
カスタムマップとReduceコードを使う文字カウント(非推奨)
このシナリオは、ビッグデータ関連Talend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントを参照してください。
Apacheのドキュメンテーション(http://wiki.apache.org/hadoop/WordCount (英語のみ))で説明されているMapReduceのサンプルからヒントを得て、このシナリオでは、tJavaMRを使用して文字カウントを行うMapReduceプログラムを作成する方法を説明します。
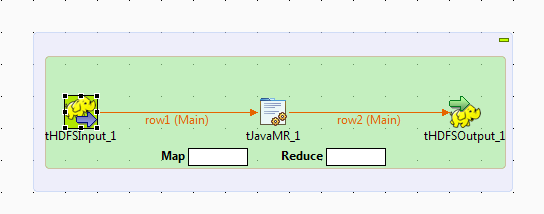
このシナリオで使用するサンプルデータは、以下のように読み取られます:
Hello world goodbye world
Hello hadoop bye Hadoopこのシナリオに沿って作業をする前に、使用するHadoopディストリビューションへの適切なアクセス権限と許可があることをご確認ください。その後、次の手順に従ってください。