Talend Studioを使用する自然言語処理
Talend StudioおよびSparkの機械学習を使用することで、 人が自然言語をどのように学習し、使用するのかをコンピューターに教え、理解させることができます。
自然言語処理とは何か?
自然言語処理タスクは次のとおりです。
-
テキストのトークン化: テキストを単語や句読点などの基本単位に分割します。
-
センテンスの分割: ピリオドや疑問符などの終了文字に基づいて、入力をセンテンスに分割します。
-
ネームドエンティティ認識: テキスト内の人名、日付、 場所、および組織を検索し、分類します。
自然言語処理は次の処理に便利です。
自然言語処理は、テキスト内のユーザープロファイルとメンションの間、人と組織の間、または、再識別に使用されるその他の情報と人との間にリンクを作成するのに役立ちます。-
人名または会社名をテキストリソースから抽出する。
-
フォーラムディスカッションをトピック別にグルーピングする。
-
人名がメンションされているがディスカッションには参加していないディスカッションを検索する。
-
エンティティをリンクする。
ワークフロー
Sparkの機械学習は通常、次の2フェーズになっています: 最初のフェーズでは、履歴データと数学的なヒューリスティックをベースにモデルを計算します。2番目のフェーズでは、テキストデータにモデルを適用します。Talend Studioでは、最初のフェーズが2つのジョブによって実装されます。
-
最初のジョブはtNLPPreprocessingコンポーネントとtNormalizeコンポーネント。
-
2番目のジョブはtNLPModelコンポーネント。
他方、第2のフェーズはtNLPPredictコンポーネントを使用する第3のジョブによって実装されます。
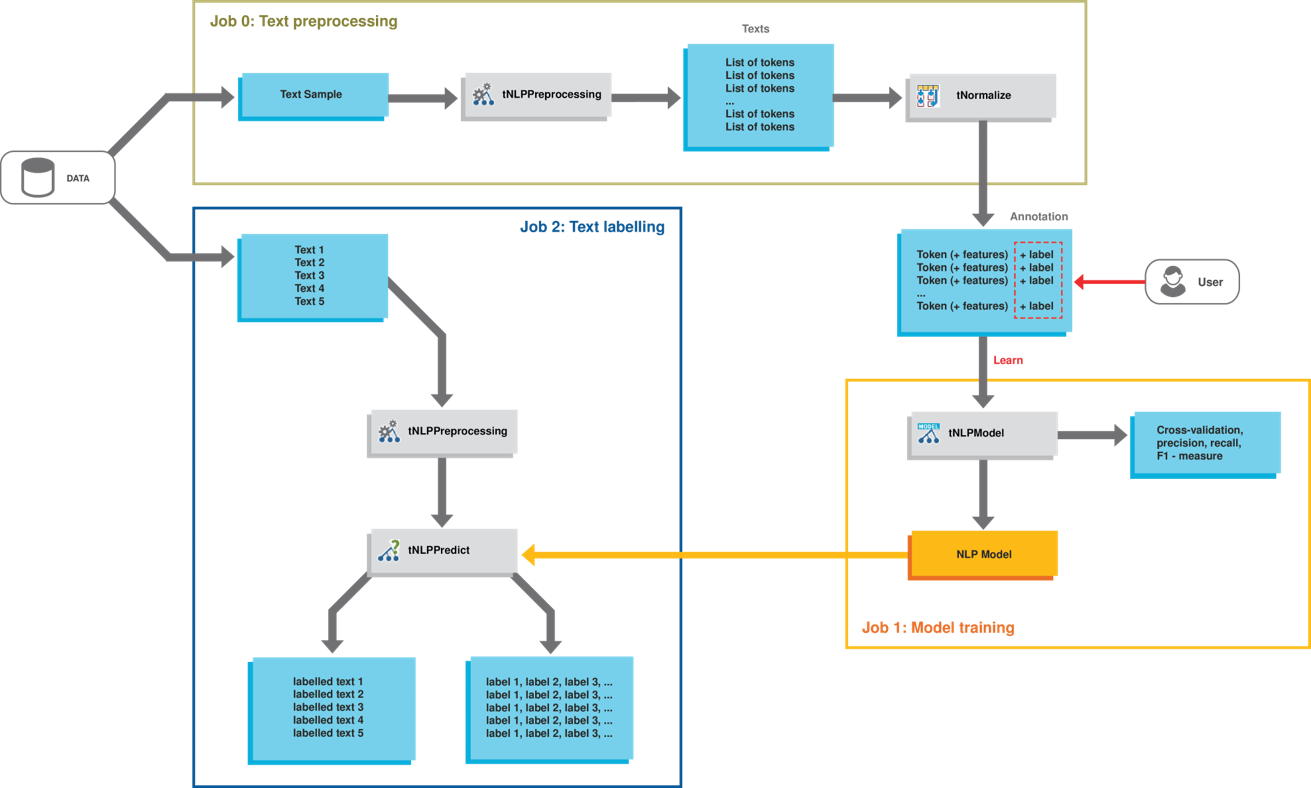
このワークフローでは、tNLPPreprocessingは次の処理を行います。
-
テキストサンプルをトークンに分割する。
-
HTMLタグをすべて削除して、テキストサンプルをクリーン化する。
次に、tNormalizeによってトークンがCoNLL形式に変換されます。
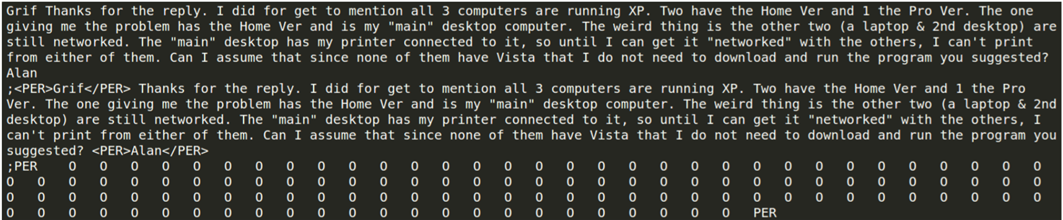
ここで、トークンに手動でラベル付けし、ファイルを編集してオプション機能を追加できます。たとえば、人名にPERのラベルを付けることができます:
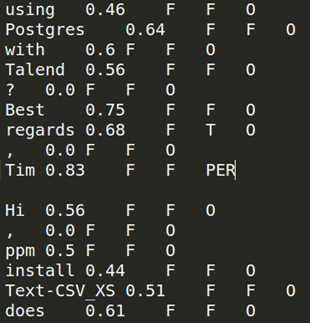
次に、2番目のジョブでtNLPModelを使用してラベル付けした、トークン化されたサンプルテキストを使用します。ここでは、tNLPModelを使用して以下のオペレーションを実行します。
-
各トークンに機能を生成する。
-
分類モデルのトレーニングを行う。
tNLPPredictは、tNLPModelによって生成された分類モデルを使用して、テキストデータに自動的にラベル付けします。
たとえば、<PER>ラベルの付いたネームドエンティティを抽出できます: