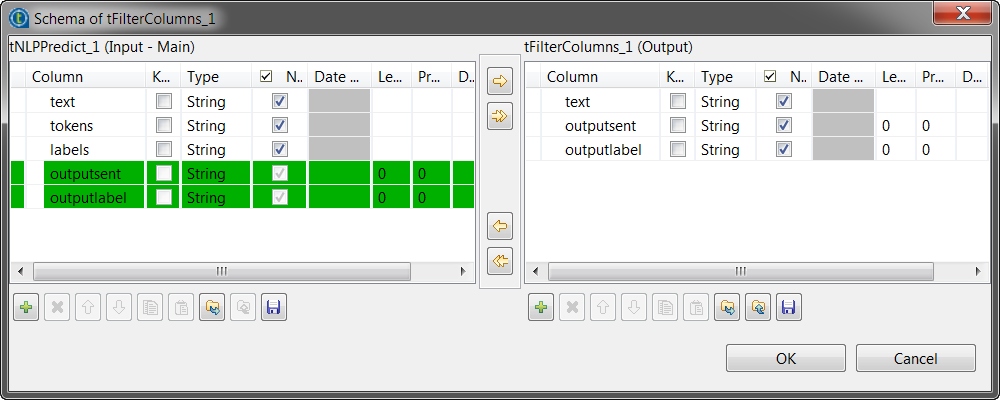
-
スキーマをBuilt-inに設定し、[Edit schema] (スキーマを編集)をクリックして、元のテキスト、ラベル付けされたテキスト、およびラベルが保存されたカラムのみを保持します。
-
tFileOutputDelimitedコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
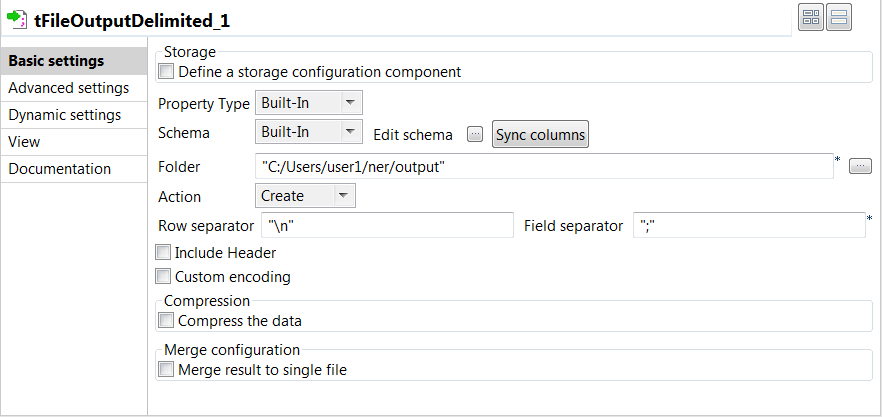
- [Sync columns] (カラムを同期)をクリックすると、ジョブで接続している先行コンポーネントからスキーマが取得されます。
- ラベル付けされたテキストとラベルを保存するフォルダーへのパスを[Folder] (フォルダー)フィールドで指定します。
- [Row separator] (行区切り)フィールドに"\n"を、[Field separator] (フィールド区切り)フィールドに";"を入力します。
タスクの結果
出力ファイルには、元のテキスト、ラベル付けされたテキスト、およびラベルが含まれています。ネームドエンティティ認識タスクは正しく実行されました。人名が元のテキストから抽出されたからです。
