トークン化されたテキストをCoNLL形式に変換する
分類モデルをテキストから学習できるようにするには、このテキストをトークンに分割し、tNormalizeを使用してCoNLL形式に変換する必要があります。
手順
-
tNLPPreprocessingコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
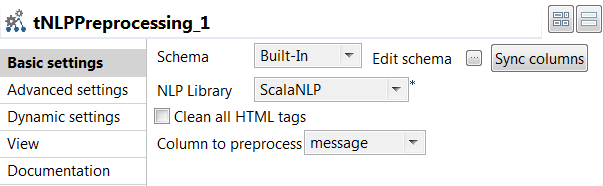
- [Sync columns] (カラムを同期)をクリックすると、ジョブで接続している先行コンポーネントからスキーマが取得されます。
- [NLP Library] (NLPライブラリー)リストから、トークン化に使用するライブラリーを選択します。このサンプルでは、ScalaNLPが使用されています。
-
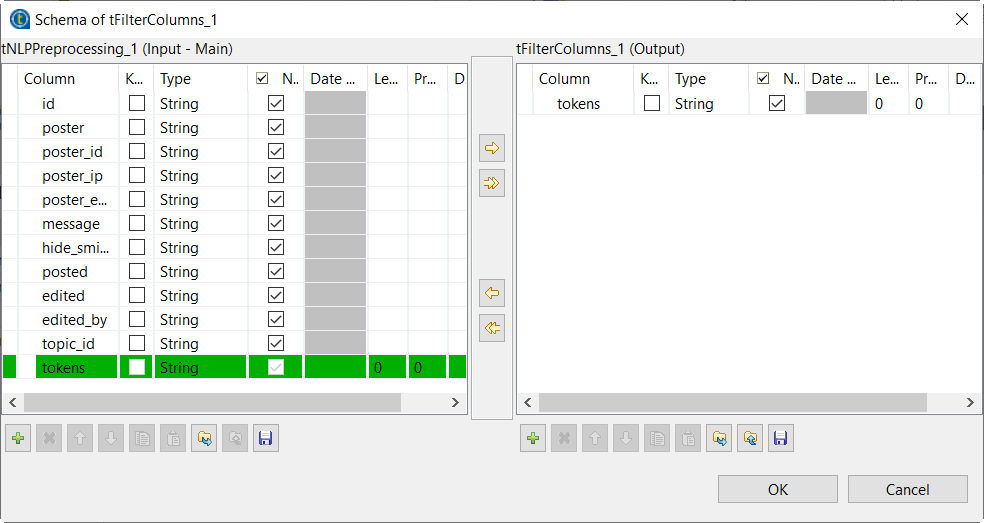
[Edit schema] (スキーマを編集)をクリックして、tokensカラムを出力スキーマに追加します。これが正規化するカラムであるためです。続いて、[OK]をクリックして確定します。
-
tNormalizeコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
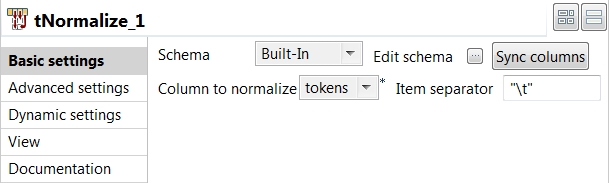
- [Sync columns] (カラムを同期)をクリックすると、ジョブで接続している先行コンポーネントからスキーマが取得されます。
- [Column to normalize] (正規化するカラム)リストからtokensを選択します。
- 出力ファイルで[Item separator] (アイテム区切り)フィールドに"\t"を入力して、トークンをタブで区切ります。
-
tFileOutputDelimitedコンポーネントをダブルクリックして[Basic settings] (基本設定)ビューを開き、そのプロパティを定義します。
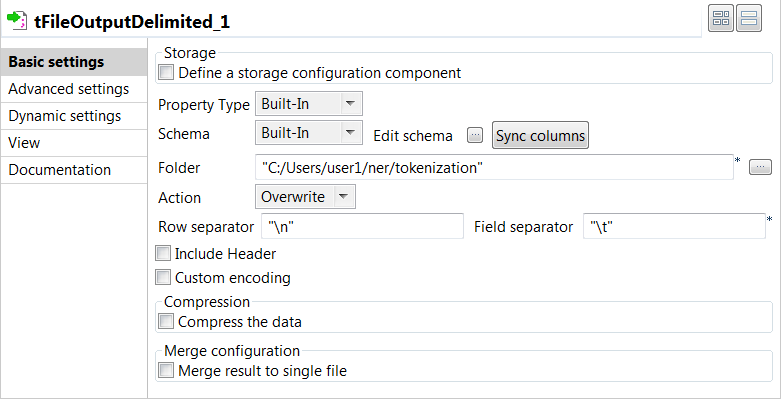
- [Sync columns] (カラムを同期)をクリックすると、ジョブで接続している先行コンポーネントからスキーマが取得されます。
- [Folder] (フォルダー)フィールドに、CoNLLファイルを保存するフォルダーへのパスを指定します。
- [Row Separator] (行区切り)フィールドに"\n"を入力します。
- [Field Separator] (フィールド区切り)フィールドに"\t"を入力して、フィールドをタブで区切ります。
タスクの結果
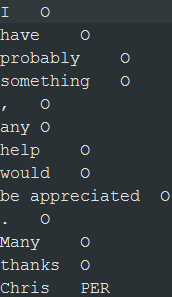
指定したフォルダーに出力ファイルが作成されます。ファイルには、行ごとに1つのトークンがある単一カラムが含まれています。
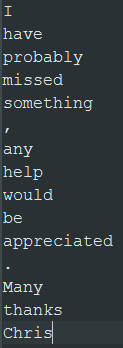
このテキストデータから分類モデルを学習するには、その前に人名にはPER、他のトークンにはOのラベルを手動で付けます。