
Écrire et lire des données depuis Cloudera Kudu à l'aide d'un Job Spark Batch
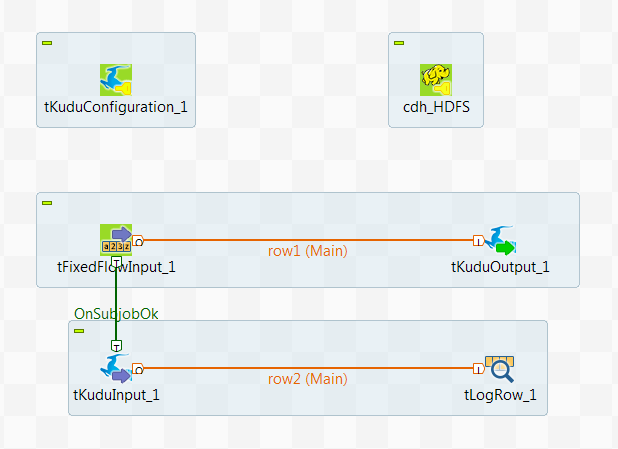
Dans ce scénario, vous allez créer un Job Spark Batch utilisant les composants Kudu pour partitionner et écrire de données dans une table Kudu, puis lire certaines de ces données depuis Kudu.
Ce scénario s'applique uniquement aux solutions Talend avec Big Data.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
01;ychen;30
02;john;40
03;yoko;20
04;tom;60
05;martin;50Ces données contiennent les noms de plusieurs personnes, leur âge et des ID distribués entre ces personnes.
Les âges sont distincts les uns des autres, car cette colonne est la colonne de clé primaire et est utilisée pour effectuer le partitionnement dans ce scénario.
Notez que les données d'exemple sont créées à des fins de démonstration uniquement.
-
Assurez-vous que le cluster Spark et la base de données Cloudera Kudu à utiliser ont bien été installés et sont en cours de fonctionnement.
-
Vérifiez que la machine cliente sur laquelle les Jobs Talend sont exécutés peut reconnaître les noms d'hôtes des nœuds du cluster Hadoop à utiliser. Dans cet objectif, ajoutez les mappings des entrées adresse IP/nom d'hôte pour les services de ce cluster Hadoop dans le fichier hosts de la machine cliente.
Par exemple, si le nom d'hôte du serveur du NameNode Hadoop est talend-cdh550.weave.local et son adresse IP est 192.168.x.x, l'entrée du mapping est la suivante 192.168.x.x talend-cdh550.weave.local.
-
Si le cluster à utiliser est sécurisé avec Kerberos, assurez-vous d'avoir correctement installé et configuré Kerberos sur la machine sur laquelle votre Job Talend est exécuté. Selon le mode de Kerberos utilisé, le ticket Kinit ou le Keytab Kerberos doit être disponible sur la machine.
Pour plus d'informations, recherchez comment utiliser Kerberos dans le Studio Big Data sur Talend Help Center (https://help.talend.com (uniquement en anglais)).
-
Définissez la métadonnée de connexion à Hadoop depuis le nœud Hadoop cluster du Repository. Ainsi, vous pourrez réutiliser cette connexion dans différents Jobs, mais aussi vous assurer que la connexion à votre cluster Hadoop a bien été configurée et fonctionne correctement lorsque vous l'utilisez dans vos Jobs.
Pour plus d'informations concernant la configuration d'une connexion à Hadoop réutilisable, consultez Centraliser une connexion Hadoop dans le Guide d'utilisation de Studio Talend.
Pour plus d'informations concernant la configuration d'une connexion à Hadoop réutilisable, recherchez Centraliser une connexion Hadoop, sur Talend Help Center (https://help.talend.com (uniquement en anglais)).