Double-cliquez sur le composant tModelEncoder pour ouvrir sa vue Component.
Cliquez sur le bouton [...] à côté du champ Edit schema et, du côté du tModelEncoder, dans la fenêtre de schéma, définissez le schéma en ajoutant une colonne nommée map, de type Vector.
Cliquez sur OK pour valider ces modifications et acceptez la propagation proposée par la boîte de dialogue qui s'ouvre.
Dans la table Transformations, ajoutez une ligne en cliquant sur le bouton [+] et en procédant comme suit :
Dans la colonne Output column, sélectionnez la colonne contenant les caractéristiques. Dans ce scénario, la colonne est map.
Dans la colonne Transformation, sélectionnez l'algorithme à utiliser pour la transformation. Dans ce scénario, sélectionnez Vector assembler.
Dans la colonne Parameters, saisissez les paramètres à personnaliser pour utilisation dans l'algorithme Vector assembler. Dans ce scénario, saisissez inputCols=latitude,longitude.
Dans cette transformation, le tModelEncoder combine tous les vecteurs de caractéristiques en une seule colonne de caractéristiques.
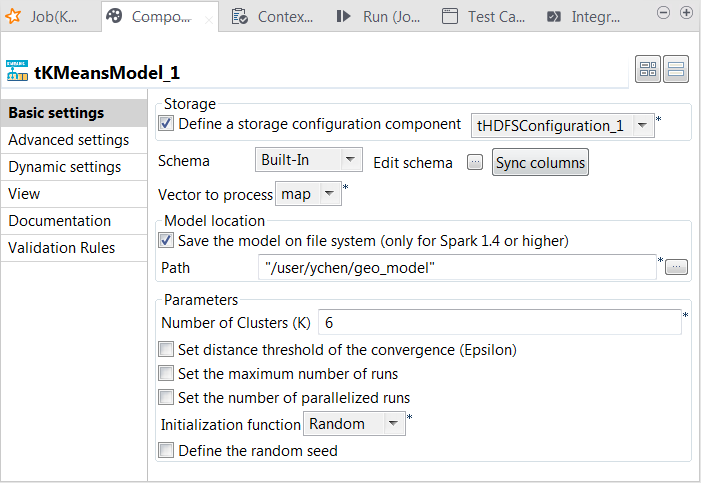
Double-cliquez sur le tKMeansModel pour ouvrir sa vue Component.
Cochez la case Define a storage configuration component et sélectionnez le composant tHDFSConfiguration à utiliser.
Dans la liste Vector to process, sélectionnez la colonne fournissant les vecteurs de caractéristiques à analyser. Dans ce scénario, sélectionnez map, qui combine toutes les caractéristiques.
Cochez la case Save the model on file system et, dans le champ HDFS folder qui s'affiche, saisissez le répertoire à utiliser pour stocker le modèle généré.
Dans le champ Number of cluster, saisissez le nombre d'arbres de décision que vous souhaitez que tKMeans construise. Vous devez essayer différents nombres pour exécuter le Job, afin de créer plusieurs fois le modèle de clustering. Après comparaison des résultats d'évaluation de chaque modèle créé à chaque exécution, vous pouvez décider du nombre à utiliser. Par exemple, saisissez 6.
Vous devez écrire vous-même le code d'évaluation.
Dans la liste Initialization function, sélectionnez Random. Généralement, ce mode est utilisé pour les jeux de données simples.
Laissez les autres paramètres tels qu'ils sont.
Cette page vous a-t-elle aidé ?
Si vous rencontrez des problèmes sur cette page ou dans son contenu – une faute de frappe, une étape manquante ou une erreur technique – faites-le-nous savoir.