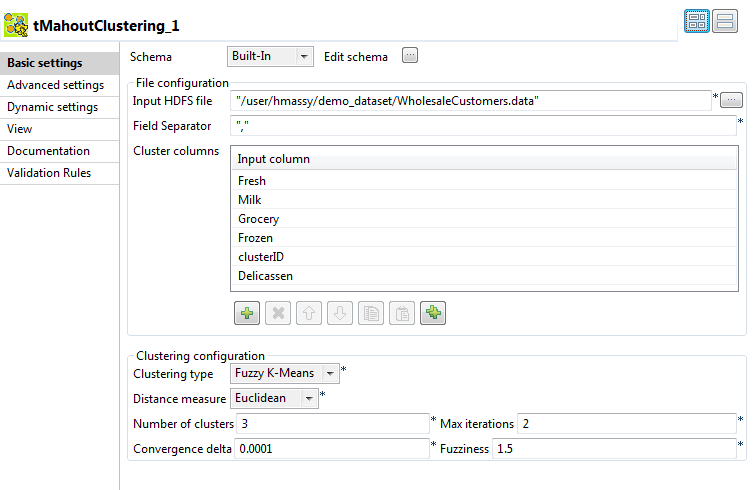
[Input HDFS file] (入力HDFSファイル)の横にある[...]ボタンをクリックし、クラスター化する入力数値データを保持するHadoopシステム上のHDFSファイルを参照します。
クラスター化データのカラムを区切るために使うフィールド区切りを設定します。
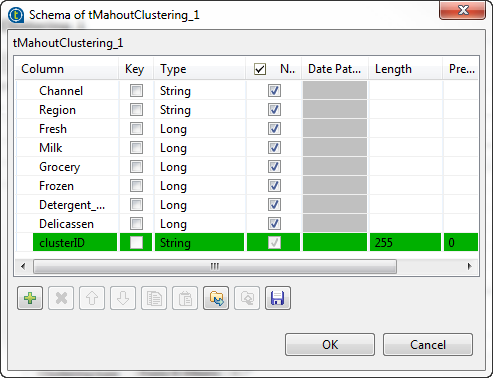
[Cluster columns] (クラスターカラム)テーブルで、テーブルに行を追加し、各行をクリックして、入力スキーマからカラムを選択します。
[Clustering Type] (クラスタリングタイプ)リストから、数値データをクラスタリングするために使うアルゴリズム(この例では[Fuzzy K-means] (ファジーK-Means))を選択します。
[Distance Measure] (距離測定)リストから、クラスタリングに使うする距離測定を選択します。
[Number of clusters] (クラスター数)フィールドに3と入力します。
[Max iterations] (最大反復)と[Convergence delta] (収束デルタ)の値はそのままにしておきます。
このページまたはコンテンツにタイポ、ステップの省略、技術的エラーなどの問題が見つかった場合はお知らせください。