
Spark Batchジョブを使ってCloudera Kuduでデータの読み書きを行う
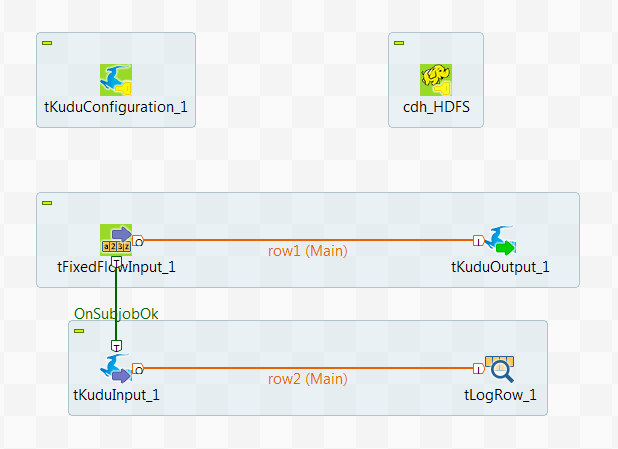
このシナリオでは、Kuduコンポーネントを使ってSpark Batchジョブを作成し、データを分割してKuduテーブルに書き込んでから、Kuduからデータの一部を読み取ります。
このシナリオは、ビッグデータ関連Talend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
01;ychen;30
02;john;40
03;yoko;20
04;tom;60
05;martin;50このデータには、一部の人名、これらの人に割り当てられたID番号、および年齢が含まれています。
このカラムはプライマリキーカラムであり、このシナリオでは年齢が範囲のパーティショニングに使われるため、年齢の区別が意図的に行われます。
サンプルデータはあくまでも例示用です。
-
使うSparkクラスターとCloudera Kuduデータベースが正しくインストールされ、実行されていることを確認します。
-
Talendジョブが実行されているクライアントマシンが、使用するHadoopクラスターのノードのホスト名を認識できることを確認します。そのためには、そのHadoopクラスターのサービスに使用するIPアドレス/ホスト名のマッピングエントリーをクライアントマシンのhostsファイルに追加します。
たとえば、Hadoopネームノードサーバーのホスト名がtalend-cdh550.weave.localで、IPアドレスが192.168.x.xの場合、マッピングエントリーは192.168.x.x talend-cdh550.weave.localとなります。
-
使用するクラスターがkerberosで保護されている場合は、Talendジョブが実行されているコンピュータにkerberosが正しくインストールされ、設定されていることをご確認ください。使用するkerberosモードに応じて、そのマシンでkerberos kinitチケットまたはキータブを利用できるようにしておく必要があります。
詳細は、Talend Help Center (https://help.talend.com (英語のみ))のStudio with Big DataでKerberosを使う方法を検索してください。
-
[Repository] (リポジトリー)の[Hadoop cluster] (Hadoopクラスター)ノードからHadoop接続メタデータを定義します。この方法では、この接続を別のジョブで再利用できるだけでなく、ジョブでこの接続を使用する際に、Hadoopクラスターへの接続が適切に設定されていて、正しく機能していることを確認することもできます。
再利用可能なHadoop接続の設定の詳細は、Talend StudioユーザーガイドのHadoop接続の一元化をご覧ください。
再利用可能なHadoop接続の設定の詳細は、Talend Help Center(https://help.talend.com (英語のみ))でHadoop接続の一元化を検索してください。