Convertir le texte divisé en termes individuels au format CoNLL
Afin de pouvoir apprendre un modèle de classification à partir d'un texte, vous devez le diviser en termes individuels, puis le convertir au format CoNLL à l'aide du tNormalize.
Procédure
-
Double-cliquez sur le tNLPPreprocessing pour afficher sa vue Basic settings et définissez les propriétés du composant.
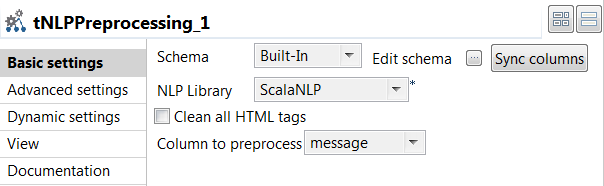
- Cliquez sur le bouton Sync columns afin de récupérer le schéma du composant précédent.
- Dans la liste NLP Library, sélectionnez la bibliothèque à utiliser pour diviser le texte en termes individuels. Dans cet exemple, ScalaNLP est utilisée.
-
Cliquez sur Edit schema pour ajouter la colonne tokens au schéma de sortie car il s'agit de la colonne à normaliser. Cliquez sur OK pour valider.

-
Double-cliquez sur le tNormalize pour afficher sa vue Basic settings et définissez les propriétés du composant.
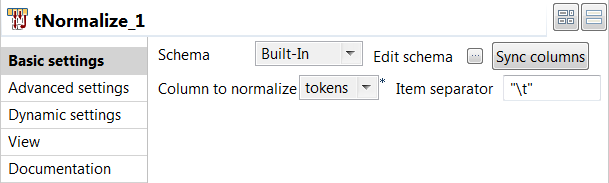
- Cliquez sur le bouton Sync columns afin de récupérer le schéma du composant précédent.
- Dans la liste Column to normalize, sélectionnez tokens.
- Dans la liste Item separator, saisissez "\t" afin de séparer les termes individuels par une tabulation dans le fichier de sortie.
-
Double-cliquez sur le tFileOutputDelimited pour afficher sa vue Basic settings et définissez ses propriétés.
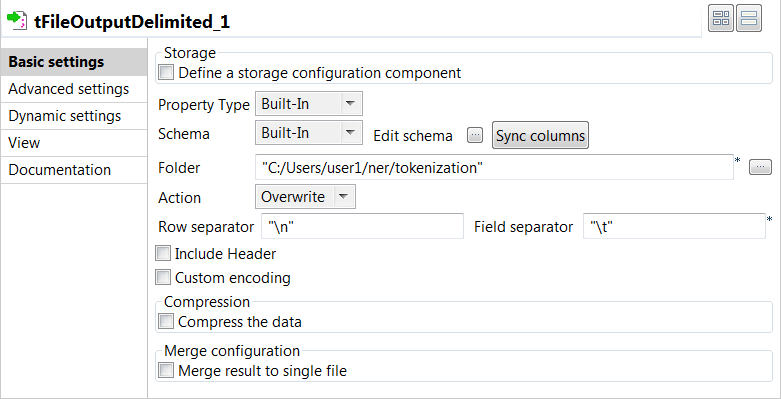
- Cliquez sur le bouton Sync columns afin de récupérer le schéma du composant précédent.
- Dans le champ Folder, configurez le chemin d'accès au dossier dans lequel vous souhaitez enregistrer les fichiers CoNLL.
- Dans le champ Row Separator, saisissez "\n".
- Dans le champ Field Separator, saisissez "\t" pour séparer les champs par une tabulation.
Résultats
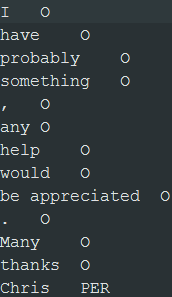
Les fichiers de sortie sont créés dans le dossier spécifié. Les fichiers comporte une seule colonne contenant un terme individuel par ligne.
Vous pouvez ensuite annoter les noms de personnes avec le libellé PER et les autres termes individuels avec O avant de pouvoir apprendre un modèle de classification à partir de ces données textuelles :