
分類モデルを評価し、生成する
tNLPModelコンポーネントは、CoNLL形式のトレーニングデータを読み込み、分類モデルを評価して生成します。
手順
-
tNLPModelコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
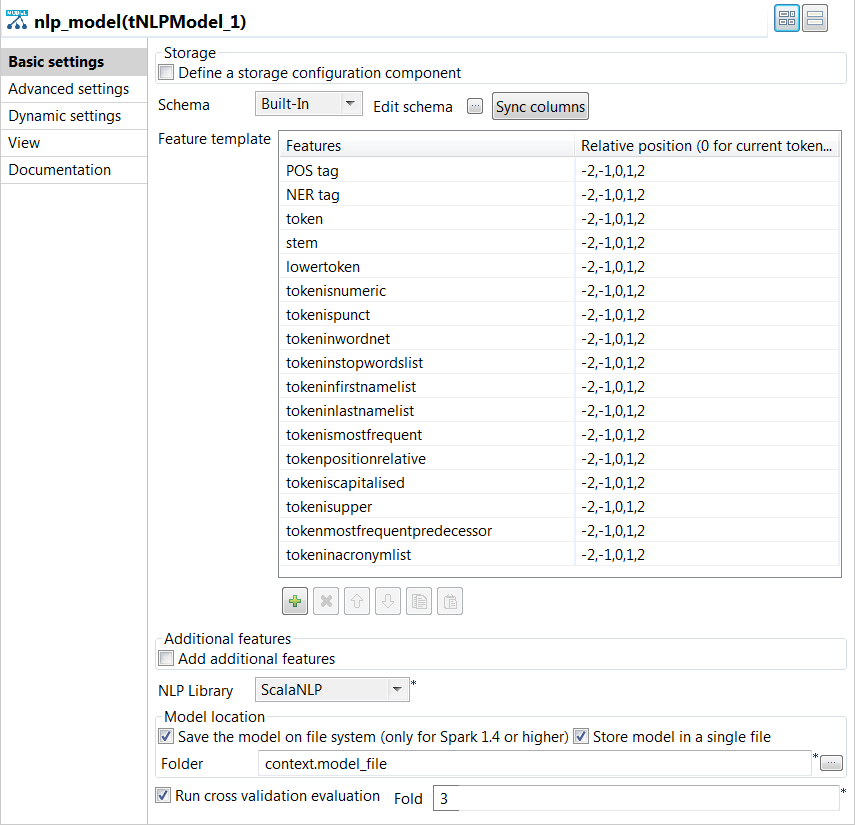
タスクの結果
次のアイテムも[Run] (実行)ビューのコンソールに出力されます。
| カテゴリー | アイテム |
|---|---|
| 各クラス | クラス名。 |
| True Positive: このクラスのエレメントとして正しく予測されたエレメントの数です。 | |
| Predicted True: このクラスのエレメントとして予測されたエレメントの数です。 | |
| Labeled True: このクラスに属するエレメントの数です。 | |
| [Precision] (適合率)スコア: 範囲は0から1までで、分類によって選択されたエレメントの特定のクラスに対する関連性の度合いを示します。 | |
| [Recall] (再現率)スコア: 範囲は0から1までで、関連するエレメントがいくつ選択されているかを示します。 | |
| F1スコア: [Precision] (適合率)スコアと[Recall] (再現率)スコアの調和平均です。 | |
| 最適モデル | グローバル加重F1スコア |
指定したフォルダーにモデルファイルが保存されます。これで、tNLPPredictコンポーネントで生成されたモデルを使用して、ネームドエンティティを予測し、テキストデータに自動的にラベル付けできます。