[Data Model] (データモデル)
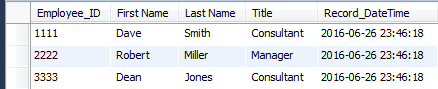
MySQLには2つのテーブルがあります。
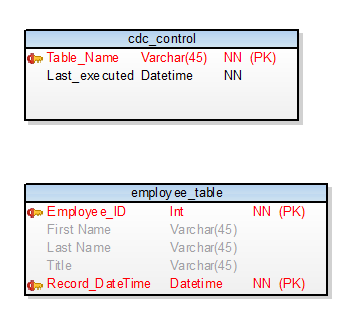
- employee_table: ソーステーブルです。
- cdc_control: 追跡されているテーブルと最後にアップデートされた時刻に関する情報があります。
ソースデータはemployee_tableにあります。