
入力に従ってランタイムにプレパレーションを動的に選択する
このシナリオは、全Talend製品に適用されます。
Talendでサポートされているテクノロジーの詳細は、Talendコンポーネントをご覧ください。
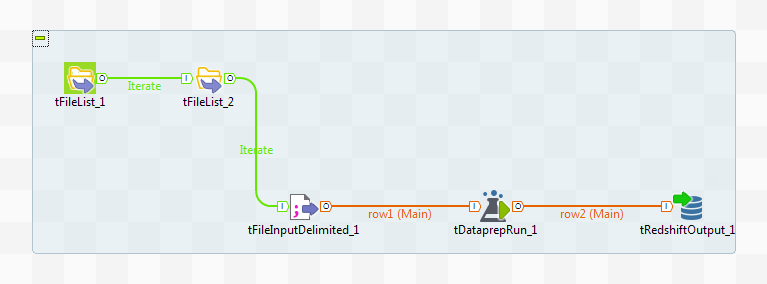
tDataprepRunコンポーネントを使うと、Talend Data Preparationで作成した既存のプレパレーションをデータ統合、Spark Batch、またはSpark Streamingのジョブで直接再利用できます。つまり、プレパレーションを入力データに同じモデルで適用するプロセスの操作を実行できます。
デフォルトでは、tDataprepRunコンポーネントは、テクニカルIDを使ってプレパレーションを取得します。ただし、動的プレパレーション選択機能を使うと、Talend Data Preparationのパスを介してプレパレーションを呼び出すことができます。[Dynamic preparation selection] (動的プレパレーションの選択)チェックボックスといくつかの変数を使うと、ランタイムデータまたはメタデータに応じて、ランタイムにプレパレーションを動的に選択できます。
通常のプレパレーション選択プロパティを使ってTalendジョブでプレパレーションの稼働準備を行う場合、実際にはいくつかジョブが必要になります: すなわち、特定のデータセットに適用するプレパレーションごとに1つのジョブです。入力ファイル名に従って正しいプレパレーションを取得することにより、1つのジョブでソースデータに対して複数のプレパレーションを動的に実行できます。
以下のシナリオでは、次の操作を実行するジョブを作成します。
- 複数のデータセットを含むフォルダーのコンテンツをスキャンする
- CSVファイルへの動的パスを作成する
- 入力ファイル名に従ってプレパレーションを動的に取得し、データに適用する
- プレパレーションを行ったデータをRedshiftデータベースに出力する
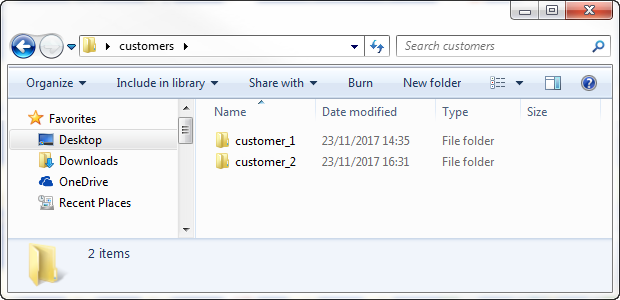
この例では、2つのクライアントからのデータを含む.csvデータセットが、customers_filesというフォルダーにローカルに保管されています。各クライアントデータセットには固有の命名規則があり、専用のサブフォルダーに保管されています。customers_filesフォルダーのすべてのデータセットは、スキーマまたはデータモデルが同一です。
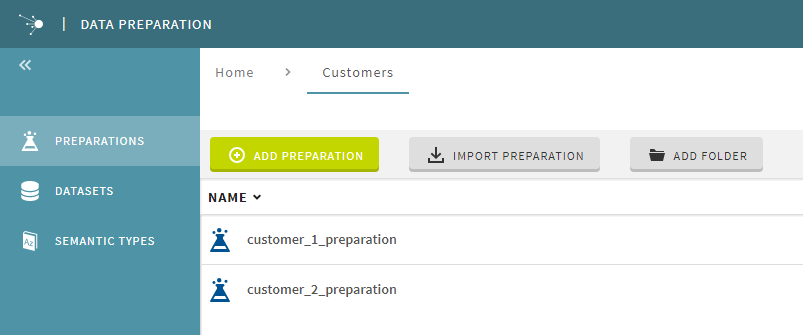
Talend Data Preparationには[customers] (顧客)フォルダーも作成され、ここには2つのプレパレーションが含まれています。これら2つの異なるプレパレーションは、それぞれ2人の異なる顧客からのデータを消去することを目的としています。
たとえば、customer_1_preparationの目的は特定タイプのメールアドレスを分離することで、customer_2_preparationの目的は無効な値を消去し、データをフォーマットすることです。この例では、プレパレーションの名前は、2つのサブフォルダー名customer_1とcustomer_2、およびサフィックス_preparationに基づいています。
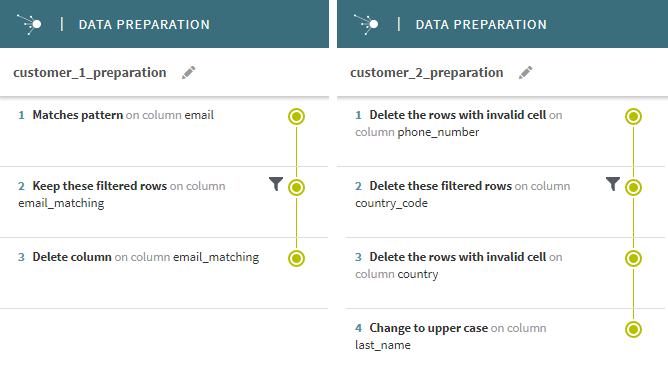
4つのデータセットすべてに共通する入力スキーマと同様に、すべての出力データも同じモデルを共有する必要があります。このため、カラムを追加するなどしてスキーマを変更するプレパレーション1つと、変更しないプレパレーションを用意することはできません。
このシナリオに従うと、ローカルのcustomers_filesフォルダーから抽出されたデータセットが顧客1と顧客2のどちらに属するかに応じて、単一のジョブで適切なプレパレーションを使うことができます。