
Amazon KinesisジョブとBig Data Streamingジョブを操作する
このシナリオはTalend Real-Time Big Data PlatformとTalend Data Fabricにのみ適用されます。
この例では、Talend Real-Time Big Data Platform v6.1に加え、Amazonにより提供される以下のライセンス製品を使います: Amazon EC2、Amazon Kinesis、Amazon EMR。
この例では、次のジョブを作成して、Amazon Kinesisストリームとの間でデータを読み書きし、結果をコンソールに表示します。
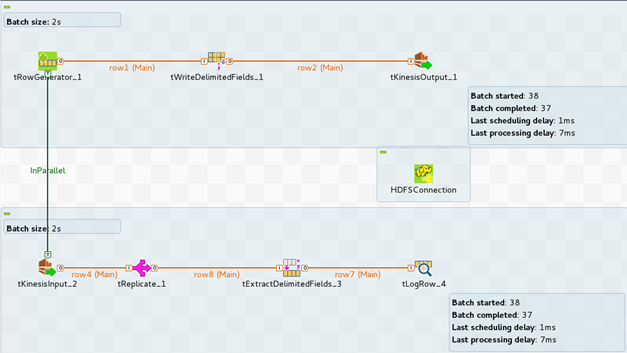
tHDFSConfigurationはこのシナリオで、ジョブに依存するjarファイルの転送先となるHDFSシステムに接続するために、Sparkによって使用されます。
-
Yarnモード(YarnクライアントまたはYarnクラスター):
-
Google Dataprocを使用している場合、[Spark configuration] (Spark設定)タブの[Google Storage staging bucket] (Google Storageステージングバケット)フィールドにバケットを指定します。
-
HDInsightを使用している場合、[Spark configuration] (Spark設定)タブの[Windows Azure Storage configuration] (Windows Azure Storage設定)エリアでジョブのデプロイメントに使用するブロブを指定します。
- Altusを使用する場合は、[Spark configuration] (Spark設定)タブでジョブのデプロイにS3バケットまたはAzure Data Lake Storageを指定します。
-
オンプレミスのディストリビューションを使用する場合は、クラスターで使われているファイルシステムに対応する設定コンポーネントを使用します。一般的に、このシステムはHDFSになるため、tHDFSConfigurationを使用します。
-
-
[Standalone mode] (スタンドアロンモード): クラスターで使われているファイルシステム(tHDFSConfiguration Apache Spark BatchやtS3Configuration Apache Spark Batchなど)に対応する設定コンポーネントを使用します。
ジョブ内に設定コンポーネントがない状態でDatabricksを使用している場合、ビジネスデータはDBFS (Databricks Filesystem)に直接書き込まれます。