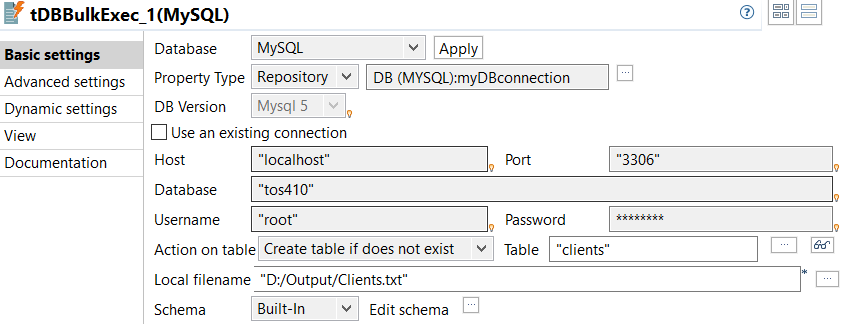
Configurer les composants
Procédure
-
Définissez le schéma des lignes à générer et la nature des données à générer. Dans cet exemple, le fichier clients à créer contient les colonnes suivantes : ID, First Name, Last name, Address, City qui sont toutes de type String, à l'exception de l'ID qui est de type Integer.
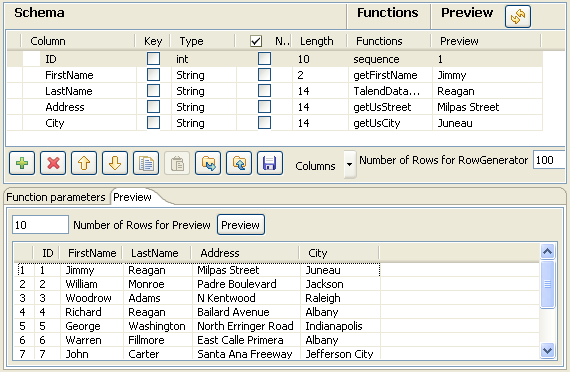 Certaines informations du schéma n'ont pas nécessairement besoin d'être affichées. Pour les dissimuler, cliquez sur le bouton Columns dans la barre d'outils et décochez les colonnes à cacher, par exemple : Precision ou Parameters.Utilisez le bouton [+] pour ajouter autant de colonnes que possible à votre schéma.Cliquez sur le bouton Refresh pour visualiser un aperçu des lignes générées en sortie.
Certaines informations du schéma n'ont pas nécessairement besoin d'être affichées. Pour les dissimuler, cliquez sur le bouton Columns dans la barre d'outils et décochez les colonnes à cacher, par exemple : Precision ou Parameters.Utilisez le bouton [+] pour ajouter autant de colonnes que possible à votre schéma.Cliquez sur le bouton Refresh pour visualiser un aperçu des lignes générées en sortie. -
Faites glisser toutes les colonnes de la table d'entrée (row1) vers la table de sortie (clients).
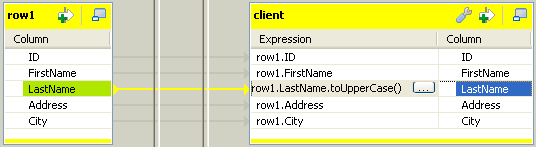
-
Paramétrez les informations de connexion de la base de données. Il est recommandé de stocker ce type d'informations dans le Repository, afin de pouvoir les récupérer à tout moment pour tout Job.