
Rank - fonction de graphique
Rank() évalue les lignes du graphique dans l'expression et, pour chaque ligne, affiche la position relative de la valeur de la dimension évaluée dans l'expression. Lors de l'évaluation de l'expression, la fonction compare le résultat à celui des autres lignes contenant le segment de colonne actif et renvoie le classement de la ligne active dans ce segment.
Segments de colonne
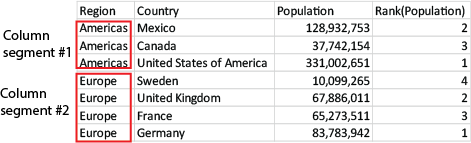
Dans d'autres graphiques que les tableaux, le segment de colonne actif est défini tel qu'il apparaît dans l'équivalent du tableau simple du graphique.
Rank([TOTAL] expr[, mode[, fmt]])
double
| Argument | Description |
|---|---|
| expr | Expression ou champ contenant les données à mesurer. |
| mode | Spécifie la représentation numérique du résultat de la fonction. |
| fmt | Spécifie la représentation textuelle du résultat de la fonction. |
| TOTAL |
Si le graphique est unidimensionnel ou si l'expression est précédée du qualificateur TOTAL, l'évaluation de la fonction porte sur la colonne toute entière. Si la table ou l'équivalent en tableau comporte plusieurs dimensions verticales, le segment de colonne actif comprend uniquement les lignes contenant les mêmes valeurs que la ligne active dans toutes les colonnes de dimensions, à l'exception de la colonne affichant la dernière dimension dans l'ordre de tri inter-champs. |
Le classement est renvoyé sous forme de valeur double, qui est, dans le cas d'un classement unique pour chaque ligne, un entier compris entre 1 et le nombre de lignes dans le segment de colonne actif.
Dans le cas où plusieurs lignes partagent le même classement, il est possible de contrôler la représentation alphanumérique à l'aide des paramètres mode et fmt.
mode
Le second argument, mode, admet les valeurs suivantes :
| Valeur | Description |
|---|---|
| 0 (par défaut) |
Si tous les rangs du groupe commun sont inférieurs à la valeur médiane du classement total, toutes les lignes obtiennent le rang le plus bas du groupe. Si tous les rangs du groupe commun sont supérieurs à la valeur médiane du classement total, toutes les lignes obtiennent le rang le plus élevé du groupe. Si les rangs du groupe commun se trouvent de part et d'autre de la valeur médiane, toutes les lignes obtiennent la valeur correspondant à la moyenne du classement supérieur et du classement inférieur du segment de colonne entier. |
| 1 | Rang le plus bas sur toutes les lignes. |
| 2 | Rang moyen sur toutes les lignes. |
| 3 | Rang le plus élevé sur toutes les lignes. |
| 4 | Rang le plus bas sur la première ligne, puis incrémenté d'une unité pour chaque ligne. |
fmt
Le troisième argument, fmt, admet les valeurs suivantes :
| Valeur | Description |
|---|---|
| 0 (par défaut) | Valeur faible - valeur élevée sur toutes les lignes (par exemple 3 - 4). |
| 1 | Valeur faible sur toutes les lignes. |
| 2 | Valeur faible sur la première ligne, vide sur les lignes suivantes. |
L'ordre des lignes pour le mode 4 et le format fmt 2 est déterminé par l'ordre de tri des dimensions du graphique.
Créez deux visualisations à partir des dimensions Product et Sales et une autre à partir de Product et UnitSales. Ajoutez des mesures comme indiqué dans la table suivante.
| Exemples | Résultats |
|---|---|
|
Exemple 1. Créez une table comportant les dimensions Customer et Sales et la mesure Rank(Sales). |
Le résultat dépend de l'ordre de tri des dimensions. Si la table est triée d'après la dimension Customer, la table répertorie toutes les valeurs de la dimension Sales pour Astrida, puis Betacab, et ainsi de suite. Les résultats de la mesure Rank(Sales) indiquent 10 pour la valeur Sales 12, 9 pour la valeur Sales 13, et ainsi de suite, avec une valeur de rang de 1 renvoyée pour la valeur Sales 78. Le segment de colonne suivant commence par Betacab, pour lequel la première valeur de la dimension Sales dans le segment est égale à 12. La valeur de rang correspondante fournie pour la mesure Rank(Sales) est 11. Si la table est triée sur la base de la dimension Sales, les segments de colonne se composent des valeurs de la dimension Sales et des valeurs Customer correspondantes. Étant donné qu'il y a deux valeurs Sales égales à 12 (pour Astrida et Betacab), la valeur de Rank(Sales) pour ce segment de colonne correspond à 1-2, pour chaque valeur définie sous Customer. Cela s'explique par le fait qu'il y a deux valeurs de dimension Customer pour la valeur de dimension Sales 12. S'il y avait eu 4 valeurs, le résultat serait 1-4, pour toutes les lignes. Cela montre le résultat obtenu avec la valeur par défaut (0) de l'argument fmt. |
| Exemple 2. Remplacez la dimension Customer par la dimension Product et ajoutez la mesure Rank(Sales,1,2). | 1 est renvoyé sur la première ligne de chaque segment de colonne tandis que toutes les autres lignes restent vides, car les arguments mode et fmt sont définis sur 1 et 2 respectivement. |
Résultats pour l'exemple 1, avec la table triée d'après la dimension Customer :
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Résultats pour l'exemple 1, avec la table triée d'après la dimension Sales :
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
Données utilisées dans les exemples :
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');