
Spark Streamingフレームワークを使ってビッグデータストリーミングジョブを設定する
ジョブを実行する前に、Amazon EMRクラスターを使うようにジョブを設定する必要があります。
手順
-
ジョブはSparkで実行されるため、tHDFSConfigurationコンポーネントを追加し、リポジトリーからのHDFS接続メタデータを使うように設定する必要があります。
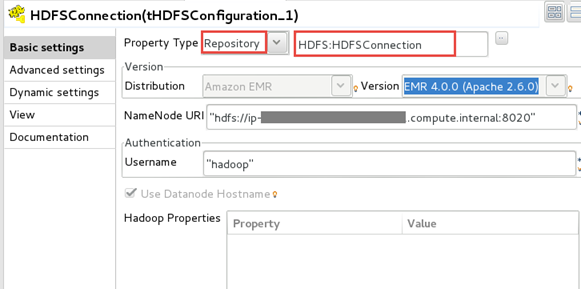
-
[Cluster Version] (クラスターバージョン)パネルで、クラスター接続メタデータを使うようにジョブを設定するために使われます。
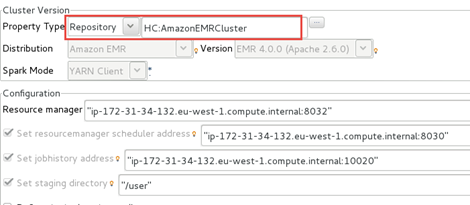
-
[Tuning] (調整)パネルで[Set tuning properties] (調整プロパティーの設定)オプションを選択し、フィールドを次のように設定します。

-
ジョブを実行します。
コンソールにデータが表示されるまで数分かかります。
