LOAD 语句可以加载以下来源的字段:文件、脚本中定义的数据、预先载入的输入表格、网页、后续 SELECT 语句产生的结果或自动生成的数据。
语法:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]
inline data [ format-spec ] |
resident table-label |
autogenerate size )]
[ where criterion | while criterion ]
[ group_by groupbyfieldlist ]
[order_by orderbyfieldlist ]
参数:
| 参数 | 说明 |
|---|---|
| distinct |
如果只想加载唯一记录,可以将 distinct 用作谓词。如果有重复的记录,将加载第一个实例。 如果使用前置的加载,则需要将 distinct 放在第一个 LOAD 语句中,因为 distinct 只会影响目标表。 |
| fieldlist |
fieldlist ::= ( * | field {, field } )
要加载的字段列表。使用 * 作为字段列表,表示表格中全部字段。 field ::= ( fieldref | expression ) [as aliasname ]字段定义必须总是包含精确的对现存字段或表达式的引用。 fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname 是指与表格中的字段名完全相同的文本。注意,如果包含空格,则字段名必须使用双引号或方括号括起来。有时字段名不会显示可用。这时使用另外的符号: @fieldnumber 表示字段数字在带分隔符的表格文件中。它必须是前面带“@”的正整数。编号通常从 1 开始至字段数字。 @startpos:endpos 代表在拥有固定长度记录的文件中字段的开始和结束位置。这两个位置必须都是正整数。这两个数字前都必须加上“@”并用冒号隔开。编号通常从 1 开始至位置数字。在最后一个字段中,将 n 用作结束位置。
expression 可以是数学函数或基于同一表格中一个或多个其他字段的字符串函数。有关详细信息,请参阅表达式的语法。 |
| from |
from 在数据需要从文件中加载时使用。 file ::= [ path ] filename
如果路径被省略,QlikView 则在由 Directory 语句指定的目录中搜索文件。如果没有 Directory 语句,QlikView 则在工作目录中进行搜索,该目录是 QlikView 文件所存放的目录。 信息注释在 QlikView 服务器安装中,默认工作目录是 C:\ProgramData\QlikTech\Documents。默认工作目录可在 QlikView 管理控制台 中修改。
filename 可能包含标准 DOS 通配符字符(* 和 ?)。这将导致指定目录中的所有匹配文件被加载。 format-spec ::= ( fspec-item { , fspec-item } )格式规格包含数个格式规格项目的列表(在括号中)。 |
| from_field | 如果需要从之前加载的字段加载数据,则使用 from_field 语句。 fieldassource::=(tablename, fieldname) 该字段是之前加载过的 tablename 和 fieldname 的名称。 format-spec ::= ( fspec-item {, fspec-item } )格式规格包含数个格式规格项目的列表(在括号中)。 |
| inline | inline 当数据需要输入脚本而不是从文件中加载时使用该符号。 data ::= [ text ] 通过 inline 子句的输入的数据由双引号或方括号括起来。括号之间的文本以同一方式被解释为文件的内容。因此,当您需要在文本文件中插入新的一行时,您应该在 inline 子句文本中重复该操作,即,键入脚本时按压输入键。列数通过第一行来定义。 format-spec ::= ( fspec-item {, fspec-item } )格式规格包含数个格式规格项目的列表(在括号中)。 |
| resident | 如果需要从之前加载的表格加载数据,则使用 resident 语句。 table label 是加在创建于原始表格的 LOAD 或 SELECT 语句之前的标签。该标签需要在末尾加上冒号。 在 QlikView 12.00 或更高版本中使用 distinct 和 resident load 语句的组合时,数据加载顺序与 QlikView 11.20 不同。要定义所需的加载顺序,请添加 order by 子句。 |
| autogenerate | autogenerate 是数据需要 QlikView 自动生成时使用。 size ::= number Number 是用来指示生成记录数字的整数。字段列表不能包含需要数据库中数据的表达式。表达式只允许使用常数和无参数函数(如 rand() 或 recno())。 |
| extension |
您可以从分析连接加载数据。您需要使用 extension 子句调用在服务器端扩展 (SSE) 插件中定义的函数或对脚本进行求值。 您可以向 SSE 插件发送单个表,随后将返回单个数据表。如果插件未指定返回的字段的名称,字段将命名为 Field1, Field2,以此类推。 Extension pluginname.functionname( tabledescription );
表字段定义中处理的数据类型 在分析连接中可以自动检测到数据类型。如果数据不包含数值且至少包含一个非 NULL 文本字符串,则该字段会被视为文本。在任何其他情况下,它都会被视为数值。 通过使用 String() 或 Mixed() 括住字段名称,可以强制定义数据类型。
String() 或 Mixed() 不能在 extension 表字段定义之外使用,您也不能在表字段定义中使用其他 QlikView 函数。 有关分析连接的更多信息 有关如何在 QlikView Server 或 QlikView Desktop 中创建分析连接,请参见:分析连接 您可在 GitHub 储存库中了解有关分析连接的更多信息。qlik-oss/server-side-extension |
| where | where 是一个子句,用于陈述一个记录是否应该包括在选择项内。如果 criterion 为 True,则将其包括在选择项内。 criterion 是一个逻辑表达式。 |
| while |
while 是用于显示记录是否应该反复读取的子句。只要 criterion 为 True,就会读取同一记录。为了能发挥作用,while 子句通常应包含 IterNo( ) 函数。 criterion 是一个逻辑表达式。 |
| group_by |
group by 是用于定义应聚合(组合)的字段的子句。 聚合字段应该以某种方式包含在加载表达式中。除了聚合字段没有其他字段可被用于加载表达式中的聚合函数之外。 groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order_by | order by 是用于被加于 load 语句之前的驻留表记录排序的子句。驻留表可以被一个或多个字段以升序或降序的顺序排序。排序主要由数值决定,其次由国家校对顺序决定。此子句仅在数据源为驻留表时可用。 排序字段用于指定驻留表按哪些字段排序。驻留表中的字段可以由其名称或其数字指定(第一个字段为 1)。 orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder 要么是 asc(对于升序),要么是 desc(对于降序)。如果未指定任何 sortorder,则采用 asc。 fieldname、path、filename 和 aliasname 都是表示他们各自名称的字符串。源表格中的任何字段都可用作 fieldname。但是,通过子句 (aliasname) 创建的字段不在此范围之内,且不能用于相同的 load 语句内。 |
如果 from、inline、resident、from_field 或 autogenerate 子句都无法给出数据源,则数据将从 SELECT 或 LOAD 语句随后得出的结果中加载。接下来的语句不应包含前缀。
示例:
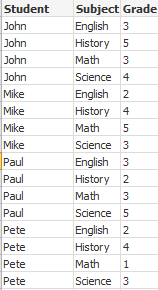
在本例中,输入文件 Grades.csv 包含合并在一个字段中的每个学生的分数:
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
分数(1-5 分)分别代表科目 Math、English、Science 和 History。通过使用 while 子句(使用 IterNo( ) 函数作为一个计数器)多次读取每一条记录,我们可以将分数划分为单独的值。在每一次读取中,分数使用 Mid 函数进行提取,使用 Grade 进行存储,而科目则使用 pick 函数进行选择,使用 Subject 进行存储。最后一个 while 子句包含检查是否所有分数均已读取的测试(本例中每个学生四个分数),这表示应该读取下一个学生记录。
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
结果是包含以下数据的表格: