
MongoDBからのデータの読み取り
手順
-
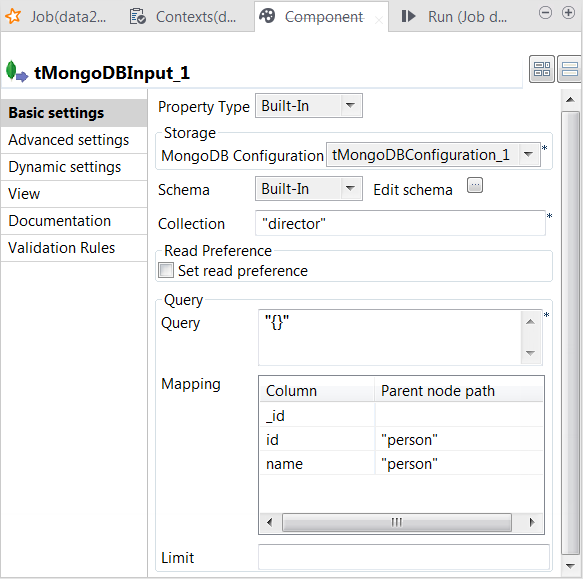
tMongoDBInputをダブルクリックし[Component] (コンポーネント)ビューを開きます。
-
この画像に示すように、[+]ボタンをクリックしてスキーマ出力カラムを追加します。
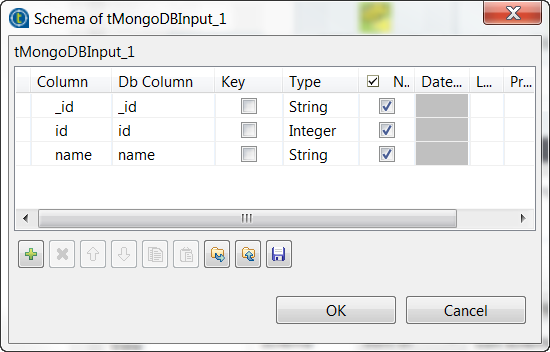 各ドキュメントのテクニカルIDを抽出する場合は、[_id]というカラムをスキーマに追加します。この例では、このカラムが追加されています。このテクニカルIDは、サンプルデータがデータベースに書き込まれた際にMongoDBによりランダムに作成されています。
各ドキュメントのテクニカルIDを抽出する場合は、[_id]というカラムをスキーマに追加します。この例では、このカラムが追加されています。このテクニカルIDは、サンプルデータがデータベースに書き込まれた際にMongoDBによりランダムに作成されています。