
Modélisation des zones à risques d'accident dans une ville
Ce scénario s'applique uniquement aux solutions Talend avec Big Data.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Dans ce scénario, le composant tKMeansModel est utilisé pour analyser un jeu de données géographiques concernant la destination d'ambulances dans une ville, afin de modéliser les zones comportant plus de risques d'accidents.
Un modèle comme celui-ci peut être employé pour permettre de déterminer le meilleur emplacement pour la construction d'hôpitaux.
Vous pouvez télécharger ces données d'exemple ici (uniquement en anglais). Elles sont constituées de paires de latitudes et longitudes.
Les données d'exemple ont été générées aléatoirement et automatiquement à des fins de démonstration uniquement et ne reflètent pas la situation réelle de ces zones.
-
La version de Spark à utiliser est au minimum la 1.4.
-
Les données d'exemples doivent être stockées dans votre système de fichiers Hadoop et vous devez avoir les droits en lecture sur ces données, au minimum.
-
Votre cluster Hadoop doit être correctement installé et être en cours de fonctionnement.
-
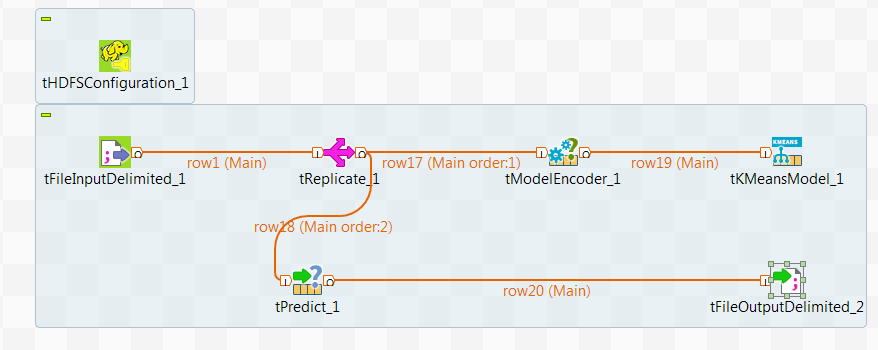
un tFileInputDelimited : qui charge les données d'exemple dans le flux de données du Job ;
-
un tReplicate : qui réplique les données d'exemple et met en cache la réplication ;
-
un tKMeansModel : qui analyse les données pour l'apprentissage du modèle et écrit le modèle dans HDFS ;
-
un tModelEncoder : qui pré-traite les données afin de préparer des vecteurs de caractéristiques à utiliser par le tKMeansModel ;
-
un tPredict : qui applique le modèle KMeans sur la réplication des données d'exemple. Lors d'une utilisation réelle, ces données doivent être un jeu de données de référence, afin de tester la précision du modèle ;
-
un tFileOutputDelimited : qui écrit le résultat de la prédiction dans HDFS.
-
tHDFSConfiguration : ce composant est utilisé par Spark pour se connecter au système HDFS dans lequel les fichiers Jar dépendant du Job sont transférés.
Dans l'onglet Spark Configuration de la vue Run, définissez la connexion à un cluster Spark donné pour le Job complet. De plus, puisque le Job attend ses fichiers .jar dépendants pour l'exécution, vous devez spécifier le répertoire du système de fichiers dans lequel ces fichiers .jar sont transférés afin que Spark puisse accéder à ces fichiers :-
Yarn mode (Yarn Client ou Yarn Cluster) :
-
Lorsque vous utilisez Google Dataproc, spécifiez un bucket dans le champ Google Storage staging bucket de l'onglet Spark configuration.
-
Lorsque vous utilisez HDInsight, spécifiez le blob à utiliser pour le déploiement du Job, dans la zone Windows Azure Storage configuration de l'onglet Spark configuration.
- Lorsque vous utilisez Altus, spécifiez le bucket S3 ou le stockage Azure Data Lake Storage (aperçu technique) pour le déploiement du Job, dans l'onglet Spark configuration.
- Lorsque vous utilisez Qubole, ajoutez tS3Configuration à votre Job pour écrire vos données métier dans le système S3 avec Qubole. Sans tS3Configuration, ces données métier sont écrites dans le système Qubole HDFS et détruites une fois que vous arrêtez votre cluster.
-
Lorsque vous utilisez des distributions sur site (on-premises), utilisez le composant de configuration correspondant au système de fichiers utilisé par votre cluster. Généralement, ce système est HDFS et vous devez utiliser le tHDFSConfiguration (en anglais).
-
-
Standalone mode : utilisez le composant de configuration correspondant au système de fichiers que votre cluster utilise, comme le tHDFSConfiguration Apache Spark Batch ou le tS3Configuration Apache Spark Batch (en anglais).
Si vous utilisez Databricks sans composant de configuration dans votre Job, vos données métier sont écrites directement dans DBFS (Databricks Filesystem).
-