メイン コンテンツをスキップする
補完的コンテンツへスキップ
Qlik.com
Community
Learning
Qlik リソース
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
閉じる
ドキュメント
クラウド
Client-Managed
追加のドキュメント
クラウド
Qlik Cloud
ホーム
紹介
Qlik Cloud の新機能
Qlik Talend Cloud について
分析
データ統合
管理
自動化
Qlik 開発者
Talend Cloud
ホーム
リリース ノート
API Portal
他のクラウド ソリューション
Stitch
Upsolver
Client-Managed
クライアント管理 — 分析
ユーザー向けの Qlik Sense
管理者向け
Qlik Sense
開発者向け
Qlik Sense
Qlik NPrinting
Connectors
Qlik GeoAnalytics
Qlik Alerting
ユーザーと管理者向けの
QlikView
開発者向け
QlikView
Governance Dashboard
クライアント管理 — データ統合
Qlik Replicate
Qlik Compose
Qlik Enterprise Manager
Qlik Gold Client
Qlik Catalog
NodeGraph (legacy)
Qlik Talend
Talend Studio
Talend ESB
Talend Administration Center
Talend Data Catalog
Talend Data Preparation
Talend Data Stewardship
追加のドキュメント
追加のドキュメント
Qlik ドキュメンテーション アーカイブ
Talend ドキュメンテーション アーカイブ
オンボーディング
分析を開始
データ統合を開始する
分析ユーザーのオンボーディング
Qlik Sense で分析を開始
Qlik Cloud Analytics Standard の管理
Qlik Cloud Analytics Premium および Enterprise の管理
Qlik Sense
Business
の管理
Qlik Sense
Enterprise SaaS
の管理
Qlik Cloud Government を管理
Windows 上の
Qlik Sense
Enterprise
の管理
オンボーディング データ統合ユーザー
Qlik Talend Data Integration Cloud を開始する
Talend Cloud を開始する
ビデオ
移行センター
評価ガイド
プレイブック
管理者プレイブック
Qlik Sense 管理者プレイブック
Qlik リソース
日本語 (変更)
Deutsch
English
Français
日本語
中文(中国)
検索
SearchUnify の検索をロード中
製品に関するサポートが必要な場合は、Qlik Support にお問い合わせください。
Qlik Customer Portal
メニュー
閉じる
SearchUnify の検索をロード中
製品に関するサポートが必要な場合は、Qlik Support にお問い合わせください。
Qlik Customer Portal
こちらにフィードバックをお寄せください
Talend Components
HDFS
HDFSのシナリオ
Hadoop分散ファイルシステムでのデータの計算
HDFSからのデータの取得
このページ上
手順
手順
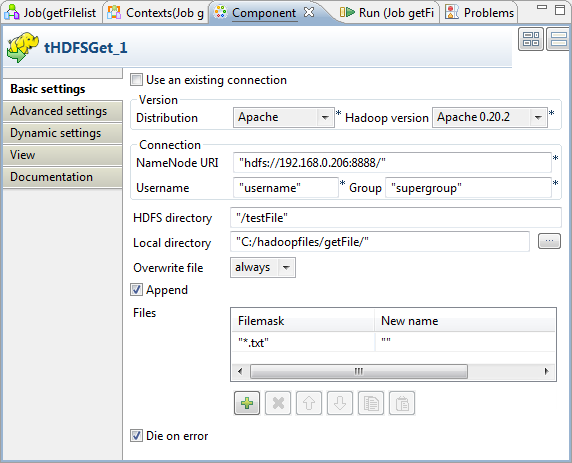
tHDFSGet
をダブルクリックし、
[Basic settings] (基本設定)
ビューでコンポーネントを定義します。
たとえば、
[Hadoop version] (Hadoopのバージョン)
リストからApache 0.20.2を選択します。
NameNode URI
の
[Username] (ユーザー名)
フィールドと
[Group] (グループ)
フィールドに、HDFSへの接続パラメーターを入力します。
WebHDFSを使用している場合、ロケーションはwebhdfs://masternode:portnumberとなります。WebHDFS with SSLはまだサポートされていません。
[HDFS directory] (HDFSディレクトリー)
フィールドに、ロードしたファイルを格納するHDFS内の場所を入力します。この例では
/testFile
です。
[Local directory] (ローカルディレクトリー)
フィールドの横にある
[...]
ボタンをクリックして、HDFSから抽出されたファイルを格納するフォルダーを参照します。このシナリオでは、ディレクトリーは
C:/hadoopfiles/getFile/
です。
[Overwrite file] (ファイルの上書き)
フィールドをクリックしてドロップダウンリストを表示します。
メニューから
[always] (常時)
を選択します。
[Files] (ファイル)
エリアで[+]ボタンをクリックして、抽出するファイルを定義するための行を追加します。
[File mask] (ファイルマスク)
カラムに
*.txt
と入力して、引用符に囲まれた
newLine
を置き換えます。
[New name] (新しい名前)
カラムはそのままにしておきます。これで、HDFS内の指定のディレクトリーからすべての
.txt
ファイルを、名前を変更せずに抽出できます。この例では、ファイルは
in.txt
です。
このページは役に立ちましたか?
このページまたはコンテンツにタイポ、ステップの省略、技術的エラーなどの問題が見つかった場合はお知らせください。
こちらにフィードバックをお寄せください
前のトピック
ローカルファイルのデータのロード
次のトピック
HDFSからのデータの読み取りとデータのローカル保存