LOAD-satsen laddar fält från en fil, direkt från data i skriptet, från en tidigare inläst tabell, från en webbsida, från resultatet av en efterföljande SELECT-sats eller genom att generera data automatiskt.
Syntax:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]
inline data [ format-spec ] |
resident table-label |
autogenerate size )]
[ where criterion | while criterion ]
[ group_by groupbyfieldlist ]
[order_by orderbyfieldlist ]
Argument:
| Argument | Beskrivning |
|---|---|
| distinct |
Du kan använda distinct som predikat om du bara vill ladda unika poster. Om det finns dubblettposter laddas första förekomsten. Om du använder inledande LOAD måste du placera distinct i den första LOAD-satsen, eftersom distinct bara påverkar destinationstabellen. |
| fieldlist |
fieldlist ::= ( * | field {, field } )
En lista på de fält som ska läsas in. Genom att använda * som fältlista anger man alla fält i tabellen. field ::= ( fieldref | expression ) [as aliasname ]Fältdefinitionen måste alltid innehålla en litteral, en referens till ett befintligt fält eller ett uttryck. fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname är en text som är identisk med fältnamnet i tabellen. Observera att fältnamnet måste omslutas av raka, dubbla citationstecken eller av hakparenteser om det innehåller exempelvis mellanslag. Ibland är fältnamn inte explicit tillgängliga. Då används en annan metod: @fieldnumber representerar fältnumret i en avgränsad tabellfil. Det måste vara ett positivt heltal som föregås av "@". Numreringen går alltid från 1 och upp till antalet fält. @startpos:endpos representerar första och sista teckenposition för fältet i en fixpostfil med fasta fältpositioner. Positionerna måste vara positiva heltal. De två talen måste föregås av "@" och avgränsas av kolon. Numreringen går alltid från 1 och upp till antalet positioner. I det sista fältet används n som slutposition.
expression kan vara en numerisk funktion eller en strängfunktion baserad på ett eller flera andra fält i samma tabell. För ytterligare information, se uttryckens syntax. |
| from |
from används om data ska läsas in från en fil. file ::= [ path ] filename
Om sökvägen utelämnas söker QlikView efter filen i den mapp som specificerats av en Directory-sats. Om det inte finns någon Directory-sats söker QlikView i arbetskatalogen, som normalt är den katalog där QlikView-filen finns. Anteckning om informationI en QlikView-serverinstallation är standardarbetskatalogen C:\ProgramData\QlikTech\Documents. Standardarbetskatalogen kan ändras i QlikView Management Console.
filename kan innehålla standardiserade jokertecken från DOS (* och ? ). Detta får alla matchande filer i den angivna katalogen att läsas in. format-spec ::= ( fspec-item { , fspec-item } )Formatspecifikationen består av en lista med flera formatspecifikatorer inom parentes. |
| from_field | from_field används om data ska läsas in från ett tidigare inläst fält. fieldassource::=(tablename, fieldname) Fältet är namnet på tidigare inlästa tablename och fieldname. format-spec ::= ( fspec-item {, fspec-item } )Formatspecifikationen består av en lista med flera formatspecifikatorer inom parentes. |
| inline | inline används om data ska skrivas i skriptet, och inte läsas in från en fil. data ::= [ text ] Data som läses in med en inline-sats måste inledas och avslutas med dubbla citationstecken eller hakparenteser. Texten mellan dessa tolkas som om den vore skriven i en fil. Precis som du infogar en ny rad i en textfil bör du göra det även i texten i en inline-sats. Klicka på vanligt sätt på returtangenten när du skriver skriptet. Antalet kolumner definieras av den första raden. format-spec ::= ( fspec-item {, fspec-item } )Formatspecifikationen består av en lista med flera formatspecifikatorer inom parentes. |
| resident | resident används om data ska läsas in från en tidigare inläst tabell. table label är en etikett som föregår de LOAD- eller SELECT-satser som skapade den ursprungliga tabellen. Etiketten ska avslutas med kolon. När man använder en kombination av distinct och resident load-satser i QlikView 12.00 eller senare är laddningsordningen av data annorlunda än i QlikView 11.20. Lägg till en order by-sats för att definiera önskad laddningsordning. |
| autogenerate | autogenerate används när data ska genereras automatiskt av QlikView. size ::= number Number är ett heltal som anger antalet poster som ska genereras. Fältlistan får bara innehålla uttryck som inte kräver data från databaser. Endast konstanter och parameterlösa funktioner (exempelvis rand(), recno()) får ingå i uttrycken. |
| extension |
Du kan ladda data från analytiska kopplingar. Du måste använda extension-satsen för att anropa en funktion som definierats i plugin-programmet för komplement på serversidan, eller utvärdera ett skript. Du kan skicka en enstaka tabell till SSE-insticksprogrammet. En enstaka datatabell returneras. Fälten kallas Field1, Field2 och så vidare om insticksprogrammet inte specificerar namnen på de fält som returneras. Extension pluginname.functionname( tabledescription );
Hantering av datatyp i tabellfältdefinitionen Datatyper identifieras automatiskt i analytiska kopplingar. Om data inte har numeriska värden och minst en icke-NULL textsträng betraktas fältet som text. I alla andra fall betraktas det som numeriskt. Du kan tvinga datatypen genom att omsluta ett fältnamn med String() eller Mixed().
String() eller Mixed() kan inte användas utanför extension-tabellfältdefinitioner, och du kan inte använda andra QlikView-funktioner i en tabellfältdefinition. Mer om analytiska kopplingar För att skapa en analytisk koppling i QlikView Server eller QlikView Desktop, se: Analytiska kopplingar Du kan läsa mer om analytiska kopplingar i GitHub-databasen. qlik-oss/server-side-extension |
| where | where är ett tillägg som används för att tala om huruvida en post ska inkluderas i valet eller inte. Valet inkluderas om criterion är True. criterion är ett logiskt uttryck. |
| while |
while är en sats som används för att tala om när en post ska läsas in upprepade gånger. Samma post läses in så länge criterion är True. För att vara användbar måste en while-sats typiskt sett innehålla en IterNo( )-funktion. criterion är ett logiskt uttryck. |
| group_by |
group by används för att definiera över vilka fält data ska aggregeras (grupperas). Aggregeringsfälten ska på något sätt inlemmas i de uttryck som läses in. Inga andra fält än aggregeringsfälten får användas utanför aggregeringsfunktionerna i inläsningsuttrycken. groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order_by | order by är en sats som används för att sortera poster i en resident tabell innan de bearbetas av load-satsen. Den residenta tabellen kan sorteras efter ett eller flera fält, i stigande eller sjunkande ordning. Sortering görs i första hand efter talvärde, i andra hand efter nationell sorteringsspråkvariant. Satsen är endast användbar när datakällan är en resident tabell. Ordningsföljdsfälten anger efter vilket fält resident-tabellen sorteras. Ange fältets namn eller dess nummer i resident-tabellen (det första fältet får nummer 1). orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder är antingen asc för stigande eller desc för fallande. Om ingen sortorder anges, antas asc. fieldname, path, filename och aliasname är textsträngar som representerar det namnen antyder. Valfritt fält i källtabellen kan användas som fieldname. Däremot hamnar fält som har skapats med hjälp av as-satsen (aliasname) utanför och kan inte användas inuti samma load-sats. |
Om ingen datakälla anges genom from-, inline-, resident-, from_field- eller autogenerate-satser, kommer data att läsas in från resultatet av närmast efterföljande SELECT- eller LOAD-sats. Den efterföljande satsen får inte ha något prefix.
Exempel:
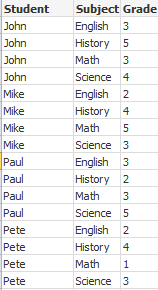
I detta exempel har vi indatafilen Grades.csv som innehåller betygen för varje student, kondenserat till ett fält:
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
Betygen, i en skala från 1 till 5, motsvarar Math, English, Science ochHistory. Vi kan dela upp betygen i separata värden genom att läsa in varje post flera gånger med en while-sats och använda IterNo( )-funktionen som räknare. Vid varje inläsning extraheras betyget med funktionen Mid och lagras i Grade och ämnet väljs med hjälp av funktionen pick och lagras i Subject. Den slutliga while-satsen innehåller testet för att kontrollera om alla betyg har lästs (fyra per student i det här fallet), vilket innebär att nästa studentpost ska läsas.
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
Resultatet blir en tabell med dessa data: