
Working with lineage and impact analysis in Analytics
A complicated data web can result when diverse data sources intersect across multiple systems. This web can be difficult to untangle in order to understand what is happening. Lineage provides complete audit trails, simple visual flows, and views into these pipelines. The role of data lineage is valuable to business operations, providing the ability to understand where data originates, how it is transformed, and how it moves into, across, and outside your organization.
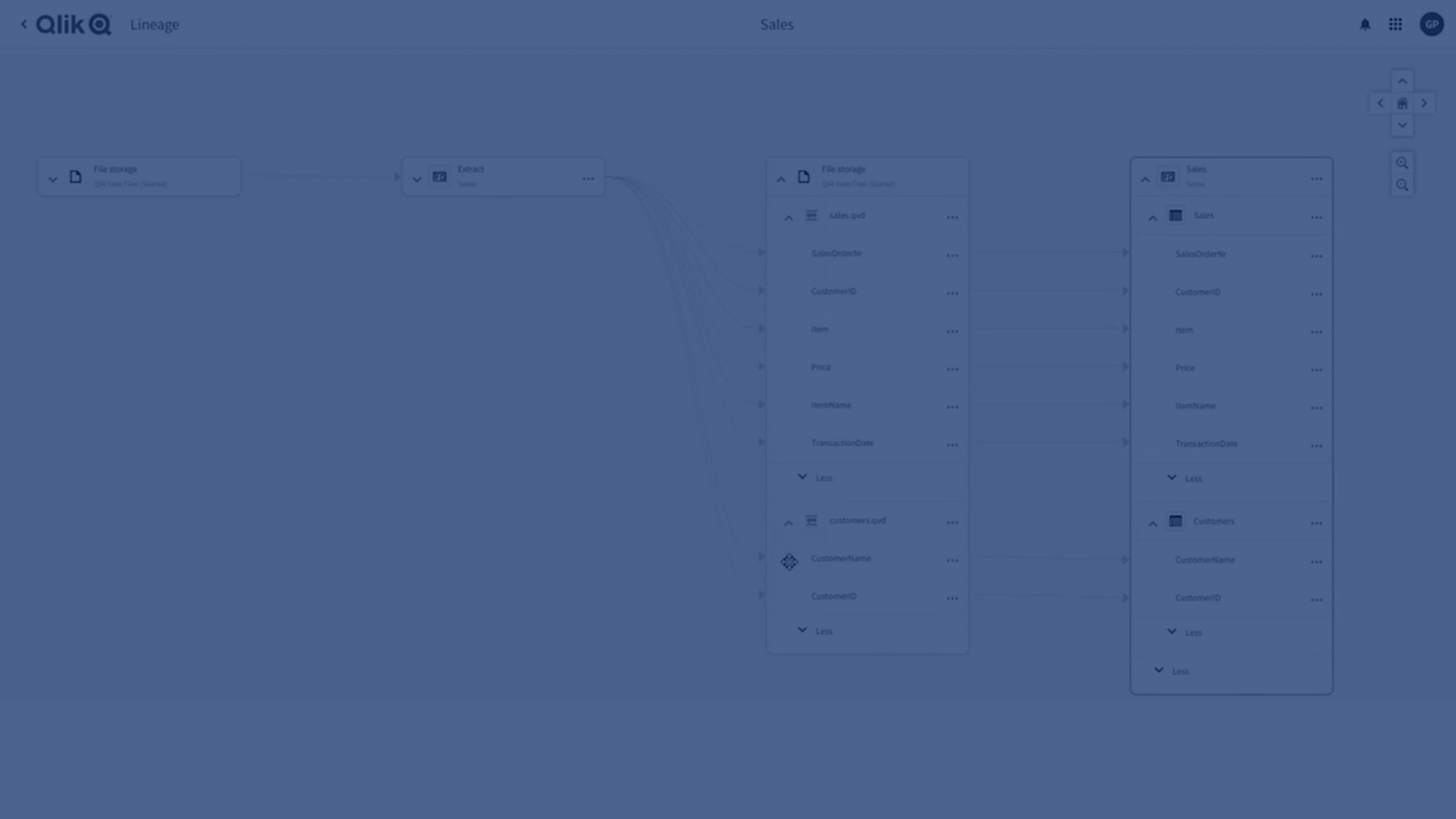
Data consumers can visually see the flow of each data field from original data source to end-user applications for every data asset that's managed in Qlik Cloud. This provides you with a detailed understanding of where and how data fields are being sourced or created. Field-level lineage helps you trust and understand your data at a deeper level, to create efficiencies in the data pipeline.
Qlik Cloud makes a clear distinction between Lineage and Impact analysis:
-
Lineage represents the history of a field or dataset, back through applications and transforms, to the original data source. Lineage answers questions such as: Where does this dataset come from? What is the ultimate source? How was it calculated?
-
Impact analysis shows a downstream view of a data element’s dependencies - which databases, applications, files or links would directly or indirectly be impacted if the value or structure of that particular field was changed. Impact analysis answers questions such as: Where else is this used? How much is this utilized? What is the impact if I make a change to this?
Access Lineage and Impact analysis graphs and views from several entry points in Qlik Sense, including dataset or application tiles, or directly from a Qlik Cloud chart. For more information on accessing lineage from a chart, see Lineage summary view in an application.