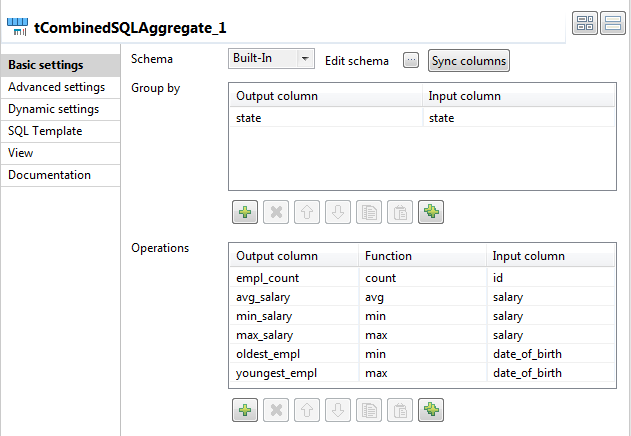
入力データのフィルタリングと集計
手順
-
デザインワークスペースでtCombinedSQLFilterを選択して、[Component] (コンポーネント)タブをクリックして設定パネルにアクセスします。
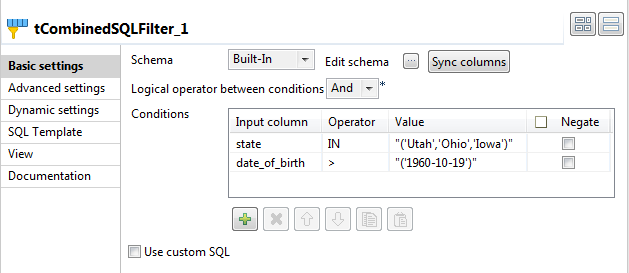
-
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックし、
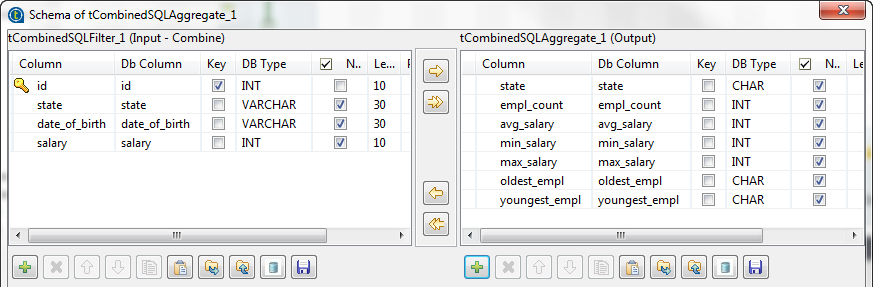 の設定を入力します:
tCombinedSQLAggregateコンポーネントは、前のコンポーネントから来る[id]、[state]、[date_of_birth]、および[salary]の4列のカラムをインスタンス化します。
の設定を入力します:
tCombinedSQLAggregateコンポーネントは、前のコンポーネントから来る[id]、[state]、[date_of_birth]、および[salary]の4列のカラムをインスタンス化します。