
Apache Spark Batchジョブのデータサンプルにプレパレーションを適用
このシナリオは、ビッグデータ関連Talend製品にのみ適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントを参照してください。
tDataprepRunコンポーネントを使うと、Talend Data PreparationまたはTalend Cloud Data Preparationで作成した既存のプレパレーションをビッグデータジョブで直接再利用できます。つまり、プレパレーションを入力データに同じモデルで適用するプロセスの操作を実行できます。
以下のシナリオでは、次の操作を実行するシンプルなジョブを作成します。
- 顧客データの小さいサンプルを読み取る。
- 既存のプレパレーションをこのデータに適用する。
- 実行結果をコンソールで表示する。
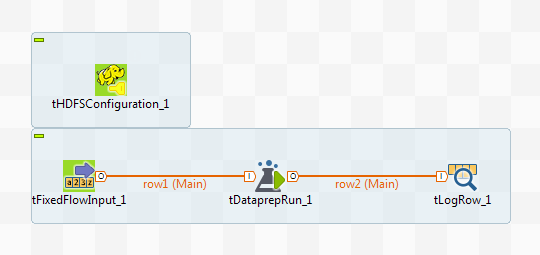
これらの操作を実行するには、ジョブの入力データと同じスキーマでデータセット上にプレパレーションを事前に作成しておく必要があります。ここでは、既存のプレパレーションはdatapreprun_sparkといいます。
このシンプルなプレパレーションにより、顧客の姓が大文字に変換され、カリフォルニア、テキサス、フロリダの顧客を分離するフィルターが適用されます。

1つの行またはセルにしか影響しない処理がプレパレーションに含まれている場合、ジョブの実行中、tDataprepRunコンポーネントによってこれらの処理はスキップされます。[Make as header] (ヘッダーとして作成)または[Delete Row] (行を削除)機能は、ビッグデータなどのコンテキストでは機能しません。
James;Butt;California
Daniel;Fox;Connecticut
Donna;Coleman;Alabama
Thomas;Webb;Illinois
William;Wells;Florida
Ann;Bradley;California
Sean;Wagner;Florida
Elizabeth;Hall;Minnesota
Kenneth;Jacobs;Florida
Kathleen;Crawford;Texas
Antonio;Reynolds;California
Pamela;Bailey;Texas
Patricia;Knight;Texas
Todd;Lane;New Jersey
Dorothy;Patterson;Virginia
tHDFSConfigurationはこのシナリオで、ジョブに依存するjarファイルの転送先となるHDFSシステムに接続するために、Sparkによって使用されます。
-
Yarnモード(YarnクライアントまたはYarnクラスター):
-
Google Dataprocを使用している場合、[Spark configuration] (Spark設定)タブの[Google Storage staging bucket] (Google Storageステージングバケット)フィールドにバケットを指定します。
-
HDInsightを使用している場合、[Spark configuration] (Spark設定)タブの[Windows Azure Storage configuration] (Windows Azure Storage設定)エリアでジョブのデプロイメントに使用するブロブを指定します。
- Altusを使用する場合は、[Spark configuration] (Spark設定)タブでジョブのデプロイにS3バケットまたはAzure Data Lake Storageを指定します。
- Quboleを使用する場合は、ジョブにtS3Configurationを追加し、QuboleでS3システム内に実際のビジネスデータを書き込みます。tS3Configurationを使用しないと、このビジネスデータはQubole HDFSシステムに書き込まれ、クラスターをシャットダウンすると破棄されます。
-
オンプレミスのディストリビューションを使用する場合は、クラスターで使われているファイルシステムに対応する設定コンポーネントを使用します。一般的に、このシステムはHDFSになるため、tHDFSConfigurationを使用します。
-
-
[Standalone mode] (スタンドアロンモード): クラスターで使われているファイルシステム(tHDFSConfiguration Apache Spark BatchやtS3Configuration Apache Spark Batchなど)に対応する設定コンポーネントを使用します。
ジョブ内に設定コンポーネントがない状態でDatabricksを使用している場合、ビジネスデータはDBFS (Databricks Filesystem)に直接書き込まれます。
前提条件: Sparkクラスターが適切にインストールされ、実行されていることをご確認ください。