
俳優のデータをNeo4jにインポートする
手順
-
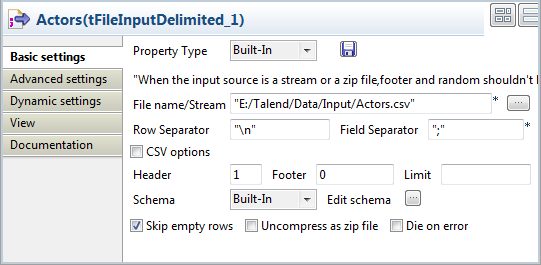
最初のtFileInputDelimitedコンポーネントをダブルクリックして、[Component] (コンポーネント)タブで[Basic settings] (基本設定)ビューを開きます。
-
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックして[Schema] (スキーマ)ダイアログボックスを開き、入力ファイルの構造をベースに入力スキーマを定義します。このサンプルでは、入力スキーマは2つのカラム、nameとbornで構成されています。どちらも[String] (文字列)型です。
終了したら[OK]をクリックして[Schema] (スキーマ)ダイアログボックスを閉じ、スキーマを次のコンポーネントにプロパゲートします。

-
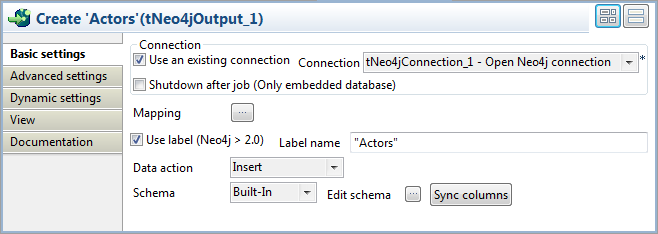
最初のtNeo4jOutputコンポーネントをクリックし、[Component] (コンポーネント)タブを選択して、[Basic settings] (基本設定)ビューをクリックします。
-
スキーマパネルでnameカラムを選択し、[Index creation] (インデックスの作成)タブをクリックし、[+]ボタンをクリックしてテーブルに行を追加し、このカラムにnameという名前のインデックスを作成します。
-
[Name] (名前)フィールドに、nameを二重引用符で囲んで入力します。
-
[Key] (キー)フィールドに、nameを二重引用符で囲んで入力し、インデックスにキーnameを与えます。
スキーマパネルをクリックしてインデックスの作成を確定し、[OK]をクリックしてマッピングエディターを閉じます。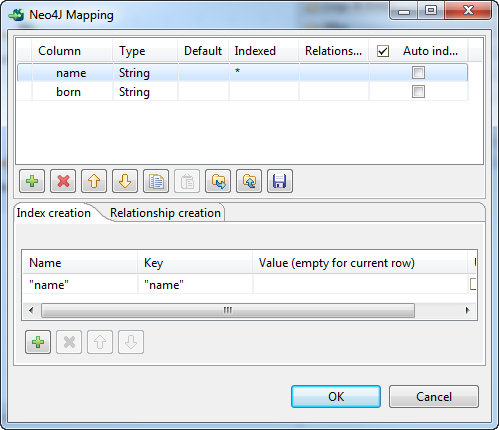
-