
Rank - diagramfunctie
Rank() evalueert de rijen van het diagram in de uitdrukking en geeft voor elke rij de relatieve positie van de waarde van de dimensie die in de uitdrukking wordt geëvalueerd weer. Bij de evaluatie van de uitdrukking vergelijkt de functie het resultaat met het resultaat van de andere rijen die het huidige kolomsegment bevatten, en retourneert de rangschikking van de huidige rij in het segment.
Kolomsegmenten
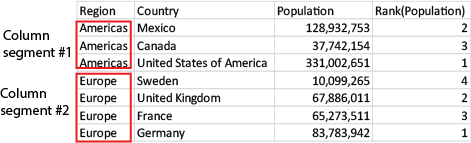
Voor andere diagrammen dan tabellen wordt het huidige kolomsegment gedefinieerd zoals deze wordt weergegeven in het equivalent van de strakke tabel.
Syntaxis:
Rank([TOTAL] expr[, mode[, fmt]])
Retourgegevenstypen: dual
Argumenten:
| Argument | Beschrijving |
|---|---|
| expr | De uitdrukking die of het veld dat de gegevens bevat die moeten worden gemeten. |
| mode | Geeft de numerieke representatie aan van het resultaat van de functie. |
| fmt | Geeft de tekstrepresentatie aan van het resultaat van de functie. |
| TOTAL |
Als het diagram eendimensionaal is of als de uitdrukking wordt voorafgegaan door de kwalificatie TOTAL, wordt de functie geëvalueerd voor de hele kolom. Als de tabel of het equivalent van de tabel meerdere verticale dimensies heeft, omvat het huidige kolomsegment alleen rijen met dezelfde waarden als de huidige rij in alle dimensiekolommen, met uitzondering van de kolom waarin de laatste dimensie wordt weergegeven in de onderlinge sorteervolgorde van de velden. |
De rangorde wordt geretourneerd als een dubbele waarde. Als elke rij een unieke rangschikking heeft, is dit een geheel getal tussen 1 en het aantal rijen in het huidige kolomsegment.
Als meerdere rijen dezelfde rangschikking hebben, kan de tekstuele en numerieke representatie worden bestuurd met de parameters mode en fmt.
mode
Het tweede argument, mode, kan de volgende waarden hebben:
| Waarde | Beschrijving |
|---|---|
| 0 (standaard) |
Als alle rangnummers in de delende groep lager zijn dan de middenwaarde van de volledige rangschikking, krijgen alle rijen het laagste positienummer in de delende groep. Als alle rangnummers in de delende groep hoger zijn dan de middenwaarde van de volledige rangschikking, krijgen alle rijen het hoogste rangnummer in de delende groep. Als rangnummers in de delende groep zowel lager als hoger zijn dan de middenwaarde van de volledige rangschikking, krijgen alle rijen de waarde die overeenkomt met het gemiddelde van het hoogste en laagste rangnummer in het volledige kolomsegment. |
| 1 | Laagste rangnummer in alle rijen. |
| 2 | Gemiddelde rangnummer in alle rijen. |
| 3 | Hoogste rangnummer in alle rijen. |
| 4 | Laagste rangnummer in eerste rij, vervolgens opgehoogd met één voor elke rij. |
fmt
Het derde argument, fmt, kan de volgende waarden hebben:
| Waarde | Beschrijving |
|---|---|
| 0 (standaard) | Lage waarde - hoge waarde in alle rijen (bijvoorbeeld 3 - 4). |
| 1 | Lage waarde in alle rijen. |
| 2 | Lage waarde in eerste rij, leeg in alle volgende rijen. |
De volgorde van rijen voor mode 4 en fmt 2 wordt bepaald door de sorteervolgorde van de diagramdimensies.
Voorbeelden en resultaten:
Maak twee visualisaties op basis van de dimensies Product en Sales en nog één op basis van Product en UnitSales. Voeg metingen toe zoals weergegeven in de volgende tabel.
| Voorbeelden | Resultaten |
|---|---|
|
Voorbeeld 1. Maak een tabel met de dimensies Customer en Sales en de meting Rank(Sales) |
Het resultaat is afhankelijk van de sorteervolgorde van de dimensies. Als de tabel wordt gesorteerd op Customer, bevat de tabel alle waarden van Sales voor Astrida, daarna Betacab enzovoort. De resultaten voor Rank(Sales) geven 10 aan voor de waarde 12 van Sales, 9 voor de waarde 13 van Sales enzovoort, waarbij de rangordewaarde 1 wordt geretourneerd voor de waarde 78 van Sales. Het volgende kolomsegment begint met Betacab, waarvoor de eerste waarde van Sales in het segment 12 bedraagt. De rangordewaarde van Rank(Sales) hiervoor is gegeven als 11. Als de tabel wordt gesorteerd op Sales, bestaan de kolomsegmenten uit de waarden van Sales en de bijbehorende Customer. Aangezien er twee waarden 12 zijn voor Sales (voor Astrida en Betacab), is de waarde van Rank(Sales) voor dat kolomsegment 1-2, voor elke waarde van Customer. Dit komt doordat er twee waarden van Customer zijn voor de waarde 12 van Sales. Als er 4 waarden waren geweest, zou het resultaat 1-4 zijn, voor alle rijen. Dit geeft aan hoe het resultaat eruitziet voor de standaardwaarde (0) van het argument fmt. |
| Voorbeeld 2. Vervang de dimensie Customer door Product en voeg de meting toe Rank(Sales,1,2) | Dit geeft 1 als resultaat in de eerste rij van elk kolomsegment en laat alle andere rijen leeg omdat de argumenten mode en fmt zijn ingesteld op respectievelijk 1 en 2. |
Resultaten voor voorbeeld 1, waarbij de tabel is gesorteerd op Customer:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Resultaten voor voorbeeld 1, waarbij de tabel is gesorteerd op Sales:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
Gegevens die worden gebruikt in voorbeelden:
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');