
Rank — funkcja wykresu
Funkcja Rank() oblicza wartości wierszy wykresu w wyrażeniu i dla każdego wiersza zwraca względną pozycję wartości wymiaru obliczanego w wyrażeniu. Obliczając wartość wyrażenia, funkcja porównuje wynik z wynikiem dla innych wierszy zawierających bieżący segment kolumny i zwraca klasyfikację bieżącego wiersza w ramach segmentu.
Segmenty kolumn
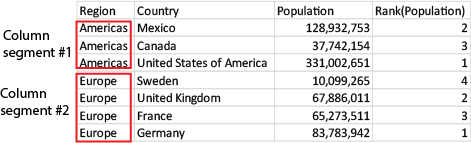
W przypadku wykresów innych niż tabele bieżący segment kolumny jest definiowany tak, jak pojawia się w odpowiedniku tabeli prostej dla takiego wykresu.
Składnia:
Rank([TOTAL] expr[, mode[, fmt]])
Typ zwracanych danych: dual
Argumenty:
| Argument | Opis |
|---|---|
| expr | Wyrażenie lub pole zawierające mierzone dane. |
| mode | Określa reprezentację liczbową wyniku funkcji. |
| fmt | Określa reprezentację tekstową wyniku funkcji. |
| TOTAL |
Jeśli wykres jest jednowymiarowy lub wyrażenie jest poprzedzone kwalifikatorem TOTAL, funkcja będzie obliczana w całej kolumnie. Jeśli tabela lub równoważnik tabeli zawiera wiele wymiarów pionowych, wówczas segment bieżącej kolumny będzie zawierał tylko wiersze z takimi samymi wartościami we wszystkich kolumnach wymiaru jak bieżący wiersz, ale bez kolumny przedstawiającej ostatni wymiar w kolejności sortowania między polami. |
Klasyfikacja jest zwracana jako wartość podwójna, która w sytuacji, gdy każdy wiersz ma niepowtarzalną klasyfikację, będzie liczbą całkowitą z zakresu od 1 do liczby wierszy w bieżącym segmencie kolumny.
Jeśli kilka wierszy ma tę samą klasyfikację, reprezentację tekstową i liczbową można kontrolować za pomocą argumentów mode i fmt.
mode
Drugi argument, mode, może mieć następujące wartości:
| Wartość | Opis |
|---|---|
| 0 (domyślnie) |
Jeśli wszystkie klasyfikacje w grupie o takich samych klasyfikacjach należą do dolnego zakresu wartości środkowej całej klasyfikacji, wówczas wszystkie wiersze uzyskują najniższą klasyfikację w tej grupie. Jeśli wszystkie klasyfikacje w grupie o takich samych klasyfikacjach należą do górnego zakresu wartości środkowej całej klasyfikacji, wówczas wszystkie wiersze uzyskują najwyższą klasyfikację w tej grupie. Jeśli klasyfikacje w grupie o takich samych klasyfikacjach obejmują środek zakresu całej klasyfikacji, wszystkie wiersze otrzymują wartość odpowiadającą średniej klasyfikacji górnej i dolnej w całym segmencie kolumny. |
| 1 | Najniższa klasyfikacja we wszystkich wierszach. |
| 2 | Średnia klasyfikacja we wszystkich wierszach. |
| 3 | Najwyższa klasyfikacja we wszystkich wierszach. |
| 4 | Najniższa klasyfikacja w pierwszym wierszu, następnie zwiększana o jeden dla każdego wiersza. |
fmt
Trzeci argument, fmt, może mieć następujące wartości:
| Wartość | Opis |
|---|---|
| 0 (domyślnie) | Niska wartość - wysoka wartość we wszystkich wierszach (na przykład 3–4). |
| 1 | Niska wartość we wszystkich wierszach. |
| 2 | Niska wartość w pierwszym wierszu, pusta w kolejnych wierszach. |
Kolejność wierszy dla argumentów mode 4 i fmt 2 jest określona przez kolejność sortowania wymiarów wykresu.
Przykłady i wyniki:
Utwórz dwie wizualizacje z wymiarów Product i Sales oraz kolejną wizualizację z wymiarów Product i UnitSales. Dodaj miary zgodnie z poniższą tabelą.
| Przykłady | Wyniki |
|---|---|
|
Przykład 1. Utwórz tabelę z wymiarami Customer i Sales oraz miarą Rank(Sales) |
Wynik zależy od kolejności sortowania wymiarów. Jeśli tabele są sortowane według wymiaru Customer, w tabeli zostaną wyszczególnione wszystkie wartości z kolumny Sales dla klienta Astrida, a następnie dla klienta Betacab itd. Wyniki w kolumnie Rank(Sales) będą następujące: 10 dla wartości Sales 12, 9 dla wartości Sales 13 itd., z wartością klasyfikacji 1 zwracaną dla wartości Sales 78. Następny segment kolumny rozpoczyna się wartością Betacab, dla której pierwszą wartością w kolumnie Sales w tym segmencie jest 12. Wartość klasyfikacji Rank(Sales) w tym przypadku wynosi 11. Jeśli tabela zostanie posortowana według wymiaru Sales, segmenty kolumny będą mieć wartości wymiaru Sales i odpowiadające im wartości wymiaru Customer. Ze względu na występowanie dwóch wartości 12 dla wymiaru Sales (dla klientów Astrida i Betacab) wartość miary Rank(Sales) dla tego segmentu kolumny wynosi 1–2, dla każdej wartości wymiaru Customer. Wynika to z faktu, że istnieją dwie wartości wymiaru Customer dla wartości Sales 12. Gdyby były cztery wartości, wynik wynosiłby 1–4 dla wszystkich wierszy. Ten przykład pokazuje, jak wyglądałyby wyniki dla wartości domyślnej (0) argumentu fmt. |
| Przykład 2. Zastąp wymiar Customer wymiarem Product i dodaj miarę Rank(Sales,1,2) | Zwrócona zostanie wartość 1 w pierwszym wierszu każdego segmentu kolumny, a wszystkie pozostałe wiersze będą puste, ponieważ argumenty mode i fmt mają odpowiednio wartości 1 i 2. |
Wyniki przykładu 1, w tabeli posortowanej według wymiaru Customer:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Wyniki przykładu 1, w tabeli posortowanej według wymiaru Sales:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
Dane zastosowane w przykładach:
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');